Demo-PY3: Clusteranalyse "Automotive in 3D"
Die vorliegende Demo zeigt, wie eine Clusteranalyse mit Hilfe der Python-Bibliothek scikit-learn durchgeführt wird, hier am Beispiel eines Automobildatensatzes, der auch in Demo-PY4: Predictive Maintenance mit scikit-learn verwendet wird. In diesem Anwendungsfall werden die Cluster auf Basis von drei Merkmalen des Datensatzes erstellt und die Cluster-Zuordnung der Daten wird im 3 dimensionalen Raum visualisiert. Dazu wird das Toolkit mplot3d verwendet, dieses Toolkit erweitert die Bibliothek Matplotlib um Methoden zur Erstellung von 3D-Grafiken.
Motivation
Für die Automobildaten wurden in
Demo-PY4: Predictive Maintenance mit scikit-learn
mittels eines Entscheidungsbaums diejenigen Merkmale / Sensordaten ermittelt, die am stärksten
zu einem Ausfall des Motors beitragen.
Diese drei Merkmale werden nun herangezogen, um eine
Clusteranalyse durchzuführen.
Bei einer Clusteranalyse werden durch die Verwendung eines bestimmten Ähnlichkeits- bzw.
Abstandsmaßes Gruppen/Cluster ähnlicher Merkmale gebildet.
Anschließend können neue Daten anhand ihrer Merkmale den in der Analyse gebildeten Clustern zugeordnet werden.
Die Zuordnung zu den Clustern anhand der drei Merkmale wird danach
im 3 dimensionalen Raum visualisiert und interpretiert.
Übersicht
Das Tutorial ist als Google Colab Notebook online verfügbar:
1 Die Fragestellung
Aus den Ergebnissen der in Demo-PY4: Predictive Maintenance mit scikit-learn
durchgeführten Analysen wurden drei Merkmale, die am stärksten zum Ausfall des Motors beitragen, ausgewählt: der Ansaugkrümmerdruck, die Drosselklappenstellung und die Katalysatortemperatur.
Die Frage, die mit einer Clusteranalyse beantwortet werden soll, lautet: Welche Clusterzuordnung der
Motoren erfolgt bzgl. dieser drei Merkmale, die den stärksten Einfluss auf den Ausfall hatten?
2 Vorbereitung: Installation der Entwicklungsumgebung
Um Python-Programme schreiben zu können, verwendet man Entwicklungsumgebungen wie
Visual Studio Code oder Jupyter Notebook.
Zunächst sollte eine aktuelle Python-Installation von der Python-Webseite python.org heruntergeladen und installiert werden.
Anschließend muss Visual Studio Code von der Webseite des Anbieters code.visualstudio.com/ heruntergeladen und installiert werden.
Alternativ kann Jupyter Notebook als Teil der
Paketverwaltungsplattform Anaconda
installiert werden.
Details zur Installation und Verwendung von Python und Visual Studio Code sind im Python-Tutorial beschrieben.
Die Details der Installation von Python und Anaconda sind in dem Abschnitt Vorbereitung: Installation von Python und Anaconda beschrieben.
Die Details der Verwendung von Jupyter Notebook ist in dem Tutorial Jupyter Notebook verwenden beschrieben, inkl. YouTube-Anleitung.
3 Clusteranalyse im 3 dimensionalen Raum
Über Programme öffnen wir die Jupyter Notebook-Anwendung und erstellen mit Hilfe des Menüpunkts "New" ein neues Python3-Notebook mit dem Namen elab2go-Demo-PY3_automotive. In dieses Notebook werden vier Codezellen eingefügt, die den üblichen Schritten bei der Erstellung einer Clusteranalyse entsprechen.
- 3-1 Importieren der Programmbibliotheken
- 3-2 Daten einlesen und verwalten
- 3-3 Clusteranalyse durchführen
- 3-4 Zuordnung der Daten zu den Clustern visualisieren
3-1 Importieren der Programmbibliotheken
In der ersten Codezelle des Jupyter Notebooks importieren wir die benötigten Programmbibliotheken: Die
in Demo-PY3 bereits vorgestellten Bibliotheken
scikit-learn und sciPy, die die verwendeten Clustering-Algorithmen enthalten, sowie die aus
Demo-PY2: Datenverwaltung mit Pandas
bekannten Bibliotheken Pandas, Matplotlib und NumPy werden
in Python mit Hilfe der import-Anweisung entweder komplett importiert
oder mit Hilfe der from-import-Anweisung nur einzelne Funktionen der Programmbibliothek abgerufen.
Zusätzlich wird in diesem Anwendungsfall das Toolkit
mplot3d verwendet,
das die Bibliothek Matplotlib um Methoden zur Erstellung von 3D-Grafiken erweitert.
Die erste Codezelle enthält insgesamt sieben Import-Anweisungen.
- Zeile 1: NumPy: Wird für den Umgang mit Vektoren, Matrizen oder generell Arrays benötigt.
- Zeile 2: Pandas: Wird für Datenverwaltung und Datenbereinigung benötigt
- Zeile 3: Matplotlib: Wird für die Visualisierung, Plots etc. benötigt.
- Zeile 4: scipy.cluster.hierarchy: Wird für die Anwendung der hierarchischen Verfahren benötigt.
- Zeile 5: mplot3d: Wird zur Erstellung von 3D-Grafiken benötigt.
- Zeile 6: AgglomerativeClustering: wird für die Anwendung der hierarchischen Methoden benötigt.
import numpy as npimport pandas as pdimport matplotlib.pyplot as pltimport scipy.cluster.hierarchy as shcimport mpl_toolkits.mplot3d.axes3d as p3from sklearn.cluster import AgglomerativeClustering
3-2 Daten einlesen und verwalten
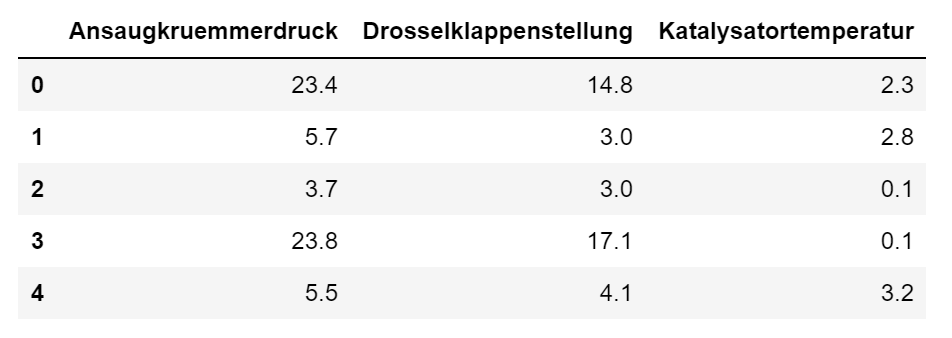
In der zweiten Codezelle werden Daten, die in der csv-Datei automotive_test_140.csv gespeichert sind, mit Hilfe der Funktion read_csv() der Pandas-Bibliothek eingelesen, siehe auch Demo-PY2: Datenverwaltung mit Pandas.
# Lese CSV-Datei einfile = 'automotive_test_140.csv'df = pd.read_csv(file, header=0, sep = ";")# Auswahl der drei Merkmale in der Clusterananlysemerkmale = df.iloc[:,[6,7,23]].copy() ;X = merkmale.to_numpy()# Zeige die ersten 5 Daten zur Kontrolle anmerkmale.head(5)
Erläuterung des Codes:
- Zeile 2: Die Datei automotive_test_140.csv wird zum Einlesen festgelegt.
- Zeile 3: Die Funktion read_csv() wird mit zum Einlesen des Datensatzes aufgerufen.
- Zeile 6: Es erfolgt eine Auswahl und Speicherung der drei Merkmale/Variablen/Spalten unter dem Namen merkmale.
- Zeile 7: Die Merkmale der Beobachtungen werden in ein Numpy-Array mit Namen X kopiert. Das Array X wird später als Eingabeparameter des AgglomerativeClustering verwendet.
- Zeile 10: Die ersten 5 Beobachtungen der ausgewählten Merkmale werden ausgegeben.
Die Ausgabe nach Ausführung dieses Codeblocks sieht ähnlich aus wie abgebildet.
3-3 Clusteranalyse durchführen
Die Clusteranalyse erfolgt in zwei Schritten. Zunächst wird mit Hilfe eines Dendogramms die korrekte Anzahl an Clustern ermitteln, danach werden mit einem hierarchischen Clustering die Daten den Clustern zugeordnet.
Schritt 1: Clusterzahl mit Dendogramm ermitteln
Die Clusteranalyse beginnt mit der Erstellung eines Dendrogramms, dies ist ein Hilfsmittel, um die korrekte Anzahl der Cluster/Zentren herauszufinden. In Python wird ein Dendogramm mit der dendrogram-Funktion des cluster.hierarchy-Pakets der SciPy-Bibliothek durchgeführt.
fig = plt.figure(figsize=(10, 7))ax = fig.add_axes([0.1,0.1,0.75,0.75])ax.set_title("Hierarchisches Cluster-Dendogramm mit 4 bis 5 Clustern")ax.set_xlabel("Distanz")ax.set_ylabel("Cluster")Z = shc.linkage(X, method='ward')dend = shc.dendrogram(Z)plt.savefig("dendogramm.svg, dpi=320, format="svg", bbox_inches='tight')
Erläuterung des Codes:
- Zeile 1 bis 5: Bereitet ein Grafikfenster mit einer festen Größe, Titel und Achsenbeschriftungen vor. Die x-Achse zeigt die Distanz der Cluster, die y-Achse die Anzahl der Cluster.
- Zeile 6: Die linkage-Funktion des cluster.hierarchy-Pakets der sciPy-Bibliothek führt eine hierarchische Clusteranalyse mittels verschiedener auswählbarer Linkfunktionen durch und gibt ein Array mit vier Spalten Z zurück. Der Abstand zwischen den Clustern Z[i, 0] und Z[i, 1] wird durch Z[i, 2] gegeben. Der Linkage-Algorithmus für die Erstellung eines Dendogramms überprüft in jedem Schritt, welche Cluster den geringsten Abstand zueinander haben, und fusioniert diese zu einem neuen Cluster. Je nach Linkage-Methode wird die Distanz zwischen den Clustern unterschiedlich bestimmt. Mögliche Optionen für die Linkfunktion sind 'single', 'complete', 'average', 'weighted' oder 'ward'. Die Ward-Methode ist eine Varianz-basierte-Methode, bei welcher Cluster, die den kleinsten Zuwachs der totalen Varianz aufweisen, fusioniert werden.
- Zeile 7-8: Das Rückgabe-Array Z dieser Methode wird der dendrogram-Funktion übergeben, um ein Dendrogramm zu erstellen. Das Diagramm kann optional als SVG-Bilddatei gespeichert werden.
Die Ausgabe nach Ausführung dieses Codeblocks sieht ähnlich aus wie abgebildet. Das Dendrogramm zeigt das Vorhandensein von 4 oder 5 Clustern an. Die Information über die Anzahl der Cluster verwenden wir bei der Durchführung der Clusteranalyse, die im nächsten Schritt erfolgt.

Schritt 2: Clusteranalyse mit AgglomerativeClustering
Die detaillierte Clusteranalyse wird mittels der AgglomerativeClustering aus dem sklearn.cluster-Paket der scikit-learn-Bibliothek durchgeführt.
Die Anzahl der Cluster bzw. Zentren wird als n = 4 festgelegt. Das Vorhersagemodell model wird als Instanz der Klasse AgglomerativeClustering erstellt, mit den Argumenten n_clusters=n und linkage='ward', und danach die Methode fit() mit den Datenpunkten X als Parameter aufgerufen. Die Zuordnungen zu den Clustern werden für die Beobachtungen gespeichert und ausgegeben.
print("Erstelle Modell für Hierarchisches Clustering ...")# Lege Clusteranzahl festn = 4# Erstelle Vorhersagemodell modelmodel = AgglomerativeClustering(n_clusters=n, linkage='ward').fit(X)# Gebe Zuordnungen zu Clustern auszuordnung = model.labels_print("Anzahl Beobachtungen: %d" % zuordnung.size)print("Zuordnung der Beobachtungen zu Cluster-Zentren 0, 1, 2, 3:")print(zuordnung)
Die Ausgabe nach Ausführung dieses Codeblocks sieht ähnlich aus wie abgebildet. Das Array zuordnung ist folgendermaßen zu interpretieren: die erste Beobachtung ist im Cluster 0, die zweite im Cluster 3, und die letzte im Cluster 3.

3-4 Zuordnung der Daten zu den Clustern visualisieren
Die Ergebnis, d.h. die Zuordnung der Beobachtungen zu den vier möglichen Zentren/Clustern, wird als 3D-Plot dargestellt. Dazu wird das Toolkit mplot3d verwendet, dieses Toolkit erweitert die Bibliothek Matplotlib um Methoden zur Erstellung von 3D-Grafiken, z.B. um die Funktion Axes3D, die ein 3D-Grafikfenster erstellt.
# Daten visualisierenfig = plt.figure(figsize=(10, 7))ax = fig.add_subplot(projection='3d')for z in np.unique(zuordnung):ax.scatter(X[zuordnung == z, 0], X[zuordnung == z, 1], X[zuordnung == z, 2],color=plt.cm.jet(float(z) / np.max(zuordnung + 1)),s=20, edgecolor='k')plt.title('Clusterzuordnung der Motoren')ax.set_xlabel('Ansaugkruemmerdruck')ax.set_ylabel('Drosselklappenstellung')ax.set_zlabel('Katalysatortemperatur')plt.show()
Erläuterung des Codes:
- Zeile 2-3: Es wird einen Figur mit vorgegebener Breite und Höhe und ein 3D-Grafikfenster erstellt.
- Zeile 5-8: Die Beobachtungen je nach Zuordnung zu den Clustern (z=0,1,2 und 3) werden in einer for-Schleife abgerufen und je nach Cluster-Zuordnung wird der Datenpunkt unterschiedlich im Plot eingefärbt.
- Zeile 10-14: Der Titel und die Achsenbeschriftungen des Plots werden angepasst.
Die Ausgabe nach Ausführung dieses Codeblocks sieht ähnlich aus wie abgebildet.

4 Die Interpretation
Bei der Bildung und Visualisierung der vier Cluster fällt auf, dass
- die Cluster unabhängig von der Katalysatortemperatur gebildet wurden
- ein Cluster bei der Merkmalskombination Ansaugkrümmerdruck niedrig und Drosselklappenstellung niedrig entsteht (Farbe: orange)
- ein weiteres Cluster bei der Merkmalskombination Ansaugkrümmerdruck hoch und Drosselklappenstellung niedrig entsteht (Farbe: grün)
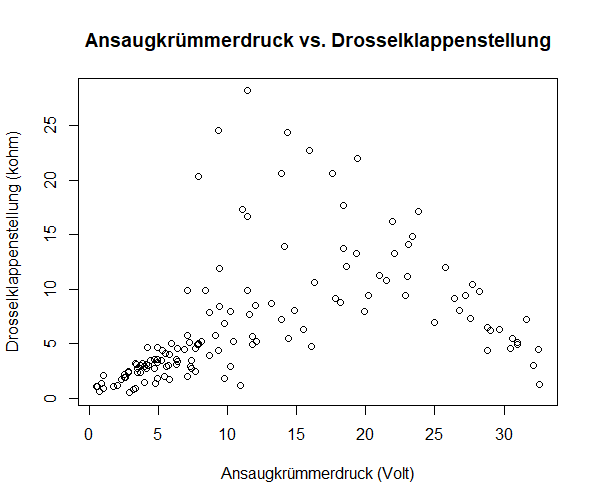
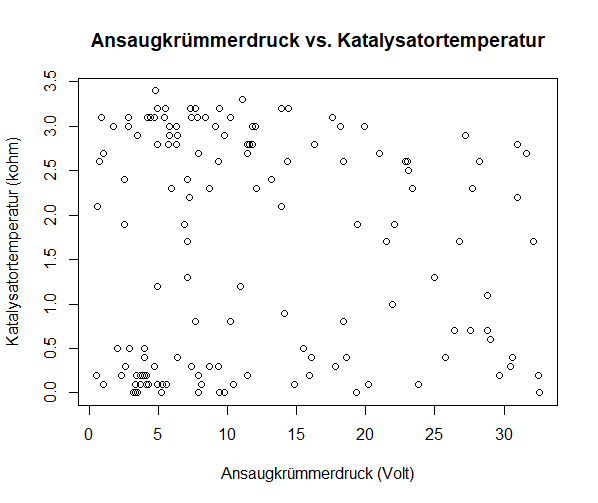
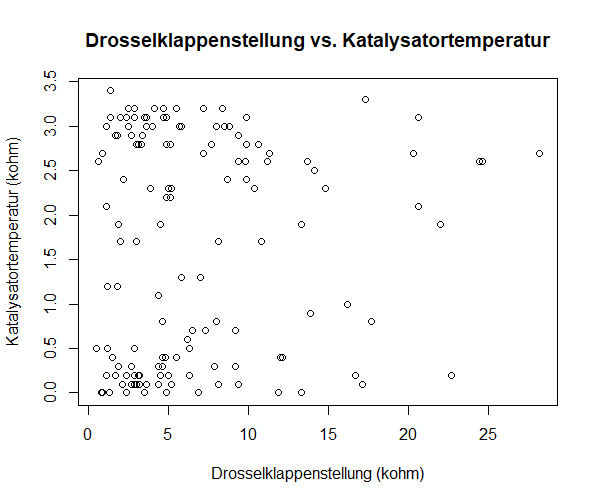
Die Visualisierung in 2-dimensionalen Grafiken Ansaugkrümmerdruck vs. Drosselklappenstellung, Ansaugkrümmerdruck vs. Katalysatortemperatur
und Drosselklappenstellung vs. Katalysatortemperatur zeigen auch, dass es keinen direkten Zusammenhang zwischen der
Katalysatortemperatur und den anderen beiden Variablen gibt. In der Grafik Ansaugkrümmerdruck vs. Drosselklappenstellung ist die
Bildung der Cluster, wie sie die obige Analyse ergeben hat, ebenfalls zu erkennen: es besteht ein grafischer Zusammenhang/Abhängigkeit
zwischen Ansaugkrümmerdruck niedrig und Drosselklappenstellung niedrig und Ansaugkrümmerdruck hoch und Drosselklappenstellung niedrig.
| 2D-Plot 1 | 2D-Plot 2 | 2D-Plot 3 |
|---|---|---|
|
|
|
Die Bildung der Cluster (orange und grün) spiegeln den funktionalen Zusammenhang zwischen den Bauteilen Ansaugkrümmer und
Drosselklappe wieder. Eine Drosselklappe wird dazu verwendet, um den Ansaugkrümmerdruck und damit die Ansaugluftdichte zu regeln.
Im Verbrennungsmotor, der wie eine Luftpumpe wirkt, wird die Luft oder Luft-Kraftstoff-Gemisch durch den Einlass ein und durch den Auslass heraus gedrückt.
Der Durchfluss dieser Luftmasse oder des Gemisches hängt neben der Motorendrehzahl und dem Hubraum und eben auch von der
Luftdichte des Ansaugkrümmers ab und damit indirekt von der Stellung der Drosselklappe.
Bei der Interpretation der Cluster spielen die beiden Zustände Leerlauf und Volllast eine Rolle. Bei Leerlauf sind die
Drosselklappe und ein sogenannter Leerlaufschalter geschlossen. Erreicht der Öffnungswinkel einen vom Motorsteuergerät
festgelegten Wert,
startet der Volllastbereich und ein Volllastschalter wird geschlossen. Bei geschlossenem Volllastschalter
wird die Kraftstoffeinspritzmenge erhöht, um bessere Leistungswerte zu erzielen. Die Widerstandswerte des Drosselklappensensors liegen
bei geschlossener Drosselklappe (Leerlauf) z.B. bei 1190 Ohm bzw. 1.19 kohm, und bei geöffneter Drosselklappe (Volllast) z.B. bei 9200 Ohm
bzw. 9.2 kohm.
Die beiden Cluster (orange und grün) beinhalten damit Motoren, deren Drosselklappen sich in geschlossenen (Leerlauf) oder leicht
geöffneten Zustand (Anlassen eines Motors) befinden. Das Verhalten des Ansaugkrümmerdrucks während des Leerlaufs kann wie folgt beschrieben werden:
Die dicht geschlossene Drosselklappe drosselt den Luftdurchfluss aus der Umgebung, wenn der Motor Luftmasse von Ansaugkrümmer
weg pumpt. Der kumulative Effekt ist eine Verringerung der Ansaugkrümmerluftdichte, was zu einem reduzierten Gesamtdruck im Vergleich zum
Luftdruck führt (orangenes Cluster).
5 Weiterführende Fragen
Die Clusterbildung unabhängig von der Katalysatortemperatur zeigt, dass dieses Bauteil keinen direkten Einfluss auf die beiden anderen
ausgewählten Bauteile/Merkmale Drosselklappenstellung und Ansaugkrümmerdruck hat. Da zum Katalysatorschutz aber je nach Abstimmung des Motormanagements
die Einspritzmenge (und damit der Kraftstoffverbrauch) erhöht wird, um den Katalysator zu kühlen, wäre das Aufnehmen weiterer Merkmale, die
damit in Zusammenhang stehen, für eine weiterführende Clusteranalyse sinnvoll.
Mögliche Merkmale aus dem Automobildatensatz für eine erweiterte Clusteranalyse sind
die eingesetze Einspritzmenge in Kurzzeit, die eingesetze Einspritzmenge in Langzeit sowie der Kraftsstoffeinsatz. Aufgrund eines möglichen
erhöhten Kraftstoffeinsatzes zum Katalysatorschutz ist auch das Merkmal der Kraftstoffdampfsäuberung, das zeigt wie gut
der Katalysator arbeitet, eine sinnvolles Merkmal für eine Clusteranalyse im höher dimensionalen Raum.
Auch hinsichtlich weiterer Analysen in Bezug auf den Gesamtzustand des Motors, seiner Leistungsfähigkeit, einer möglichen Wartung oder eines Ausfalls spielt
die Wirkung der Bauteile untereinander und
ihr Zustand und ihre Wirkungsweise eine entscheidende Rolle.
Autoren, Tools und Quellen
Autoren:
M.Sc. Anke Welz
Prof. Dr. Eva Maria Kiss
Tools:
Quellen und weiterführende Links: