Machine Learning: Konzepte, Methoden, Tools
Durch die verstärkte Internetnutzung und die Digitalisierung in der Industrie sind riesige Datenspeicher entstanden, die als Basis für lernende Systeme verwendet werden können. Der Bedarf, aus den schnelllebigen und (semi-) strukturierten Daten (Texte, Sprache, Bilder) sinnvolle Informationen zu extrahieren und Prognosen zu erstellen, hat zur Weiterentwicklung der Methoden, Sprachen und Frameworks für Maschinelles Lernen / Machine Learning geführt. Im Folgenden geben wir eine vereinfachte Übersicht über die wichtigsten Methoden und Tools des Machine Learning, sowie Hinweise über die Verwendung der elab2go-Demonstratoren, die diese veranschaulichen.
Motivation
Machine Learning erhält dank bahnbrechender Entwicklungen seit einigen Jahren viel Beachtung in Forschung, Lehre und Medien. Doch was steckt hinter dem Hype, inwieweit ist er gerechtfertigt?
Die Anwendungen des Machine Learning im Internet-Bereich (Suchmaschinen, Soziale Medien, Persönliche Assistenten) sind inzwischen etabliert, die industriellen Anwendungen (Predictive Maintenance, Fahrerassistenzsysteme) werden in vielen Unternehmen erforscht und getestet. Welche Einsatzmöglichkeiten für Maschinelles Lernen gibt es in der Industrie, wie aufwendig ist die Einführung, lohnt sich der Einsatz?
Um diese Fragen zu beantworten, ist ein grundlegendes Verständnis der Konzepte, Methoden und Tools des Maschinellen Lernens erforderlich, wie er hier in einer vereinfachten Zusammenfassung gegeben wird.
Machine Learning ist ein weites Feld, und um es als Experte zu beherrschen, ist ein entsprechendes Studium bzw. jahrelange Praxiserfahrung erforderlich. Die Grundidee "Machine Learning = Lernende Systeme" und der praktische Einsatz der verschiedenen Modelle sind jedoch auch für interessierte Laien nachvollziehbar, die sich dem Thema von der Anwendungsseite her nähern.

Übersicht
Der Übersichts-Artikel ist in fünf Abschnitte gegliedert, die jeweils auf weiterführende elab2go-Demos verweisen. Zunächst wird genauer untersucht, was man unter Machine Learning versteht, was die Ziele und Anwendungen sind, wie es sich historisch entwickelt hat und was der heutige Stand ist. Danach werden die Methoden und Algorithmen des Machine Learning angeführt, insbesondere die Unterscheidung Überwachtes / Unüberwachtes Lernen / Reinforcement Learning. Zuletzt werden die Sprachen und Frameworks erläutert, mit deren Hilfe man Machine Learning implementieren kann.
2 Ziele und Anwendungen
2-1 ML-Anwendung: Predictive Maintenance
2-2 ML-Anwendung: Assistenzsysteme
2-3 ML-Anwendung: Sicherheit
2-4 ML-Anwendung: Suchmaschinen
2-5 ML-Anwendung: Sprachmodelle4 Methoden und Algorithmen
4-1 Übersicht der Lernverfahren
4-2 Klassifikation
4-3 Clusteranalysen
4-4 Künstliche Neuronale Netzwerke
4-5 Deep Learning5 Sprachen und Frameworks für Maschinelles Lernen
5-1 Python
5-2 MATLAB
5-3 R und RStudio
1 Was ist Machine Learning?
Machine Learning ist ein Teilgebiet der Künstlichen Intelligenz, das es Systemen ermöglicht, auf Basis von Trainingsdaten automatisch zu lernen und hinzuzulernen. Machine Learning befasst sich mit der Entwicklung lernfähiger Systeme und Algorithmen, und verwendet dabei Konzepte und Methoden der Statistik und der Informationstheorie. Verwandte Disziplinen sind Pattern Recognition, die Erkennung bestehender Muster in Daten, mit Anwendungen in der Sprach- und Bilderkennung, und Data Mining, die Erkennung neuer Querverbindungen in großen Datenbeständen, mit Anwendungen in Datenbanksystemen, speziell Big Data. Machine Learning bietet eine vereinheitlichte allgemeine Beschreibung existierender Lernverfahren, zu denen unter anderem Entscheidungsbaum-Lernen, Lernen mit Hilfe Künstlicher Neuronaler Netzwerke oder Bayessches Lernen gehören.
Eine formale Definition des Machine Learning lautet: "Eine Maschine lernt aus der Erfahrung E hinsichtlich einer Klasse von Aufgaben T und dem Performance-Maß P, falls die Performance P hinsichtlich T mit E sich verbessert." [Tom Mitchell, Machine Learning, 1997]
Deep Learning ist ein eigenständiges Forschungsgebiet des Machine Learning, das sich mit komplexen Algorithmen beschäftigt, und zwar neuronale Netzwerke mit sehr vielen verdeckten Schichten (R-CNN, LSTM), die aus den Daten auch die relevanten Merkmale lernen können, durch diesen Aufbau der Funktionsweise des menschlichen Gehirns ähnlicher sind und dadurch Probleme wie z.B. in der Objekterkennung und Textbearbeitung lösen können, die vormals unlösbar waren.
2 Ziele und Anwendungen
Machine Learning-Modelle und Algorithmen haben im weitesten Sinne das Ziel, aus Input-Daten sinnvolle Zusammenhänge und Muster zu erkennen und daraus Regeln abzuleiten. Z.B. Vorhersagen treffen, Trends erkennen, Daten nach bestimmten Kriterien gruppieren. Im Unterschied zu herkömmlichen Modellen der Datenanalyse handelt es sich beim Machine Learning um lernende Systeme. Dies hat den Vorteil, dass sie auch ohne erneutes Eingreifen des Menschen korrekte Ergebnisse liefern können.
Machine Learning-Verfahren sind demnach überall dort einsetzbar, wo regelmäßig Daten erfasst werden, deren Auswertung es ermöglicht, Produktion- und Geschäftsabläufe zu optimieren. Die erfassten Daten können Texte, Protokolldateien, Bilder, Sprach- oder Videoaufzeichnungen sein.
Verbreitete Anwendungen des Machine Learning sind finden sich z.B. in Predictive Maintenance-Lösungen, in Produkten für Sicherheit und Überwachung, in Assistenzsystemen und in Suchmaschinen.
2-1 ML-Anwendung: Predictive Maintenance
Machine Learning-Verfahren haben ein breites Anwendungsfeld im Bereich der Predictive Maintenance bzw. vorausschauenden Wartung.
Predictive Maintenance wird in der Industrie eingesetzt, um mögliche Ausfälle rechtzeitig zu erkennen
und den Austausch von Komponenten und Anlagen zu veranlassen.
Voraussetzung ist die Ausstattung der Anlagen mit einem Netzwerk aus Sensoren, die den Zustand des Systems
(Vibrationen, Temperatur, Feuchtigkeit) zu definierten Zeitpunkten erfassen und wegsichern.
Die erfassten Sensordaten sind die Datenbasis, die es auszuwerten gilt.
Moderne Predictive Maintenance-Lösungen können die Auswertung in Echtzeit direkt am System durchführen,
ein anderer Weg ist die Datenübertragung und Auswertung in der Cloud.
Bei der Predictive Maintenance können unterschiedliche Machine Learning-Verfahren kombiniert werden:
einerseits ist eine Klassifikation von Ausfällen (Ausfall ja / nein) möglich,
andererseits kann aus Vergangenheitsdaten eine Prognose der Entwicklung von Sensordaten erstellt werden,
und schließlich können Clusteranalysen dabei helfen, typische Fehlerursachen aus unbewerteten Vergangenheitsdaten herauszufinden.
Der Übersichtsartikel Was ist Predictive Maintenance? erläutert die grundlegenden Konzepte und Basistechnologien der Predictive Maintenance, stellt die Anwendungsbereiche in der Praxis und die Predictive Maintenance-Lösungen einiger Global Player auf dem Markt vor.
2-2 ML-Anwendung: Assistenzsysteme
Assistenzsysteme im weitesten Sinne unterstützen Menschen dabei, bestimmte Aktivitäten auszuführen oder Geräte zu bedienen. Unter Assistenzsysteme fallen z.B. Fahrerassistenzsysteme, medizinische Assistenzsysteme, oder Call-Center-Lösungen, bei denen ein Automat ("Chatbot") anstelle von einem Menschen Auskunft erteilt.
Fahrerassistenzsysteme in autonomen oder teil-autonomen Fahrzeugen benötigen einerseits Komponenten, die Hindernisse auf der Fahrbahn erkennen, und anderereits Komponenten, die bei Unaufmerksamkeit des Fahrers entsprechende Signale geben oder sogar Maßnahmen ergreifen. In Fahrerassistenzsystemen werden Verfahren für Objekterkennung eingesetzt, und es gibt eine Vielzahl von Bibliotheken, die die Schritte des Deep Learning-Prozesses (die "Pipeline") unterstützen, angefangen von der Datenaufbereitung über das Trainieren und Feintunen des Modells.
2-3 ML-Anwendung: Sicherheit
Machine Learning-Verfahren haben ein weiteres Anwendungsfeld im Bereich der Sicherheit und Überwachung. Einerseits kommen sie in IT-Sicherheit-Produkten zum Einsatz, wo sie in Endpoint-Protection und Firewalls eingebaut sind, und andererseits in Systemen, die der physischen Sicherheit dienen, speziell Video-Überwachung.
Endpoint-Protection
Unter Endpoint-Protection versteht man Sicherheitslösungen (z.B. Virenscanner) für Endgeräte wie Anwender-PCs, Laptops, und Smartphones.
Bei der Sicherheitsüberwachung eines Endgeräts werden Zugriffe protokolliert (IP-Adressen, Programme, Ports), diese bilden die Datenbasis.
Machine Learning-Komponenten für Endpoint-Protection können auf Basis von Vergangenheitsdaten hinzulernen
und neue Bedrohungen richtig klassifizieren, und sind auch ohne Vergangenheitsdaten fähig, in Echtzeit Anomalien zu erkennen.
Videoüberwachung
Die Auswertung von Aufzeichnungen aus Videoüberwachung ist eine für Menschen zeitaufwendige Aufgabe.
Mittels Machine Learning-Verfahren können Anomalien in Echtzeit erkannt und Alarme ausgelöst werden.
2-4 ML-Anwendung: Suchmaschinen
Eines der großen Anwendungsfelder des Machine Learning ist die Optimierung von Suchmaschinen. Suchmaschinen sind für viele das Tor zum Internet, wo wir unser Anliegen eingeben und erwarten, an die passenden Räume verwiesen zu werden, bzw. auch schon erste Antworten auf einfache Fragen zu erhalten. Die Suchbegriffe sind oft ungenau, Stichwörter, halbe Sätze, Tippfehler, und die Suchmaschine muss daraus den erwarteten Zusammenhang herstellen und die passenden relevanten Suchergebnisse liefern. So arbeiten moderne Webcrawler mit Machine Learning-Komponenten sowohl bei der Text- als auch bei der Bildsuche.
Beispiel: Bildsuche
Die Bildsuche nach einem Begriff wie "Karohemd blau-weiss unter 50€ " sollte Bilder mit blau-weissen Karohemden für Herren zurückliefern,
die weniger als 50€ kosten.
Was passiert bei der Bildsuche nun auf Seiten der Suchmaschine?
Das Bild bzw. die Webseite des Bildes muss zunächst von einem Webcrawler erfasst worden sein.
Die Suchmaschine berücksichtigt beim Crawlen von Bildern den Dateinamen und den mit dem Bild verknüpften Text,
und führt eine Objekterkennung durch, bei denen aus einem Bild relevante Merkmale "Hemd", "Karos", "blau", "weiss" extrahiert
werden. Diese Informationen, die einerseits aus der Textbeschreibung und andererseits aus dem Bild selber stammen,
werden in den Index-Datenbanken der Suchmaschine gespeichert.
Bei der eigentlichen Suche wird der Suchbegriff mit dem Index der Suchmaschine abgeglichen, dort sind zu dem Suchbegriff schon affine Stichwörter mit den gerankten passenden URLs gespeichert. Durch den Einsatz eines Webcrawler mit Machine Learning können später bei der Suche auch passende Bilder gefunden werden, deren Namen nur indirekt mit dem Suchbegriff zusammenhängt, und bei denen zusätzliche Informationen wie z.B. in unserem Beispiel der Preis nur aus dem Kontext ersichtlich sind.
Weiterhin verwendet der Webcrawler Deep Learning-Verfahren für Objekterkennung, um die Inhalte von Bildern zu durchsuchen und relevante Merkmale zu extrahieren.
Machine Learning-Verfahren haben im Internet sowie in Medien und Kommunikation eine Vielzahl weiterer Anwendungen. Sie werden eingesetzt in der Textbearbeitung, um Grammatik zu korrigieren oder neue Texte zu generieren. Sie werden eingesetzt in der Bildbearbeitung, um z.B. historische Bilder und Videos neu einzufärben und aufzuwerten. Sie werden eingesetzt in Chatbots, eine Art virtueller Assistenten, bei denen der Mensch in natürlicher Sprache mit dem System kommunizieren kann.
2-5 ML-Anwendung: Sprachmodelle
Machine Learning-Anwendungen, die aktuell viel Beachtung erhalten, sind Sprachmodelle "Large Language Models (LLM)" die für Text-Extraktion, Text-Generierung und Frage-Antwort-Systeme eingesetzt werden, z.B. im Rahmen eines Chatbots.
Eine bekannte LLM-Anwendung ist der Chatbot ChatGPT des Forschungsunternehmens OpenAI, eine Showcase-Plattform für Anwendungen des Maschinellen Lernens, insbesondere im Bereich Natural Language Processing. In ChatGPT kann der Benutzer nach Anmeldung über Texteingabe mit dem Chatbot kommunizieren und ihn diverse Aufgaben ausführen lassen. Es werden eine Reihe beispielhafter Anwendungsfälle angeboten, z.B. die Grammatik-Korrektur eines ganzen Satzes, das Erstellen einer Kurzzusammenfassung für einen Text, Unterstützung bei der Lösung von Programmierproblemen, das Erzeugen von Python-Programmcode oder -Funktionen auf Basis einer natürlichsprachlichen Beschreibung.
Weitere Machine Learning-Anwendungen im Bereich der Textbearbeitung sind die Sprachmodelle des Forschungsunternehmens Llama (Inhaber: Facebook / Meta / Microsoft) die mit Hilfe einer API in eigene Anwendungen eingebettet werden können.
3 Historische Entwicklung
Maschinelles Lernen hat seit seinen Anfängen um 1950, als die ersten künstlichen neuronalen Netzwerke entwickelt wurden, mehrere Auf-und-ab-Phasen erlebt. Klassisches datenzentrisches Maschinelles Lernen ist seit 1990 eine Disziplin der Datenanalysten und Statistiker. Seit ca. 2010 hat Deep Learning die Forschung beflügelt und zu einem neuen Hype geführt. Heute wird Angewandtes Maschinelles Lernen verstärkt auch von Informatikern und Ingenieuren betrieben. Meilensteine der letzten Jahre sind:
- 1997 Tom Mitchell's Lehrbuch, Machine Learning wird bei McGraw Hill veröffentlicht.
- 1997 LSTM-Netzwerke ermöglichen das Verwenden von Künstlichen Neuronalen Netzwerken mit vielen versteckten Schichten und damit Deep Learning, mit Anwendungen in Text- und Spracherkennung.
- 2005 Yann LeCun, Yoshua Bengio, Geoffrey Hinton veröffentlichen in Nature ihren Review-Artikel über Deep Learning.
- 2010 Kaggle, eine Google-Plattform für Datenanalysten, geht online.
- 2012 Google Brain-Forschung kann mit Hilfe eines neuronalen Netzwerkes Katzen in YouTube-Videos identifizieren. Danach wird die Forschung ausgeweitet auf: Spracherkennung, Fotosuche, YouTube-Videoempfehlungen, Robotik
- 2014 Facebook DeepFace kann Gesichter in Fotos mit derselben Genauigkeit wie Menschen identifizieren.
- 2022 ChatGPT wird in einer ersten Version veröffentlicht.
4 Methoden und Algorithmen
Die Methoden und Algorithmen des Maschinellen Lernens können, wie unten abgebildet, nach Art des Lernens grob in zwei Kategorien, "Überwachtes Lernen" und "Unüberwachtes Lernen" eingeteilt werden (weitere Varianten sind bestärkendes Lernen, semi-überwachtes Lernen etc.), sowie nach Funktionsweise bzw. Art der Modellbildung in:
- Klassifikationsprobleme, die die Gruppenzugehörigkeit einer Beobachtung vorhersagen.
Beispiel: Vorausschauende Wartung (Predictive Maintenance): Tritt für eine gegebene Beobachtung (d.h. Kombination von Merkmalen, die Sensormessungen darstellen) ein Ausfall der Maschine ein oder nicht? - Regressionsprobleme, die numerische Werte vorhersagen.
Beispiel: Zeitreihenanalyse im Rahmen der Vorausschauenden Wartung: Prognose der Werte eines bestimmten Merkmals (z.B. Druck), für den nächsten Tag, falls die Werte dieses Merkmals für jeden Tage des letzten Monats (oder das letzte Jahr) bekannt sind. - Clustering-Probleme, die innerhalb einer Menge von Daten Gruppen ähnlicher Beobachtungen finden. Gruppen ähnlicher Beobachtungen werden durch die Verwendung eines bestimmten Ähnlichkeits- bzw. Abstandsmaßes gebildet. Neue Daten können anhand ihrer Merkmale dann den Clustern zugeordnet werden.
Die Abbildung "Methoden des Maschinellen Lernens" zeigt eine Übersicht der wichtigsten Methoden, gruppiert nach Art des Lernverfahrens.
4-1 Übersicht der Lernverfahren
Man unterscheidet beim Maschinellen Lernen zwischen verschiedenen Lernverfahren: überwachtes Lernen, unüberwachtes Lernen, bestärkendes Lernen, die jeweils unterschiedliche Abläufe und Anwendungen haben.
Beim überwachten Lernen (supervised learning) liegt für jeden Datensatz der Input-Daten eine Bewertung vor, d.h. die Daten sind schon in Kategorien bzw. Klassen unterteilt. Der Ablauf ist wie folgt: Die Input-Daten werden in Trainingsdaten und Testdaten unterteilt. Auf Basis der Trainingsdaten wird mittels eines passenden Algorithmus ein Vorhersagemodell, z.B. ein Entscheidungsbaum oder Neuronales Netzwerk erstellt, dessen Güte mit Hilfe von Performance-Kennzahlen (Kreuzvalidierung; Vertrauenswahrscheinlichkeit, Genauigkeit, Trefferquote) ermittelt wird. Der Trainingsprozess wird solange wiederholt, bis das Modell eine gewünschte Performance erreicht. Danach kann es für die Vorhersage / Klassifikation auf neuen Datensätzen verwendet werden.
Überwachtes Lernen wird in der Industrie im Rahmen der Predictive Maintenance eingesetzt, um Ausfälle "vorherzusagen" und rechtzeitig Wartungsfenster einzuplanen. Die eingesetzten Verfahren (Entscheidungsbäume, Random Forests, Künstliche Neuronale Netzwerke) sind gut erforscht, die Herausforderung besteht hier in der Datenerfassung und Datenvorbereitung, sowie der Echtzeit-Auswertung mit eingeschränkten Ressourcen am Gerät.
Beim unüberwachten Lernen (unsupervised learning) liegen für die Input-Daten keine Bewertungen vor, d.h. das Lernverfahren muss ein Modell ohne Zielvorgaben erstellen, indem es Muster in den Daten erkennt. Ein anschauliches Beispiel sind Clusteranalysen, ein Verfahren, mit dessen Hilfe man in einem Datensatz Gruppen ähnlicher Beobachtungen ("Cluster") identifizieren kann. Die Clusterbildung kann mit unterschiedlichen Algorithmen umgesetzt werden. Zwei der verbreitetsten Verfahren sind K-Means-Clustering und hierarchisches Clustering.
Clusteranalysen können in der Industrie ebenfalls im Rahmen der Vorausschauenden Wartung verwendet werden, um Daten, für die keine Bewertungen vorliegen, vorab statistisch zu analysieren.
Beim bestärkenden Lernen (reinforcement learning) werden intelligente Agenten eingesetzt, die mit ihrer Umgebung interagieren und Strategien erlernen, um erhaltene Belohnungen zu maximieren. Die mathematischen Grundlagen des Reinforcement Learning sind Markovsche Entscheidungsprozesse, mit deren Hilfe man Entscheidungsfindung unter zufälligen Randbedingungen modellieren kann. Ein Markovscher Entscheidungsprozess besteht aus einer Menge von Zuständen S, in denen sich der Agent befinden kann, und einer Menge von Aktionen A, die ein Agent durchführen kann, indem er von einem Zustand in einen anderen wechselt. Weiterhin wird jedem Zustandübergang aus einem Zustand s1 in einen Zustand s2 mittels einer Aktion a12 eine Übergangswahrscheinlichkeit p12 und eine Belohnung r12 zugeordnet. Eine Startverteilung gibt für jeden Zustand an, wie wahrscheinlich es ist, in diesem Zustand zu starten. Das Ziel des Reinforcement Learning ist, eine optimale Strategie zu finden, formal ausgedrückt: eine Funktion, die für jeden Zustand die auszuführende Aktion angibt, so dass eine globale Belohnungsfunktion maximiert wird.
Reinforcement Learning wird dann angewendet, wenn ein System nur durch Interaktion mit seiner Umgebung lernen kann. Eine verbreitete Anwendung des Reinforcement Learning ist die Bewegung eines Roboters zu einem Ziel. Hier ist die Menge der Zustände die Menge der Positionen und die Aktionen sind mögliche Richtungen, in die sich der Roboter bewegen kann. Weitere Anwendungen sind in der Prozessautomatisierung bei der Optimierung der Parametrisierung von Controllern, oder robotergestützte Dialogsysteme. Wichtig: Bestärkendes Lernen benötigt keine Bewertung der Input-Daten wie das überwachte Lernen.
4-2 Klassifikation
Klassifikation ist eine Verfahren, bei dem die Daten auf Basis eines Merkmals in unterschiedliche Kategorien eingeteilt werden.
Z.B. werden E-Mails eingeteilt in "Spam" oder "Kein Spam", Webseiten werden eingeteilt in "Relevant" oder "Nicht relevant".
Klassifikation kann auf verschiedene Arten durchgeführt werden: Naive Bayes, Entscheidungsbaum oder Support Vector Machines.
Der Entscheidungsbaum ist ein intuitiv nutzbares Klassifikationsmodell, das für den Einstieg besonders geeignet ist,
da es eine Visualisierung der Klassifikation bzw. der hierarchisch aufeinanderfolgenden Entscheidungen ermöglicht.
Ein Entscheidungsbaum besteht aus einer Wurzel, Kindknoten und Blättern, wobei jeder Knoten eine Entscheidungsregel
und jedes Blatt eine Antwort auf die Fragestellung darstellt.
Um eine Klassifikation eines einzelnen Datenobjektes abzulesen, geht man vom Wurzelknoten entlang des Baumes abwärts.
Bei jedem Knoten wird ein Merkmal abgefragt und eine Entscheidung über die Auswahl des folgenden Knoten getroffen.
Dies wird so lange fortgesetzt, bis man ein Blatt erreicht. Das Blatt entspricht der Klassifikation.
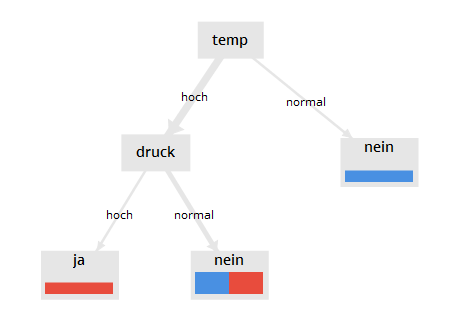
Beispiel: Entscheidungsbaum
Der Entscheidungsbaum für unser Mini-Beispiel gibt z.B. eine Antwort auf die Frage, bei welcher Kombination von Werten für die Merkmale temp und druck das Gerät ausfallen wird.
Interpretation
Als Eingabe benötigt der Baum eine Beobachtung, d.h. eine Kombination von Merkmalen, z.B. {temp=hoch, druck=hoch}.
Wir fangen bei der Wurzel an und wenden die Regeln des Baumes an, wobei an jedem Knoten ein Attribut des Baumes abgefragt wird. Erste Frage: ist temp hoch oder normal? temp ist hoch, also gehen wir nach links. Zweite Frage: Ist druck hoch oder normal? druck ist hoch also gehen wir nach links. Hier haben wir die Eingabe abgearbeitet und sind an einem Blatt angekommen. Die Antwort lautet: ja, d.h. bei dieser Eingabe tritt ein Ausfall ein.
Mehr zu Entscheidungsbäumen: Demo2 ... Demo-PY4
Wir verwenden als Anwendungsfall für die Klassifikation mit Hilfe eines Entscheidungsbaum-Modells einen Automobildatensatz, der in allen Demos des Predictive Maintenance-Zyklus verwendet wird: eine csv-Datei automotive_data.csv mit 136 Beobachtungen. Jede Beobachtung bzw. Zeile hat insgesamt 24 Spalten, von denen 22 Spalten Sensorwerte enthalten und die Merkmale der Datenanalyse darstellen. Zielvariable ist die Spalte "Ausfall". Die Fragestellung lautet: "Bei welcher Kombination von Merkmalen tritt ein Ausfall ein?". Dies entspricht einem Klassifikationsproblem mit zwei Klassen, nämlich der Klasse "Ausfall=ja" und der Klasse "Ausfall=nein".
Die Ausfall-Prognose für den Automotive-Datensatz mit Hilfe des Entscheidungsbaum-Verfahrens wird mit Hilfe verschiedener Sprachen und Tools veranschaulicht:
- Demo3 "Predictive Maintenace mit R"
zeigt den Einsatz der statistischen Programmiersprache R. - Demo4 "Interaktive PredMaintApp"
zeigt den Aufbau und die Verwendung einer interaktiven Shiny-App. - Demo-PY4 "Predictive Maintenance mit scikit-learn"
beschreibt die Datenanalyse mit Hilfe der Python-Bibliothek scikit-learn in einem Juypter Notebook.
4-3 Clusteranalysen
Eine Clusteranalyse ist ein Verfahren des maschinellen Lernens,
mit dessen Hilfe man in einem Datensatz Gruppen ähnlicher Beobachtungen ("Cluster") identifizieren kann.
Die Clusterbildung kann mit unterschiedlichen Algorithmen umgesetzt werden.
Zwei der bekanntesten Verfahren sind K-Means-Clustering und hierarchisches Clustering.
Beispiel: Clusteranalyse
Die Clusteranalyse aus unserem Mini-Beispiel beantwortet die Frage, ob gewisse Kombinationen aus Temperatur und Luftfeuchtigkeit unterschiedlichen Clustern wie z.B. "behaglich", "zu trocken" oder "zu feucht" zugeordnet werden können.

Interpretation
Der Raumklima-Datensatz enthält 15 Beobachtungen / Messungen zur Temperatur (in Grad Celsius) und der Luftfeuchtigkeit (in %). Je nach Kombination aus Temperatur und Luftfeuchtigkeit wird das Raumklima als "behaglich", "zu trocken" oder "zu feucht" empfunden.
Die Anzahl der möglichen Cluster (hier: 3) kann mit Hilfe eines Streudiagramms herausgefunden und visualisiert werden. Mit Hilfe des K-Means-Clustering werden die Zentren der Cluster und die Zuordnungen der einzelnen Beobachtungen zu den Clustern herausgefunden. Die Beobachtung Feuchte = 21, Temperatur = 13 liegt z.B. im Cluster "zu trocken" mit Zentrum (25, 15).
Mehr zu Clusteranalysen: Demo-PY3
Demo-PY3 zeigt, wie eine Clusteranalyse mit Hilfe der Python-Bibliothek scikit-learn für maschinelles Lernen durchgeführt wird. Ein Datensatz zum Raumklima in Abhängigkeit von Luftfeuchtigkeit und Temperatur dient dabei als Anwendungsbeispiel. Die Daten werden in der interaktiven, webbasierten Anwendungsumgebung Jupyter Notebook analysiert. Im letzten Schritt erfolgt die Datenvisualisierung und die Zuordnung zu den Clustern mit Hilfe der Bibliothek Matplotlib.
4-4 Künstliche Neuronale Netzwerke
Künstliche Neuronale Netze sind Machine Learning-Algorithmen bzw. Systeme, die den neuronalen Prozessen
des Gehirns nachempfunden sind und für Klassifikations-, Prognose- und Optimierungsaufgaben verwendet werden.
Ein Künstliches Neuronales Netz besteht aus Neuronen, d.h. Knoten bzw. Verarbeitungseinheiten,
die durch gerichtete und gewichtete Kanten verbunden und in Schichten
angeordnet sind (Eingabeschicht, versteckte Schichten und Ausgabeschicht).
Eine Kante von Neuron i zu Neuron j hat das Gewicht wi,j, das die Stärke der Verbindung zwischen den Neuronen angibt.
Die Eingabedaten werden innerhalb des Netzes von den Neuronen über Aktivierungsfunktionen verarbeitet und
das Ergebnis wird bei Überschreiten eines Schwellwertes an die Neuronen der nächsten Schicht weitergegeben.
Die Eingangsgrößen und die Gewichte einer Schicht werden als Matrizen dargestellt. Die Berechnung der Ausgangsgröße
eines Neurons ist die Anwendung der Aktivierungsfunktion F auf das Produkt der Eingangsgrößen-Matrix
mit der Gewichts-Matrix Y = F(X · W).
Der Aufbau bzw. die Topologie eines künstlichen neuronalen Netzes werden bestimmt durch die Anzahl der Schichten, durch die Richtung, in der das Netz durchlaufen werden kann, durch die Anzahl der Neuronen in jeder Schicht, und durch die verwendeten Aktivierungsfunktionen.
Beispiel: Feedforward-Netz für Ziffernerkennung
Das abgebildete neuronale Netz ist ein Feedforward-Netz mit drei Schichten, das häufig in Lehre und Forschung als erstes Beispiel zum Erlernen und Testen von künstlichen neuronalen Netzwerken verwendet wird. Mit Hilfe dieses neuronalen Netzes können Probleme aus dem Bereich der Bilderkennung (Ziffernerkennung in handgeschriebenen Texten) gelöst werden. Es ist in der Lage, aus Grauton-Bildern der Größe 28x28 Pixel, die handschriftliche Ziffern darstellen, die korrekte Ziffer zu erkennen.

Interpretation
Ein Bild der Größe 28x28 Pixel wird durch insgesamt 784 Pixel beschrieben. Die 784 Pixel bzw. ihre Grautöne (angegeben durch einen Wert zwischen 0=schwarz und 255=weiß) bilden die Eingangswerte des künstlichen neuronalen Netzes. Die Anzahl der Ausgangsknoten ist gleich der Anzahl der möglichen Ziffern von 0 bis 9, also 10. Das neuronale Netz löst ein Klassifikationsproblem, nämlich die Zuordnung der Eingabe zu einer der Klassen 0, 1, 2, ... oder 9.
Als Trainingsdaten werden die ca. 60.000 Bilder der MNIST-Datenbank verwendet, die man in Frameworks wie Keras und Tensorflow auch direkt laden kann.
4-5 Deep Learning
Bei dem Einsatz Künstlicher Neuronale Netzwerke für die Klassifikation von Objekten tritt zunächst das Problem auf, dass die Input-Daten klar definierte Merkmale besitzen müssen, um als Eingabe für das Modell nutzbar zu sein. Diese manuelle Merkmalsextraktion bedeutet bei großen Datenmengen einen erheblichen Aufwand bei der Datenvorbereitung. Für einen praktischen Einsatz wurden Verfahren entwickelt, die die Merkmalsextraktion mit lernen, diese benötigen sehr viele versteckte Schichten (daher "tiefe" Netze), die in der Lage sind, ihre Parameter zu aktualisieren, und zwar durch eine Kopplung der Ausgabe einer Schicht in andere Schichten.
Deep Learning ermöglicht die Erstellung von Modellen mit sehr vielen versteckten Schichten, mit einer eingebauten Merkmalsextraktion, und der Fähigkeit, komplexe Strukturen in großen Datensätzen entdecken zu können.
Objekterkennung mittels Deep Learning
Objekterkennung ist eine Teilaufgabe verschiedener Anwendungen (Videoüberwachung, Unaufmerksamkeitserkennung beim Fahren, …) und muss oft in Echtzeit durchgeführt werden. Für die Verarbeitung von Bildern und Videos werden tiefe faltende Netze (ConvNets, Deep Convolutional Nets) eingesetzt.
Aufbau eines Convolutional Network
Die Abbildung aus dem MATLAB-EBook "Deep Learning" [7] zeigt ein faltendes Netz für Objekterkennung mit Merkmalsextraktion und Klassifikation,
mit verschiedenen Schichten.
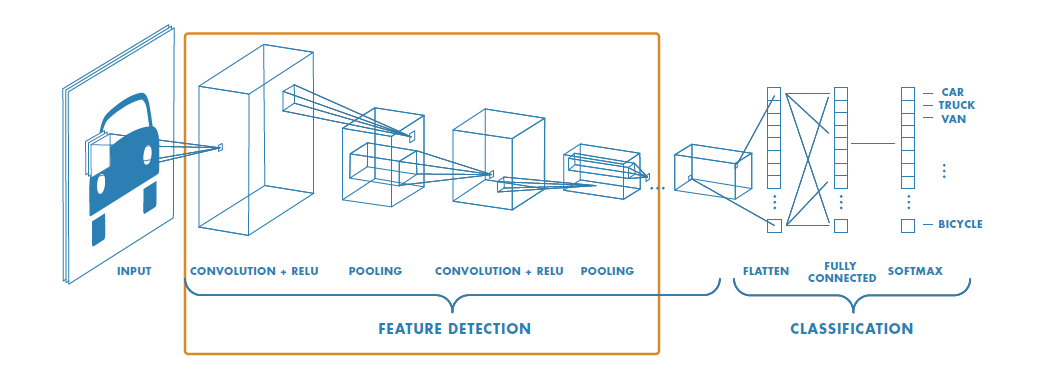
Die Objekterkennung besteht aus einer Lokalisierung (Wo, in welcher "Bounding Box", befindet sich das Objekt?) und einer Klassifikation (Was ist das Objekt?). Es können einstufige oder zweistufige Verfahren eingesetzt werden, bei zweistufigen Verfahren wird zunächst die Lokalisierung und Merkmalsextraktion durchgeführt, danach die Klassifikation, bei einstufigen Verfahren werden Lokalisierung und Klassifikation in einem Schritt zusammenausgeführt.
Der praktische Einsatz von ConvNets für die Objekterkennung wird durch eine Reihe von Frameworks unterstützt
- Einstufige Verfahren: YOLO (You look only once), SSD (Single Shot Multibox Detector)
- Mehrstufige Verfahren: (zuerst lokalisieren, dann klassifizieren): R-CNN
Textverarbeitung mittels Deep Learning
Für die Verarbeitung sequentieller Daten wie Text, Sprache oder Zeitreihen werden rekurrente Netze (RNNs)
und LSTM (Long Shirt Term Memory)-Netzwerke eingesetzt.
Eine Anwendung im Marketing ist Sentiment Analysis oder Stimmungserkennung.
Sentiment Detection bezeichnet die automatische Auswertung von Texten mit dem Ziel, eine geäußerte Haltung als positiv oder negativ zu erkennen.
Eine Anwendung in der Industrie ist die Vorhersage von Verbrauchsdaten (z.B. Stromverbrauchsdaten) auf Basis von Vergangenheitsdaten,
ähnlich wie sie in Demo-PY5 durchgeführt wird.
Mehr zu Neuronalen Netzwerken: Demo-PY5
Demo-PY5 zeigt, wie ein "tiefes" Künstliches Neuronales Netz mit mehreren versteckten Long Short-Term Memory (LSTM)-Schichten trainiert, validiert und damit eine Prognose über die zukünftige Entwicklung der Stromverbrauchsdaten erstellt wird. Die Daten werden in der interaktiven, webbasierten Anwendungsumgebung Jupyter Notebook analysiert.
5 Sprachen und Frameworks für Maschinelles Lernen
Für die Entwicklung eines Lernenden Systems mit Machine Learning-Algorithmen werden aktuell im Wesentlichen
drei Sprachen mit den dazu passenden Entwicklungsumgebungen verwendet, die Programmbibliotheken mit vergleichbarer Funktionalität anbieten:
Python, MATLAB, R.
Ein Klassifikationsproblem kann mit Hilfe eines Entscheidungsbaum-Modells in jeder der drei Sprachen umgesetzt werden. Die Unterschiede
bestehen darin, mit welchem Algorithmus der Entscheidungsbaum in der jeweiligen Sprache umgesetzt ist, welche Konfigurationsparameter
eingestellt werden können, wie gut die Visualisierung ist.
In Python werden die Methoden fit und predict der Klasse sklearn.tree.DecisionTreeClassifier verwendet, die Visualisierung des Entscheidungsbaums
erfolgt entweder mit Hilfe der sklearn-Funktion plot_tree, oder mit Hilfe von graphviz.
In R wird das Klassifikationsmodell mit Hilfe der Funktion rpart erstellt und die Vorhersage bzw. Klassifikation mit Hilfe der Funktion predict,
die beide zu dem rpart-Packet gehören.
Weitere Tools wie z.B. RapidMiner bieten spezialisierte Oberflächen für Endanwender ohne Programmierkenntnisse, die die Verfahren des maschinellen Lernens einsetzen wollen.
5-1 Python: Die innovative Lösung
Python (entwickelt um 1991 von Guido van Rossum) ist aktuell eine der meistgenutzten Programmiersprachen, die wegen ihres einfachen Zugangs zur Programmierung von vielen Einsteigern genutzt wird. Weshalb wir Python als "innovativ" bezeichnen? Weil Python einerseits eine Programmiersprache für den allgemeinen Gebrauch ist, mit der man Desktop-Clients und Webanwendungen oder auch eingebettete Systeme entwickeln kann, andererseits jetzt als spezialisierte Programmiersprache für Datenanalyse bekannt und im Einsatz ist. Das Python-Ökosystem entwickelt sich sehr dynamisch und Python wird in den letzten Jahren verstärkt im Umfeld der Datenanalyse und des Machine Learning verwendet, häufig in Kombination mit der Plattform Anaconda (für Anwendungs- und Paketverwaltung) und Spyder oder VS Code oder Jupyter Notebook als Entwicklungsplattform. Für die Verwendung von Python für Datenanalyse und Softwareentwicklung sprechen eine Vielzahl von Gründen:
- Python ist gut lesbar und verständlich, somit ist ein schneller Einstieg in die Syntax möglich, und in Kombination mit Jupyter Notebook ist es für den Einsatz in der Lehre geeignet.
- Python bietet umfangreiche und kostenlose Programmbibliotheken für Datenverwaltung und Datenanalyse.
- Python kann prozedural oder objektorientiert behandelt werden.
- Python ist multiplattform-fähig (Windows, Mac, Linux, Raspberry Pi usw.).
Die einfache Verwendung der kostenlosen Python-Programmpakete für Datenverwaltung, -Modellierung und -Analyse Numpy, Pandas, Scikit-Learn, Keras und Tensorflow machen Python zu einer attraktiven Alternative für spezialisierte Datenanalyse-Tools wie RStudio oder MATLAB Statistics and Machine Learning Toolbox.
MATLAB: Die industrielle Lösung
Die MATLAB Software des US-amerikanischen Unternehmens MathWorks wird in der Industrie und in Forschungseinrichtungen viel für numerische Simulation sowie Datenerfassung, Datenanalyse und -auswertung eingesetzt. Weshalb wir MATLAB als "industriell" bezeichnen? Weil es eine kommerzielle Lösung ist, die ihren Preis hat, und oft in Industrie-Unternehmen (z.B. Maschinenbau, Elektrotechnik) eingesetzt wird, die die professionelle Umsetzung und den Support zu schätzen wissen. Für verschiedene Anwendungsgebiete stellt Mathworks Erweiterungspakete bereit, die sogenannten Toolboxen. Für Maschinelles Lernen können z.B. die Statistics and Machine Learning Toolbox oder die Deep Learning Toolbox eingesetzt werden, sowie der Live Script Editor, um ein benutzerfreundliches und interaktives Skript zu erstellen.
Mit Hilfe der Funktionen und Apps der MATLAB Statistics and Machine Learning Toolbox können viele Standardverfahren des Machine Learning durchgeführt werden, Klassifikation und Regression, mit Entscheidungsbäumen oder Neuronalen Netzwerken, Clusteranalysen etc.
R und RStudio: Die klassische Lösung
R ist eine freie Programmiersprache für statistische Berechnungen und Grafiken.
Sie wurde 1992 von den Statistikern Ross Ihaka und Robert Gentleman an der Universität Auckland für Anwender mit statistischen Aufgaben
neu entwickelt und ist auf UNIX-Plattformen, Windows and MacOS lauffähig.
R ist eine Open Source-Lösung und kann somit kostenlos eingesetzt werden.
R wird bevorzugt von Datenanalysten in Offline-Szenarien eingesetzt.
R ist eine Standardsprache für statistische Problemstellungen sowohl in der Wirtschaft als auch in der Wissenschaft.
Weshalb wir R als "klassisch" bezeichnen? Weil R einen klaren Fokus auf Statistik und Datenanalyse hat, im Unterschied
zu Python, das eine Programmiersprache für den allgemeinen Einsatz ist, oder MATLAB, das allgemeiner auf numerische
Verfahren und Simulation ausgerichtet ist.
Da der Quellcode öffentlich ist, bietet R die Möglichkeit, schnell neue Pakete zu entwickeln und zur Verfügung zu stellen. Die kostenlosen und online verfügbaren Pakete erweitern das Anwendungsfeld von R auf viele
Fachbereiche. Die internen Dokumentationen und auch die Foren, die sich mit der Anwendung von R befassen, bieten dem Benutzer die Möglichkeit, die
Funktionalität von R leicht zu erfassen und anzuwenden.
Autoren, Tools und Quellen
Autoren:
Prof. Dr. Eva Maria Kiss
Tools:
Quellen und weiterführende Links:
- [1] Alpaydın E (2019) Maschinelles Lernen, De Gruyter Studium.
- [2] Hochreiter, Sepp & Schmidhuber, Jürgen. (1997). Long Short-term Memory. Neural computation. 9. 1735-80.
- [3] Goodfellow Ian, Bengio Yoshua, Courville Aaron (2017) Deep Learning. Adaptive Computation and Machine Learning Series. MIT Press Ltd, Cambridge, Mass.
- [4] Mitchell, Tom (1997) Machine Learning.
- [5] Yann LeCun, Yoshua Bengio, Geoffrey Hinton (2005) Deep Learning. Nature, vol 521.
- [6] Russell, Stuart J., Norvig, Peter (2014) Artificial intelligence. A modern approach.
- [7] Introducing Deep Learning with MATLAB: 80879v00_Deep_Learning_ebook.pdf
- [8] Saul Dobilas (2022) LSTM Recurrent Neural Networks: Article, medium.com