Python Tutorial Teil 3 – Bibliotheken
Teil 3: Python-Bibliotheken dieses kompakten Python-Tutorials
gibt eine Übersicht über die wichtigsten Pakete für Datenanalyse und Machine Learning.
Zunächst werden die Pakete NumPy, Matplotlib
und Pandas vorgestellt, die für Datenvorbereitung und -Visualisierung verwendet werden,
gefolgt von der Machine Learning-Bibliothek Scikit-Learn,
und einem repräsentativen Anwendungsfall: die Vorhersage von Ausfällen mittels DecisionTreeClassifier.
In Abschnitt 2-4 wird die Verwendung eines Künstlichen Neuronalen Netzwerkes
für die Bilderkennung mit Hilfe der Bibliotheken Keras und Tensorflow illustriert.
Weitere Bibliotheken werden in Teil 4: Kryptographie des Tutorials
vorgestellt: die Pakete PyCryptodome, hashlib und bcrypt, mit Funktionen für Verschlüsselung,
Hashing und Passwort-Hashing.
Motivation
Machine Learning ist ein Teilgebiet der Künstlichen Intelligenz, mit dessen Hilfe selbst-lernende Systeme entwickelt werden, die auf Basis von Trainingsdaten automatisch lernen und hinzulernen können.
Machine Learning-Anwendungen wie z.B. Bild / Video / Text-Bearbeitung oder auch Ausfall-Vorhersagen werden bevorzugt mit Python entwickelt, denn: Python hat umfangreiche und kostenlose Bibliotheken für Datenanalyse und Machine Learning, die alle relevanten Algorithmen des Machine Learning abbilden: Entscheidungsbaum-Verfahren, Clusteranalysen, Künstliche Neuronale Netzwerke.
Die üblichen Schritte der Machine Learning-Pipeline, wie Datenvorbereitung, Modellauswahl, Modell trainieren, Modell validieren werden durch aufeinander abgestimmte Bibliotheken umgesetzt.
Von den hier vorgestellten Bibliotheken werden die ersten drei, nämlich NumPy, Matplotlib und Pandas, auch für Datenanalyse und statistische Problemstellungen eingesetzt, wie z.B. die Auswertung und Visualisierung von Messwerten.
Übersicht
- 1 Python-Pakete für Datenanalyse
- 1-1 NumPy: Wissenschaftliches Rechnen
NumPy Arrays NumPy Zufallszahlen
NumPy Arrays vs. Python Listen - 1-2 Matplotlib: Datenvisualisierung
plot hist scatter
subplots
Plotly: Interaktive Diagramme und Dashboards - 1-3 Pandas: Datenstrukturen für Tabellen
DataFrame erzeugen
Zeilen und Spalten extrahieren
Daten aus Datei einlesen
Daten visualisieren - 1-4 Anwendung: Messwerte analysieren
- 2 Python-Pakete für Machine Learning
- 2-1 Scikit-Learn: Machine Learning
Übersicht: UML-Klassendiagramm
Anwendung: Ausfall-Klassifikation - 2-2 Keras: Deep Learning
- 2-3 Tensorflow: Deep Learning
- 2-4 Anwendung: Bilderkennung mit Keras und Tensorflow
Das Tutorial ist als Google Colab Notebook online verfügbar:
1 Python-Pakete für Datenanalyse
Zu den wichtigsten Python-Bibliotheken für Datenanalyse und Datenvisualisierung gehören:
- NumPy
- NumPy bündelt Funktionen für Wissenschaftliches Rechnen, das Erstellen und Bearbeiten mehrdimensionaler Arrays und Zufallszahlen.
- Matplotlib
- Matplotlib bündelt Funktionen für Datenvisualisierung und unterstützt gängige Diagrammtypen wie Linien- und Scatter-Plots, Histogramme und Balkendiagramme. Die erstellten Diagramme sind statisch, d.h. defaultmäßig nicht interaktiv.
- Pandas
- Pandas bündelt Funktionen für das Bearbeiten tabellenartiger Daten, ähnlich wie man es aus Excel kennt, nur eben mit Python-Funktionen und damit automatisierbar. Mit Pandas kann man Tabellen erstellen, Daten über ihre Spalten- und Zeilennamen auswählen, sortieren, filtern, aggregieren und visualisieren.
Diese Bibliotheken werden oft zusammen verwendet: man erstellt mehrdimensionale NumPy-Arrays, packt sie in ein Pandas-DataFrame und ergänzt sie dort mit Zeilen- und Spaltenüberschriften, und visualisiert ausgewählte Spalten des DataFrames mit Matplotlib.
pip install numpy pandas matplotlib
Die Verwendung der Paketverwaltungssysteme pip und conda wird in Python-Tutorial Teil 2: Pakete installieren genauer beschrieben.
1-1 NumPy - Wissenschaftliches Rechnen
NumPy ist eine Python-Bibliothek für wissenschaftliches Rechnen und bündelt Funktionen für die Erzeugung, Umformung und statistische Auswertung von Arrays und Zufallszahlen. Mit NumPy können Arrays erstellt, mit Default-Werten initialisiert und extrahiert werden, man kann elementweise Operationen an Arrays durchführen, Elemente sortieren, suchen, zählen und Array-Statistiken berechnen. NumPy bietet auch mathematische Konstanten und Funktionen.
NumPy verwenden: 1D und 2D-Arrays
Im folgenden Beispiel wird die Erzeugung von 1D und 2D-Arrays gezeigt.
Zunächst werden zwei eindimensionale NumPy-Arrays x1 und x2 mit jeweils vier Elementen erstellt:
x1 aus einer Liste über den Array-Konstruktor np.array(), x2 als Zahlenfolge (Start: 1, Ende: 8, Schrittweite 2) über die Funktion arange().
Mit Hilfe des Ausdrucks sum = x1 + x2 wird die elementweise Summe der beiden NumPy-Arrays berechnet.
Die elementweise Summe zweier NumPy-Arrays kann alternativ auch mit sum = np.add(x1, x2) berechnet werden.
Danach werden zwei zweidimensionale Arrays a1 und a2 erstellt: eine 2x2 Matrix a1 mit den Elementen 1, 2, 3, 4,
und a2 als 2x2 Einheitsmatrix mit Hilfe der Funktion eye().
Für die beiden 2D-Arrays wird schließlich mittels prod = a1 * a2 das elementweise Produkt berechnet.
Ausgabe: NumPy verwendenimport numpy as np# Eindimensionale Arraysx1 = np.array([1, 2, 3, 4])x2 = np.arange(1, 8, 2) # 1, 3, 5, 7sum = x1 + x2 # Elementweise Summeprint('x1:', x1, '\nx2:', x2, '\nsum:', sum)# Zweidimensionale Arraysa1 = np.array([[1, 2], [3, 4]], )a2 = np.eye((2))prod = a1 * a2 # Elementweises Produktprint('a1:\n', a1, '\na2:\n', a2, '\nprod:\n', prod)

Häufig verwendete Funktionen für die Umformung von NumPy-Arrays sind: np.reshape() - ändere die Dimensionen des Arrays, np.transpose() - transponiere Array.
NumPy verwenden: Zufallszahlen
Für die Erzeugung von Zufallszahlen in Python stehen mehrere Funktionen zur Verfügung:
die Python Standardbibliothek hat einen Zufallsgenerator, mit dem man einzelne Zufallszahlen erzeugen kann.
Das NumPy-Paket random enthält einen Zufallsgenerator default_rng und
Funktionen, mit deren Hilfe man Arrays aus Zufallszahlen mit unterschiedlichen Häufigkeitsverteilungen
erstellen kann.
Python-Code: NumPy-Zufallszahlen
Dies Beispiel zeigt die Erzeugung von Zufallszahlen mit dem NumPy-Zufallsgenerator.
Zunächst wird der Default-Zufallsgenerator mit einem festen Seed erstellt,
danach eine einzelne Zufallszahl (Zeile 7), danach eine Liste mit 5 Zufallszahlen (Zeile 9).
import numpy as np# Erzeuge einen Zufallsgenerator rng mit Seed 12345rng = np.random.default_rng(seed = 12345)n = 5print("** NUMPY: ZUFALLZAHLEN **")# Erzeuge eine Zufallszahl im Intervall [0, 1)z = rng.random()print('Zufallszahl im Intervall [0, 1)\n', z)# n int-Zufallszahlen im Intervall [10, 20)zint = rng.integers(low=10, high=20, size=n)print('5 int-Zufallszahlen im Intervall [10, 20)\n', zint)
Der Unterschied des NumPy-Generators im Vergleich zu den Zufallszahlen der Python-Standardbibliothek besteht darin, dass Methoden wie rng.uniform() und rng.normal() angeboten werden, um direkt ein- und mehrdimensionale Zufalls-Arrays mit unterschiedlichen Verteilungen zu erstellen.
import numpy as npprint("** NUMPY: ZUFALLZAHLEN mit gegebener Verteilung **")# Verwende den Zufallsgenerator PCG64rng = np.random.Generator(np.random.PCG64())n = 5# n gleichverteilte Zufallszahlen im Intervall [10, 20)zuni = rng.uniform(low=10, high=20, size=n)print('5 gleichverteilte Zufallszahlen\n', zuni)# n normalverteilte Zufallszahlen mit Nittelwert 15 und Standardabw. 3znorm = rng.normal(15, 3, n)print('5 normalverteile Zufallszahlen\n', znorm)
NumPy Arrays vs. Python Listen
Datenstrukturen für Listen gibt es sowohl in der Python-Standardbibliothek als auch in NumPy.
Was ist also der Unterschied zwischen NumPy Arrays und den Listen der Python Standardbibliothek?
NumPy-Arrays haben eine feste Größe, enthalten Elemente desselben Datentyps und unterstützen effizient elementweise Operationen und
eine Vielzahl statistischer Funktionen. Sie werden daher bevorzugt im Umfeld der Datenanalyse eingesetzt.
Im folgenden Beispiel werden verschiedene Arten der Summenbildung bzw. Addition gezeigt: der "+"-Operator ist jeweils
abhängig von dem Datentyp der Operanden mit einer anderen Funktionalität belegt.
- Addiert man zwei Python-Listen, so ist das Ergebnis eine neue Liste, in der die Elemente aneinandergefügt wurden.
- Addiert man zwei NumPy-Arrays, so ist das Ergebnis ein neues Array, das die elementweise addierten Elemente enthält.
Die elementweise Addition kann auch mit Python Listen durchgeführt werden, jedoch komplizierter, dann muss eine Schleife oder die
sogenannte List Comprehension verwendet werden, wie im Beispiel unten.
import numpy as np# Zwei Python Listenlist1 = [1, 2, 3, 4]list2 = [5, 6, 7, 8]# Konvertiert in NumPy Arraysarr1 = np.array(list1) # NumPy Array [1 2 3 4]arr2 = np.array(list2) # NumPy Array [5 6 7 8]# Verschiedene Arten der Addition / Summenbildungprint("Addiere Python Listen: Aneinanderfügen!")sum = list1 + list2print(sum) # [1, 2, 3, 4, 5, 6, 7, 8]print("Addiere NumPy Arrays: Elementweise Summe!")sum = arr1 + arr2print(sum) # [6 8 10 12]print("Elementweise Summe für Listen, ohne NumPy:")sum = [x + y for x, y in zip(list1, list2)]print(sum) # [6 8 10 12]
Eine Konvertierung von und zu Python-Listen ist mittels Konvertierungs-Funktionen problemlos möglich:
# NumPy Array erstellen arr = np.array([1, 2, 3, 4]) # NumPy Array in Liste konvertieren list = arr.tolist()
1-2 Matplotlib - Datenvisualisierung
Matplotlib ist eine Python-Bibliothek für Datenvisualisierung, die über das Paket pyplot das Erstellen von Diagrammen unterschiedlichster Art unterstützt: Linien-, Punkte-, Balkendiagramme, ein- und zweidimensonal, statisch oder interaktiv. Die wichtigsten Funktionen zum Plotten sind plot, hist, scatter, bar, pie für eindimensionale und surf für mehrdimensionale Diagramme. Der plot-Befehl erhält als Parameter die x- und y-Koordinaten der darzustellenden Daten, und optional einen String mit Formatierungsangaben. Weiterhin stehen viele Optionen zum Hinzufügen von Beschriftungen, Titeln, Legenden etc. zur Verfügung.
Matplotlib verwenden: Liniendiagramm mit plot()
Liniendiagramme werden verwendet, um stetige Funktionen zu visualisieren,
z.B. mathematische Funktionen.
Liniendiagramme werden in Python mit Hilfe der Matplotlib-Funktion plot(x, y) erzeugt.
Die plot-Funktion benötigt als Parameter zumindest die x- und y-Werte, die man als Listen übergibt.
Das Layout des Liniendiagramms wie z.B. Linienfarbe und -Stärke, Marker-Farbe und Stärke,
Beschriftungen, Legende, wird über weitere optionale Parameter konfiguriert.

Beispielcode: Matplotlib verwenden: Liniendiagramm
Der Beispielcode zeigt, wie die Sinus- und Cosinus-Funktion auf demselben Diagramm
dargestellt werden.
import numpy as npimport matplotlib.pyplot as pltx = np.linspace(0, 2*np.pi, 40) # 40 x-Wertey1 = np.sin(x);y2 = np.cos(x); # 40 y-Werte# Figur mit festgelegter Größefig = plt.figure(figsize=(6, 3))# Zwei Diagramme auf demselben Achsensystemplt.plot(x, y1,'r*', label='sin'); # Plot der Sinus-Funktionplt.plot(x, y2,'b+', label='cos'); # Plot der Cosinus-Funktionplt.title('Sinus und Cosinus-Funktion');plt.grid(True) # Gitter wird angezeigtplt.legend(loc="upper center") # Legende oben mittigplt.xlabel('x');plt.ylabel('y'); # Achsen-Beschriftungenplt.show()
Die abkürzende Angabe 'r*' bewirkt, dass das Diagramm rote Linienfarbe und den Marker '*' verwendet.
Matplotlib verwenden: Histogramm mit hist()
Die Häufigkeitsverteilung von Zufallszahlen (z.B. Messwerten) kann mittels eines Histogramms visualisiert werden.
Die Daten werden nach ihrer Größe sortiert und in mehrere Klassen "Bins" eingeteilt, z.B. 10 Bins.
Über jeder Klasse wird ein Rechteck gezeichnet, dessen Fläche proportional zur Häufigkeit dieser Klasse ist.
Ein Histogramm kann ein Häufigkeitsdiagramm (die Fläche stellt die Anzahl der Elemente in dieser Klasse dar) oder ein Dichtediagramm
(die Fläche stellt den Prozentsatz der Elemente in dieser Klasse dar) sein.
Histogramme werden in Python mit Hilfe der Matplotlib-Funktion hist(x, bins=None, range=None, density=False, histtype='bar', orientation='vertical', ...) erzeugt und können über die Parameter der Funktion weiter konfiguriert werden.
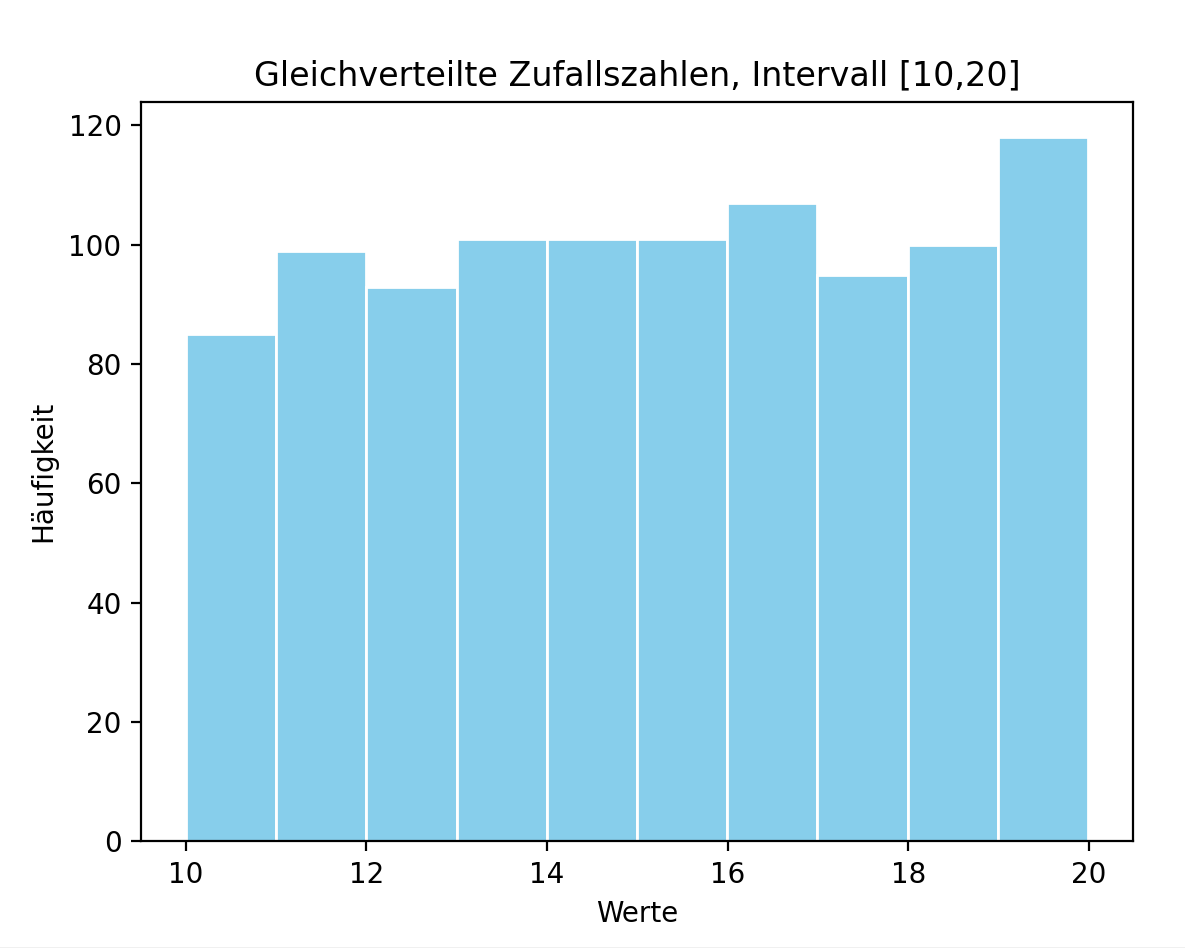
Beispielcode: Matplotlib verwenden: Histogramm
Der Beispielcode zeigt, wie ein Histogramm zur Visualisierung der Häufigkeitsverteilung
von Zufallszahlen mit Matplotlib's hist-Funktion erzeugt wird.
import numpy as npimport timeimport matplotlib.pyplot as plt# Initialisiere Zufallsgenerator mit aktueller Systemzeitrng = np.random.default_rng(seed=int(time.time()))# n Zufallszahlen, gleichmäßig verteilt im Intervall [ug, og]n = 1000; ug = 10; og = 20;daten = np.random.uniform(ug, og, n)print("Zufallszahlen, gleichmäßig verteilt :", daten[0:5])# Histogramm plottenplt.hist(daten, bins=10, color='skyblue', edgecolor='white')plt.xlabel('Werte');plt.ylabel('Häufigkeit');plt.title('Gleichverteilte Zufallszahlen, Intervall [10,20]')plt.show()
Matplotlib verwenden: Scatter-Plot mit scatter()
Scatter-Plots werden verwendet, um den Zusammenhang zwischen zwei Zufallsvariablen zu visualisieren.
Mit einem Scatter-Plot kann man Muster in den Daten und mögliche Cluster mit ähnlichen Daten erkennen.
Scatter-Plots werden in Python mit Hilfe der Matplotlib-Funktion scatter(x, y, s=None, c=None, marker=None, ...) erzeugt und können über die Parameter der Funktion weiter konfiguriert werden.

Beispielcode: Matplotlib verwenden: Scatter-Plot
Der Beispielcode zeigt, wie ein Scatter-Plot zur Visualisierung des Zusammenhangs zwischen
den Zufallsvariablen "Luftfeuchtigkeit" und "Temperatur" mit Matplotlib's scatter-Funktion erzeugt wird.
In diesem Beispiel sind drei Cluster zu erkennen: "warm-feucht", "kalt-trocken" und "normal".
import matplotlib.pyplot as plt# Zufallsvariable 1: 14 Temperaturmessungentemp = [21, 19, 19, 21, 22, 23, 21, 23, 25, 25, 13, 14, 16, 17]# Zufallsvariable 2: 14 Luftfeuchtigkeit-Messungenfeucht = [42, 45, 52, 55, 53, 69, 80, 81, 73, 75, 21, 29, 30, 25]# Scatter-Plot: rot, mit o als Markerplt.scatter(x=temp, y=feucht, color='tab:red', marker='o')plt.grid(True)plt.title("Temperatur vs. Luftfeuchtigkeit")plt.xlabel('Luftfeuchtigkeit(%)')plt.ylabel('Temperatur (Grad Celsius)')plt.show()
Matplotlib verwenden: Figuren mit subplots()
In Python werden mehrere zusammengehörende Diagramme mittels der Funktion subplots()
erzeugt.
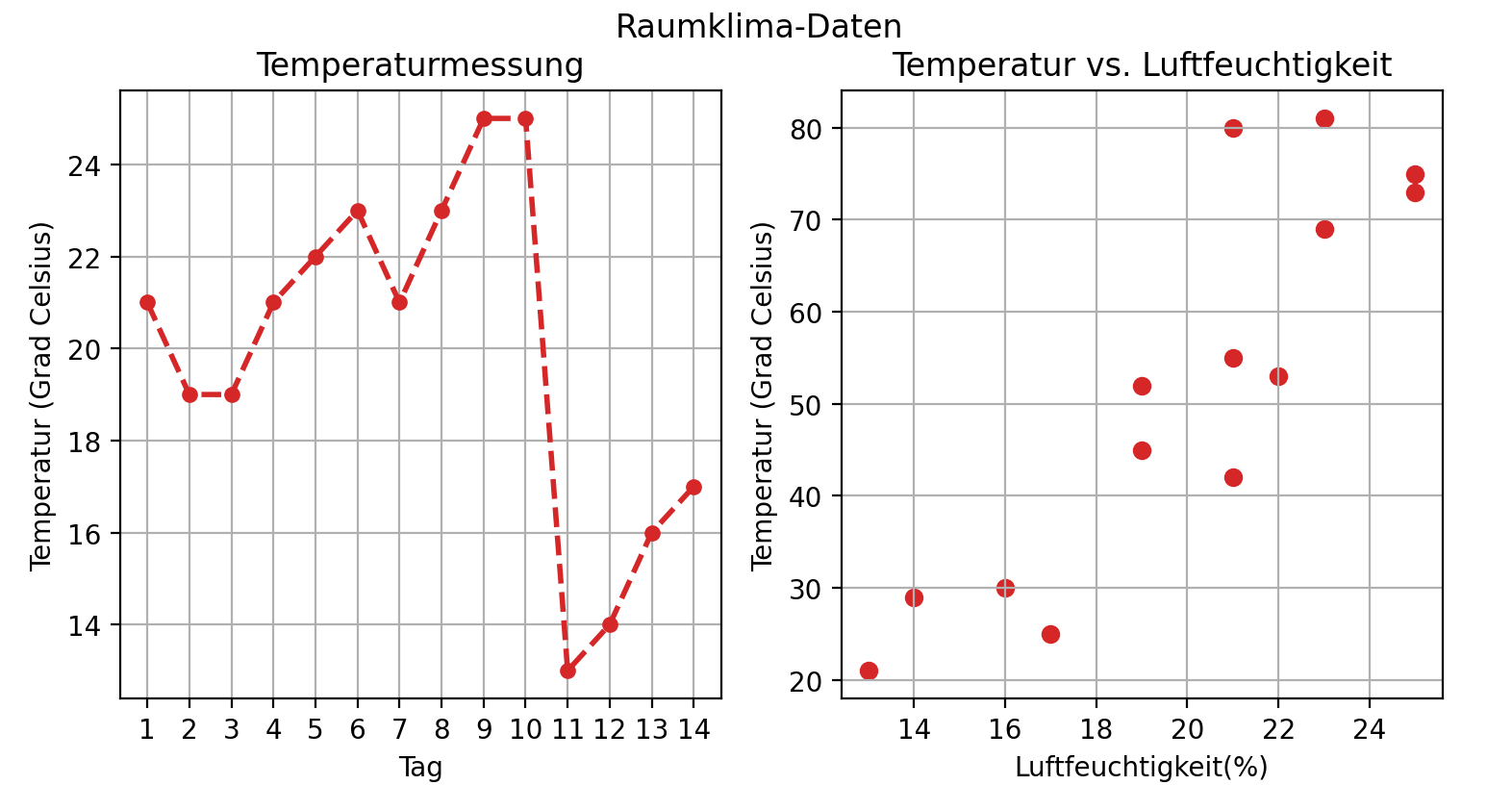
Die Matplotlib-Funktion subplots() erhält als Parameter die Position der Diagramme, die Größe der Figur, und ob eine gemeinsame y-Achse zu verwenden ist, und gibt die Figur fig und die Achsen-Liste axs zurück. So bedeutet fig, axs = plt.subplots(1, 2): erstelle eine Figur mit einer Zeile und zwei Spalten, d.h. die Diagramme werden nebeneinender angeordnet. Hingegen bedeutet fig, axs = plt.subplots(2, 1): erstelle eine Figur mit zwei Spalten und einer Zeile, d.h. die Diagramme werden untereinander angeordnet. Auf die einzelnen Achsen wird über ihren Index zugegriffen, d.h. mit axs[0].plot(x, y) wird ein Diagramm auf das erste Achsensystem geplottet, mit axs[1].plot(x, y) auf das zweite usw.
Beispielcode: Matplotlib verwenden: Figur mit Subplots
Der Beispielcode zeigt, wie eine Figur mit zwei Diagrammen erzeugt wird, die nebeneinander angeordnet sind.
Die verwendeten Daten sind Messungen der Temperatur und Luftfeuchtigkeit an 14 aufeinanderfolgenden Tagen.
Für die Visualisierung der Temperaturmessung wird ein Liniendiagramm mit plot() erstellt.
Für die Visualisierung von Feuchtigkeit vs. Temperatur wird ein Scatter-Plot verwendet, da man darin
mögliche Cluster besser erkennen kann.
import matplotlib.pyplot as plttage = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14] # 14 Tagetemp = [21, 19, 19, 21, 22, 23, 21, 23, 25, 25, 13, 14, 16, 17] # Temperaturfeucht = [42, 45, 52, 55, 53, 69, 80, 81, 73, 75, 21, 29, 30, 25] # Luftfeuchtigkeit# (1) Figur mit Achsen erstellenfig, axs = plt.subplots(1, 2, figsize=(9, 3), sharey=False)# (2) Erstes Diagramm: ein Liniendiagrammaxs[0].plot(tage, temp, color='tab:red', marker='o',markersize=5, linestyle='dashed', linewidth=2);axs[0].grid(True);axs[0].set_title("Temperaturmessung");axs[0].set_xlabel('Tag');axs[0].set_ylabel('Temperatur (Grad Celsius)');axs[0].set_xticks(tage)# (3) Zweites Diagramm: ein Scatter-Plotaxs[1].scatter(x=temp, y=feucht, color='tab:red', marker='o')axs[1].grid(True);axs[1].set_title("Temperatur vs. Luftfeuchtigkeit");axs[1].set_xlabel('Luftfeuchtigkeit(%)');axs[1].set_ylabel('Temperatur (Grad Celsius)');fig.suptitle('Raumklima-Daten')plt.show()
Datenvisualisierung mit Plotly
Die Python-Bibliothek Plotly wird als Ergänzung bzw. Alternative zu Matplotlib verwendet,
und zwar dann, wenn man anstelle von statischen Diagrammen interaktive Diagramme erzeugen
und in ein Dashboard oder in eine Webseite einbauen möchte.
Plotly erleichtert das Erstellen und Exportieren von Diagrammen in HTML-Format und
ermöglicht beispielsweise, bei Anklicken des Diagramms zusätzliche Informationen anzuzeigen.
Plotly Dash ist ein zusätzliches Paket, mit dessen Hilfe man Datenvisualisierungen
in interaktive Dashboards einbinden kann, die außer der Diagrammen auch Steuerelemente (Eingabe- und
Auswahlfelder) enthalten, über die man einstellen kann, welche Daten genau angezeigt werden.
Plotly: Statische Diagramme
Um statische Plotly-Diagramme erstellen und speichern zu können,
müssen gleich zwei Python-Pakete installiert werden:
zunächst das Paket plotly selber, und dann das Python-Paket Kaleido, um Bilder in Bilddateien speichern zu können.
Die Installation erfolgt wie bei allen Python-Paketen mit dem pip-Befehl:
pip install plotly, kaleido
Plotly Dash:
Interaktive Dashboards
Um interaktive Dashboards erstellen zu können, muss zunächst das Python-Paket dash installiert werden, mit pip install dash.
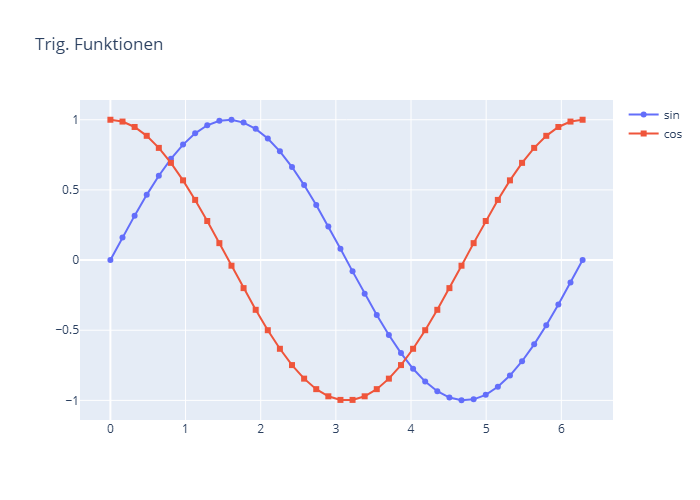
Plotly: Statische Diagramme erstellen
Der folgende Beispielcode zeigt die Erstellung eines statischen Diagramms mit Plotly:
Zunächst wird eine neue Figur angelegt, der man mit add_trace() neue Diagramme hinzufügt.
Diagramm-Typen sind z.B. Scatter-Plots, Bar-Blots oder Contour-Plots.
Einstellungen für einzelne Diagramme werden über die
Parameter des Plots (hier: go.Scatter) eingestellt, dazu gehören außer den x- und y-Werten
der Name des Plots, der Linientyp, das Marker-Symbol und viele mehr.
Einstellungen für die gesamte Figur werden mit update_layout() vorgenommen, dazu gehören
die Festlegung der Bildgröße, des Titels und die Anzeige der Legende.
Figuren werden mit write_image() als Bild-Dateien,
und mit write_html() als interaktive HTML-Dateien mit eingebetteter Figur gespeichert.
Der gewünschte Dateipfad kann zuvor mit Hilfe der Funktionen des Pakets os eingestellt werden.
In unserem Beispiel werden die Dateien im Verzeichnis des aktuellen Python-Skripts gespeichert.
import numpy as npimport plotly.graph_objects as gofig = go.Figure()x = np.linspace(0, 2*np.pi, 40)fig.add_trace( go.Scatter(x=x, y=np.sin(x), name='sin',mode='lines+markers', marker_symbol='circle'))fig.add_trace(go.Scatter(x=x, y=np.cos(x), name='cos',mode='lines+markers', marker_symbol='square'))fig.update_layout(height=400, width=500,title='Trig. Funktionen',showlegend=True)fig.show()import ospy_dir = os.path.dirname(__file__)fig.write_image(py_dir+ r'\plotly-scatter.png')fig.write_html(py_dir+ r'\plotly-scatter.html')
import plotly.io as pio pio.renderers.default = "vscode"
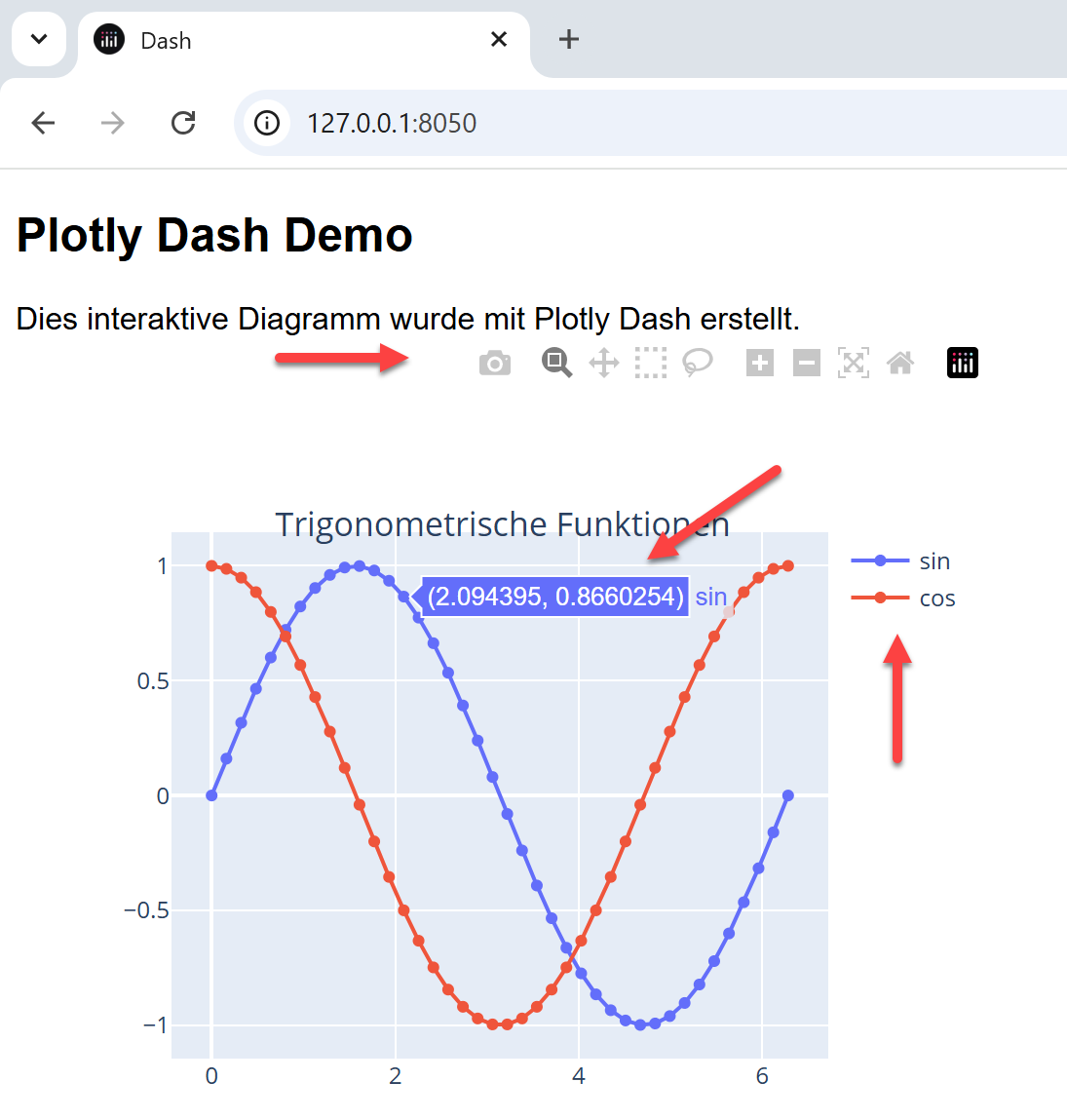
Plotly Dash: Interaktives Dashboard erstellen
Der folgende Beispielcode zeigt die Erstellung eines minimalen Dashboards,
das außer einer interaktiven Figur auch eine Überschrift und einen Erklärungstext enthält.
Durch Anklicken der Diagrammbeschriftungen "sin" und "cos" werden die jeweils ausgewählten Diagramme
ein- und ausgeblendet.
import numpy as npimport plotly.graph_objects as go# Figur erstellenfig = go.Figure()x = np.linspace(0, 2*np.pi, 40)fig.add_trace( go.Scatter(x=x, y=np.sin(x), mode='lines+markers', name='sin'))fig.add_trace(go.Scatter(x=x, y=np.cos(x), mode='lines+markers', name='cos'))fig.update_layout(height=400, width=500,title='Trigonometrische Funktionen',title_x=0.5, title_y = 0.8, showlegend=True)# Dashboard erstellenfrom dash import Dash, dcc, htmlapp = Dash(__name__)app.layout = html.Div([html.H2(children = 'Plotly Dash Demo'),html.Div(children='Dies interaktive Diagramm wurde mit Plotly Dash erstellt.'),dcc.Graph(id="graph", figure=fig, animate=True,responsive=True, style={'max-width':'500px'})], style={'font-family': 'Arial'})app.run(debug=True)
1-3 Pandas - Datenstrukturen und Datenanalyse
Pandas ist eine Python-Bibliothek, die spezielle Datenstrukturen - Series und DataFrames - für den Zugriff auf Excel-ähnliche beschriftete Datentabellen anbietet, sowie viele Funktionen, mit deren Hilfe die Daten erstellt, bearbeitet und visualisiert werden können. In der Datenanalyse spielt Pandas eine zentrale Rolle, da damit große Excel- und csv-Dateien in den Arbeitsspeicher des Programms geladen werden, mit dem Ziel, die Daten anschließend zu analysieren und visualisieren. Pandas-Funktionen wie iloc(), loc(), resample() werden verwendet, um Zeilen / Spalten / Zellen auszuwählen und Daten zu gruppieren und aggregieren.
1-3-1 Pandas verwenden: DataFrame erzeugen und speichern
Ein DataFrame repräsentiert eine tabellarische Datenstruktur mit einer geordneten Menge von Spalten,
die jeweils verschiedene Datentypen haben können.
Ein Pandas DataFrame hat stets Zeilenüberschriften, die über das Attribut index festgelegt werden,
sowie Spaltenüberschriften, die über das Attribut columns festgelegt bzw. abgefragt werden.
DataFrames können auf verschiedene Arten erzeugt werden, zum Beispiel aus einem Dictionary,
dessen Werte gleich lange Listen sind, oder durch Einlesen von CSV-Dateien.


Beispielcode: DataFrame erzeugen und speichern
In diesem Beispiel wird ein DataFrame mit Hilfe der Funktion pd.DataFrame aus einem Dictionary gebildet,
das jedem Spalten-Namen eine Liste von Werten zuordnet.
Erläuterung des Beispielcodesimport pandas as pd# Erzeuge ein Dictionary (Schlüssel-Wert-Paare)studenten = {"Name": ["Muster", "Test", "Lange", "Klug"],"Vorname": ["Max", "Anna", "Jessica", "Matthias"],"Alter": [22, 24, 26, 23],"Note": [1.7, 2.1, 1.3, 3.0]}# Erzeuge DataFrame aus Dictionarydf = pd.DataFrame(studenten)# Schreibe Daten in CSV-Datei und Excel-Dateidf.to_csv("studenten.csv", sep=';', decimal=',')df.to_excel("studenten.xlsx")print(df)print(df.index.values) # Ausgabe: [0 1 2 3]print(df.columns) # Ausgabe: ['Name' 'Vorname' 'Alter' 'Note']
- Zeile 3 - 8: Dem Schlüssel "Name" wird die Liste der Namen zugeordnet, hier: Muster, Test, Lange und Klug. Ähnlich entsprechen die weiteren Schlüssel-Wert-Paare jeweils einer Spalte.
- Zeile 10: Mit der Anweisung df = pd.DataFrame(studenten) wird aus dem Dictionary studenten das DataFrame df erstellt.
- Zeile 12-13: Das DataFrame wird mittels der Funktionen to_csv() und to_excel() in eine CSV- bzw. Excel-Datei gespeichert. Bei der CSV-Datei wird als Trennzeichen das Semikolon und als Dezimalzeichen das Komma festgelegt.
- Zeile 15: Hier wird der Index des DataFrames ausgegeben, d.h. die Zeilenüberschriften. Da in diesem Beispiel keine Zeilenüberschriften explizit festgelegt wurden, wird die Default-Zeilennummern 0,1,2,3 ausgegeben.
- Zeile 16: Hier werden die Spaltenüberschriften ausgegeben.
import os
os.makedirs('daten', exist_ok=True)
df.to_csv('daten/studenten.csv')
1-3-2 Pandas verwenden: Zeilen und Spalten extrahieren
Ein häufiger Schritt bei der Bearbeitung tabellarischer Daten ist die Extraktion
ausgewählter Zeilen und Spalten.
Die Erstellung neuer Tabellen durch Extraktion ausgewählter Zeilen und Spalten
geschieht in Pandas mittels der Funktionen iloc und loc.
Die Funktion iloc wählt Zeilen und Spalten über die Angabe eines Index-Bereichs aus.
df.iloc[zIdx,:] bedeutet: extrahiere alle Werte der Zeile zIdx,
df.iloc[:, sIdx] bedeutet: extrahiert alle Werte der Spalte sIdx.
df.iloc[[0,1,2], [3,4]] bedeutet: extrahiere die Werte aus den Zeilen 0, 1 und 2 und Spalten 3 und 4.
Die Funktion loc wählt Zeilen und Spalten über die Angabe eines Zeilen- oder Spaltennamens aus.
df.loc['Z1',:] bedeutet: extrahiere alle Werte der Zeile mit Namen 'Z1'
df.loc[:, 'S2'] bedeutet: extrahiere alle Werte der Spalte mit dem Namen 'S2'.
df.loc[['Z0', 'Z1', 'Z2'],['S3', 'S4']] bedeutet: extrahiere aus den Zeilen Z0, Z1 und Z2
die Werte der Spalten S3 und S4, wie im folgenden Beispielcode.
Die Spalten eines DataFrames können direkt durch Angabe des Spalten-Namens ausgewählt werden.
df['S1'] bedeutet: extrahiere die Spalte mit dem Namen S1 in ein eindimensionales Array (als "Series").
Bei Angabe von Spaltennamen muss auf eine genaue Übereinstimmung der Zeichen geachtet werden, da
abweichende Groß/Kleinschreibung oder Leerzeichen zu Fehlern führen: df['S1 '] ist nicht dasselbe wie df['S1'],
df['s1'] ist nicht dasselbe wie df['S1'].
Beispielcode: Zeilen und Spalten extrahieren
In diesem Beispiel wird ein DataFrame mit Hilfe der Funktion pd.DataFrame
aus einem NumPy Array arr gebildet und erhält die Zeilennamen Z0, Z1, ..., Z4
sowie die Spaltennamen S0, S1,...,S5.
Anschließend extrahieren wir einzelne Zeilen und Spalten entweder über den Index oder über den
jeweiligen Namen.
import pandas as pdimport numpy as nparr = np.array([[10, 12, 11, 15, 13],[12, 14, 14, 11, 12],[16, 13, 10, 17, 15],[22, 21, 25, 25, 24]])df = pd.DataFrame(arr)df.index = ["Z" + str(x) for x in range(0, 4)]df.columns = ["S" + str(x) for x in range(0, 5)]print("DataFrame mit 4 Zeilen und 5 Spalten\n", df)# Wähle Zeile mit Index 0 auszeile = df.iloc[0,:]# Wähle Zeile mit Name 'Z0' auszeile = df.loc['Z0',:]print("Werte der 0-ten Zeile", zeile.values)# Wähle Spalte mit Index 2 ausspalte = df.iloc[:,2]# Wähle Spalte mit Name 'Z2' ausspalte = df.loc[:,'S2']print("Werte der zweiten Spalte", spalte.values)# Wähle Zeilen 0,1,2 und Spalten 3,4 ausdf2 = df.iloc[[0,1,2], [3,4]]# Wähle Zeilen und Spalten über ihre Namen ausdf2 = df.loc[['Z0', 'Z1', 'Z2'],['S3', 'S4']]print("Wähle Zeilen 0,1,2 und Spalten 3,4 aus\n", df2)
Ausgabe: Zeilen und Spalten extrahieren
DataFrame mit 4 Zeilen und 5 Spalten
S0 S1 S2 S3 S4
Z0 10 12 11 15 13
Z1 12 14 14 11 12
Z2 16 13 10 17 15
Z3 22 21 25 25 24
Werte der 0-ten Zeile [10 12 11 15 13]
Werte der zweiten Spalte [11 14 10 25]
Wähle Zeilen 0,1,2 und Spalten 3,4 aus
S3 S4
Z0 15 13
Z1 11 12
Z2 17 15
1-3-3 Pandas verwenden: Daten einlesen
In diesem Beispiel werden mit Hilfe der Pandas-Funktion read_excel()
Daten aus einer Excelmappe in ein DataFrame eingelesen und mittels to_csv() in eine csv-Datei geschrieben.
Die Excel-Datei studenten.xslx kann über den Link heruntergeladen werden.
Danach einfach der Variablen file den geänderten Dateinamen inkl. Pfadangabe übergeben.
Datei studenten.xlsx herunterladen
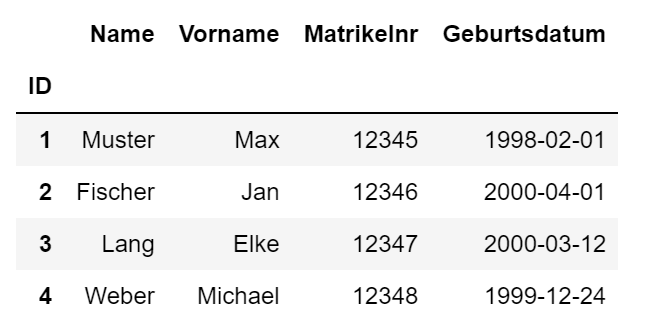
import pandas as pd# Daten aus studenten.xlsx einlesen, erste Spalte enthält den Indexfile = 'https://www.elab2go.de/demo-py1/daten/studenten.xlsx'df = pd.read_excel(file, header=0, index_col=0, parse_dates=True)# Daten in die csv-Datei schreiben, mit angegebenem Trennzeichendf.to_csv('studenten.csv', index=True, sep = ';')# DataFrame df ausgebendf
- Zeile 4: Das Einlesen mit der Funktion read_excel() wird durch eine Reihe von Parametern gesteuert,
die wichtigsten sind header und index_col.
Die Angabe header = 0 im Funktionsaufruf bewirkt, dass die erste Zeile der Excelmappe als Spaltenüberschriften interpretiert wird. header = None wird verwendet, wenn die Excelmappe keine Spaltenüberschriften enthält und die Daten direkt in der ersten Zeile anfangen.
Die Angabe index_col = 0 im Funktionsaufruf bewirkt, dass die erste Spalte der Excelmappe (hier: die Spalte ID) als Index-Spalte festgelegt wird, d.h. sie wird die eindeutigen Zeilenbeschriftungen enthalten. - Zeile 6: Die Daten werden mit to_csv in die CSV-Datei studenten.csv geschrieben.
- Zeile 8: Das DateFrame df wird einfach durch Angabe des Namens formatiert ausgegeben.
Eine weitere wichtige Eingabe-Funktion und ähnlich wie read_excel() ist die Funktion read_csv().
Die Funktion read_csv(file, header, index_col, sep, delimiter) liest den Inhalt einer csv-Datei
und speichert die eingelesenen Daten als Pandas DataFrame.
Die Datei inkl. Dateipfad wird über den Parameter file angegeben, dabei können
absolute oder relative Verzeichnispfade angegeben werden, auch URLs.
Die anderen Parameter konfigurieren die Art des Einlesens:
header: welche Zeile wird als Spaltenüberschrift eingelesen
index_col: welche Spalte wird als Zeilenüberschrift eingelesen
sep: welches Zeichen wird als Trennzeichen verwendet (meist Semikolon oder Komma)
delimiter: welches Zeichen wird als Dezimaltrennzeichen für Nachkommastellen verwendet (im Englischen Punkt, im Deutschen Komma).
Die Werte der Parameter header, index_col und sep müssen passend zum Inhalt der csv-Datei angegeben werden.
Bei einer csv-Datei daten.csv mit Spaltenüberschriften in der ersten Zeile, Zeilenüberschriften in der ersten Spalte und
einem Semikolon als Trennzeichen, ist der korrekte Funktionsaufruf demnach:
read_csv("daten.csv", header=0, index_col=0, sep=";", delimiter=".")
1-3-4 Pandas verwenden: Daten visualisieren
Eine praktische Anwendung der Python-Bibliothek Pandas ist das Visualisieren numerischer Daten,
die in tabellarischer Form als Excel- oder CSV-Datei vorliegen.
Man kann die Daten einerseits mit Pandas nur einlesen und dann separat mit Matplotlib plotten,
es geht jedoch auch direkter über die plot-Funktion eines DataFrames, die ihrerseits
Matplotlib verwendet.
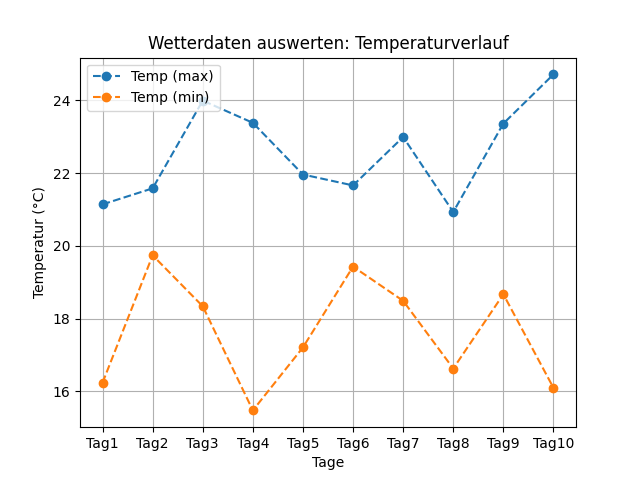
Das Beispiel "Wetterdaten visualisieren" zeigt, wie Daten, die als CSV-Datei wetterdaten.csv gespeichert vorliegen, in ein DataFrame df eingelesen und danach spaltenweise extrahiert und geplottet werden.
├─ pandas-tutorial │ ├─ wetterdaten.csv │ ├─ my-pandas-plot.py
Datei mit Messwerten: wetterdaten.csv
Die CSV-Datei wetterdaten.csv enthält Wetterdaten in 4 Spalten:
Temperatur (max), Temperatur (min), Feuchtigkeit in Prozent und Windgeschwindigkeit in km/h.
;Temp (max);Temp (min);Feucht;Windgeschw. Tag1;21.14;16.24;8.16;52.74 Tag2;21.58;19.74;15.99;40.08 Tag3;23.99;18.34;34.01;56.6 Tag4;23.38;15.48;46.52;46.24 Tag5;21.96;17.21;26.64;53.03 Tag6;21.66;19.43;81.58;56.47 Tag7;22.99;18.49;19.33;37.31 Tag8;20.93;16.63;12.95;56.88 Tag9;23.36;18.67;9.17;34.75 Tag10;24.71;16.1;59.86;23.69
Beispielcode: Daten aus CSV-Datei mit Pandas visualisieren
Die Datei wetterdaten.csv wird zunächst mit read_csv() eingelesen,
danach werden zwei ausgewählte Spalten in ein neues DataFrame extrahiert und geplottet.
Die CSV-Datei wetterdaten.csv kann über den Link
Datei wetterdaten.csv herunterladen
heruntergeladen werden.
Danach einfach in Zeile 4 den Dateinamen inkl. Pfadangabe auf die lokale Datei ändern.
my-pandas-plot.py
import numpy as npimport pandas as pdimport matplotlib.pyplot as pltdf = pd.read_csv('https://www.elab2go.de/demo-py1/daten/wetterdaten.csv', index_col = 0, sep =';')df_temp = df.iloc[:,0:2]print('df_temp:\n', df_temp)ax = df_temp.plot(marker='o', style='--', grid=True,title='Wetterdaten auswerten: Temperaturverlauf')ax.set_xlabel('Tage')ax.set_ylabel('Temperatur (°C)')ax.legend(loc = 'upper left')ax.set_xticks(range(0,10))ax.set_xticklabels(df_temp.index)plt.show()
Der Python-Code importiert zunächst die benötigten Bibliotheken, liest die Datei daten.csv mittels read_csv() in ein DataFrame df ein und gibt es zur Kontrolle aus.
- Schritt 1 "Daten einlesen", Zeile 1-5
Der Python-Code importiert zunächst die benötigten Bibliotheken, liest die Datei daten.csv mittels read_csv() in ein DataFrame df ein und gibt es zur Kontrolle aus.
Der Parameter index_col wird hier mit dem Wert 0 angegeben, da die erste Spalte der CSV-Datei (also die Spalte mit Index 0) die Zeilenüberschriften enthält und keine Daten.
Die Parameter-Angabe sep =';' legt fest, dass die CSV-Datei das Semikolon als Trennzeichen (separator) für Spalten verwendet. - Schritt 2 "Daten extrahieren", Zeile 6
Um aus einem DataFrame ausgewählte Zeilen und Spalten per Index zu extrahieren, wird die Pandas Funktion df.iloc verwendet.
df_temp = df.iloc[:,0:2] bedeutet: extrahiere die Spalten 0 (inklusiv) bis 2 (exklusiv) aus dem DataFrame df, und alle Spalten, in ein neues DataFrame df_temp. - Schritt 3 "Daten plotten", Zeile 7-14
Hier wird das DataFrame df_temp mit den Temperatur-Spalten geplottet. Die plot-Funktion erhält diverse Parameter, mittels deren die Eigenschaften des Diagramms festgelegt werden: marker, style, grid, title, und gibt ein Achsensystem ax zurück. Über das Achsensystem kann das Diagramm weiter konfiguriert werden, z.B. werden noch die Position der Legende und die Achsenbeschriftungen festgelegt.
Tabellarische Ausgabe mit Pandas
Verwendete Funktionen:iloc(), print()
Temp (max) Temp (min)
Tag1 21.14 16.24
Tag2 21.58 19.74
Tag3 23.99 18.34
Tag4 23.38 15.48
Tag5 21.96 17.21
Tag6 21.66 19.43
Tag7 22.99 18.49
Tag8 20.93 16.63
Tag9 23.36 18.67
Tag10 24.71 16.10
Plotten mit Pandas
Verwendete Funktionen:plot(), legend(), set_xlabel(), set_ylabel()
1-4 Anwendung - Messwerte analysieren
Das Python-Skript "Messwerte analysieren" zeigt beispielhaft, wie die Bibliotheken NumPy, Pandas und Matplotlib zusammen eingesetzt werden, um Messwerte zu analysieren. Zunächst werden die drei Bibliotheken importiert, danach wird ein zweidimensionales NumPy-Array arr_2d aus Zufallszahlen erstellt. Aus dem NumPy-Array wird anschließend ein Pandas-DataFrame mit passenden Spalten- und Datenüberschriften erstellt und ausgegeben.
- Schritt 1 "Import", Zeile 1-3
In diesem Schritt werden die Bibliotheken mit import as importiert, dabei werden die üblichen Alias-Namen verwendet: np für NumPy, pd für Pandas, plt für Matplotlib. - Schritt 2 "Eingabe", Zeile 4-6
In diesem Schritt werden Zeilen- und Spalten-Anzahl mit input() eingegeben, die Eingabe wird mit int() als ganzzahliger Datentyp gespeichert. - Schritt 3 "NumPy-Array", Zeile 7-10
In diesem Schritt wird die Funktion np.random.rand eingesetzt, um ein zweidimensionales NumPy-Array mit anzZ Zeilen und anzS Spalten zu erzeugen. - Schritt 4 "DataFrame erzeugen", Zeile 11-17
In diesem Schritt wird aus den Zahlenwerten des NumPy-Arrays arr_2d eine tabellenartige Datenstruktur mit Zeilen- und Spaltenüberschriften erstellt.
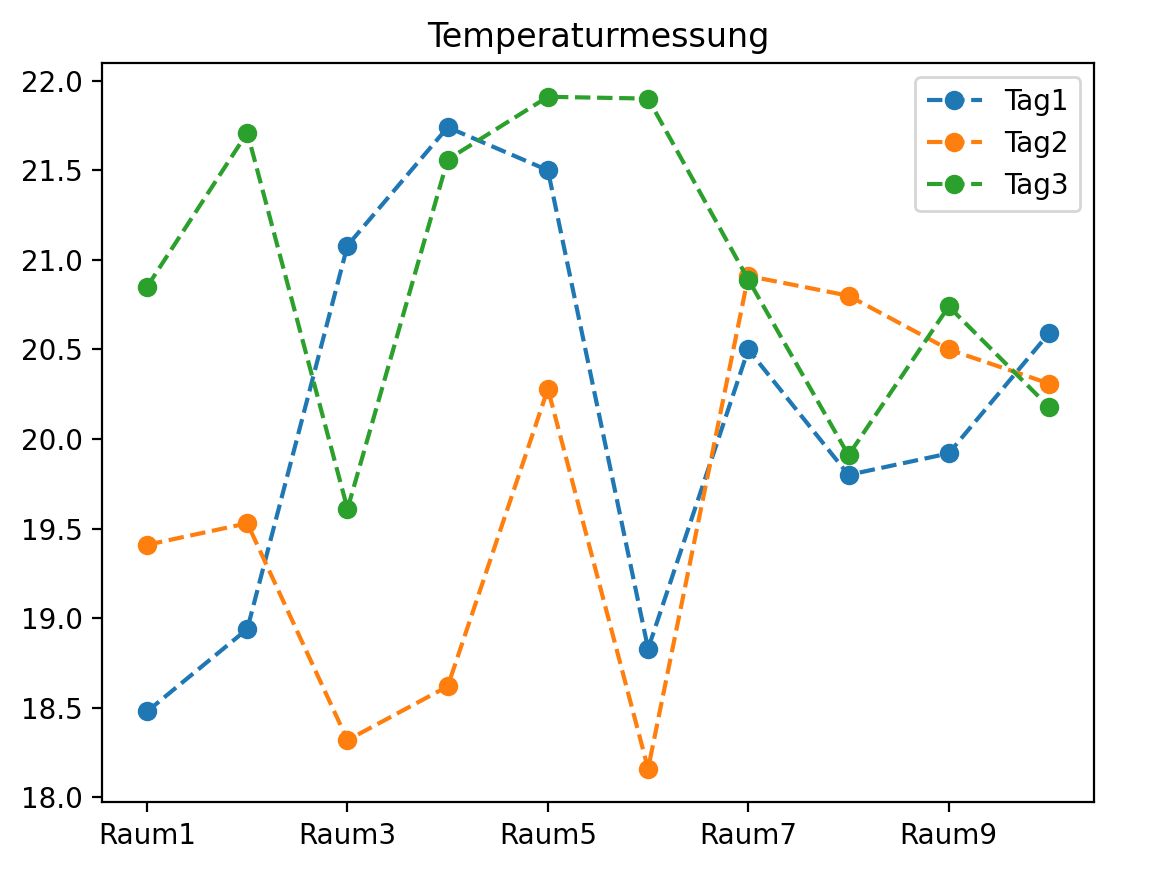
import numpy as np # für 2D-Arrays und Zufallszahlenimport pandas as pd # für DataFramesimport matplotlib.pyplot as plt # für Plotting# EingabeanzZ = int(input("Anzahl Zeilen: "))anzS = int(input("Anzahl Spalten: "))# Tabelle mit Zufallszahlen als NumPy 2D-Arrayug = 18; og = 22; # Wertebereich für Zufallszahlenarr_2d = ug + (og -ug)*np.random.rand(anzZ, anzS)print("Tabelle mit Messwerten\n", arr_2d)# Tabelle als DataFrame mit Zeilen- und Spaltenüberschriftenrow_header = ["Raum" + str(i) for i in range(1, anzZ+1)]col_header = ["Tag" + str(i) for i in range(1, anzS+1)]df = pd.DataFrame(arr_2d)df.index = row_header; df.columns = col_header;df = df.round(decimals=2)print("Tabelle mit Messwerten\n", df)
Messwerte als NumPy 2D-Array
Anzahl Zeilen: 10 Anzahl Spalten: 3 [[18.48175667 19.40744017 20.85421859] [18.94116022 19.53423583 21.70809337] [21.07559607 18.3177326 19.60859666] [21.73513672 18.62044386 21.55645995] [21.50349056 20.28296887 21.90589908] [18.83366329 18.1557398 21.89806723] [20.49927622 20.9106372 20.89251083] [19.79644031 20.79866779 19.90909005] [19.91914777 20.49725658 20.73736 ] [20.58989399 20.31041271 20.18046133]]
Messwerte als Pandas DataFrame
Tag1 Tag2 Tag3
Raum1 18.48 19.41 20.85
Raum2 18.94 19.53 21.71
Raum3 21.08 18.32 19.61
Raum4 21.74 18.62 21.56
Raum5 21.50 20.28 21.91
Raum6 18.83 18.16 21.90
Raum7 20.50 20.91 20.89
Raum8 19.80 20.80 19.91
Raum9 19.92 20.50 20.74
Raum10 20.59 20.31 20.18
Visualisierung und Auswertung der Daten
Die Python-Bibliothek Pandas hat Funktionen zum Erstellen, Auswerten und Visualisieren
tabellenartiger Daten, die als DataFrame gespeichert werden.
Insbesondere kann man alle Spalten eines DataFrames df mit dem Befehl df.plot()
direkt plotten, dabei wird intern die plot-Funktion der Python-Bibliothek Matplotlib ausgeführt.
# Berechne Mittelwerte pro Zeile/Spalteprint("Spalten-Mittelwert\n", df.mean(axis=0))print("Zeilen-Mittelwert\n", df.mean(axis=1))# Berechne Maximum pro Zeile/Spalteprint("Spalten-Max\n", df.max(axis=0))print("Zeilen-Max\n", df.max(axis=1))# Visualisierungdf.plot(marker='o', style='--', title='Temperaturmessung');plt.show();
Plotten des DataFrames
Verwendete Funktion: df.plot()
Berechne Mittelwert pro Zeile
Verwendete Funktion: df.mean(axis=1)
Raum1 19.580000 Raum2 20.060000 Raum3 19.670000 Raum4 20.640000 Raum5 21.230000 Raum6 19.630000 Raum7 20.766667 Raum8 20.170000 Raum9 20.386667 Raum10 20.360000
2 Python-Pakete für Machine Learning
Die Algorithmen und Verfahren des Machine Learning werden in Python durch das Paket Scikit-Learn unterstützt. Für Deep Learning im engeren Sinn, also die Verwendung leistungsfähiger Künstlicher Neuronaler Netzwerke, bietet Python gleich mehrere Programmbibliotheken, darunter PyTorch, JAX, Tensorflow und Keras. Diese Pakete bieten ähnliche Funktionalität für die Erstellung und Verwendung von Deep Learning-Modellen, sind jedoch nicht als gleichwertig zu betrachten. Keras insbesondere ist ein Paket mit Wrapper-Funktionalität, das mit jedem der drei anderen Pakete als Backend verwendet werden kann. PyTorch, JAX und Tensorflow unterscheiden sich in der internen Umsetzung der Verfahren und auch in der Verwendung der API-Funktionen.
2-1 Scikit-Learn - Machine Learning
Scikit-Learn ist eine Python-Bibliothek für Machine Learning und bildet den Ablauf des Überwachten und Unüberwachten Lernens ab: Datenvorbereitung, Training, Modellevaluation und Vorhersage, wobei eine Vielzahl von Algorithmen für Klassifikations-, Regressions- und Clustering-Probleme zur Auswahl stehen. Die Algorithmen werden unter dem Oberbegriff Schätzer bzw. Estimator zusammengefasst. Ein Estimator ist ein Objekt, das Funktionen für das Erstellen und Bewerten von Modellen anbietet, insbesondere eine fit-Funktion/Methode, mit deren Hilfe das Modell für gegebene Daten trainiert wird, score-Methoden, um das Modell zu bewerten, und predict-Methoden, um Vorhersagen zu machen.
Schätzer werden unterteilt in Classificators, Regressors und Clusterers. Ein Classificator bildet Klassifikationsalgorithmen ab, die die Gruppenzugehörigkeit einer Beobachtung vorhersagen. Ein Regressor bildet Regressionsalgorithmen ab, die aus bekannten Daten numerische Werte schätzen.
Scikit-Learn Übersicht
Das abgebildete UML-Klassendiagramm zeigt einen Auszug aus der Scikit-Learn Klassenhierarchie, mit den Abhängigkeiten, Attributen und Methoden der Scikit-Learn Schätzer DecisionTreeClassifier, RandomForestClassifier, DecisionRegressor, RandomForestRegressor, KMeans und AgglomerativeClustering.
Die Schätzer der Scikit-Learn Bibliothek haben eine gemeinsame Basisklasse BaseEstimator und erben bzw. erweitern deren fit-Methode. Weitere gemeinsame Methoden mit einheitlicher Bezeichnung sind score für die Berechnung von Bewertungskriterien und predict für das Erstellen von Vorhersagen.
Scikit-Learn Schätzer werden über Parameter konfiguriert, diese sind vom jeweiligen Algorithmus abhängig. Ein DecisionTreeClassifier hat z.B. die Parameter criterion, splitter, max_depth [...], die festlegen, wie genau ein Entscheidungsbaum-Modell aufgebaut wird.

Scikit-Learn Anwendung: Ausfall-Klassifikation
Das Beispiel "Ausfall-Klassifikation in Abhängigkeit von Temperatur und Feuchtigkeit" zeigt den Ablauf beim Trainieren eines Entscheidungsbaum-Modells für die Klassifikation von Ausfällen mit Hilfe der Python-Bibliotheken Scikit-Learn, NumPy, Pandas und Matplotlib. Hier wird als Schätzer der DecisionTreeClassifier eingesetzt.
Die Frage, die mit diesem Entscheidungsbaum-Modell beantwortet werden soll, lautet: bei welcher Kombination von Merkmalen tritt ein Ausfall ein?
Datei mit Messwerten: daten.csv
Die CSV-Datei daten.csv enthält Messwerte in 4 Spalten: id, Temperatur (temp), Feuchtigkeit (feucht), ausfall.
Die erste Zeile enthält die Spaltenüberschriften.
Die id-Spalte enthält die Zeilenüberschriften, in diesem Fall lediglich eine fortlaufende
eindeutige Nummerierung. Die vorhandenen Daten werden zum Trainieren und Validieren / Testen eines Entscheidungsbaum-Modells verwendet.
Daten als CSV-Datei daten.csv
id;temp;feucht;ausfall 1;40;10;ja 2;41;0;ja 3;39;60;ja 4;40;60;ja 5;20;60;ja 6;21;11;nein 7;20;10;nein 8;18;11;nein 9;20;10;nein 10;19;12;nein 11;20;10;nein 12;20;10;nein 13;21;15;nein 14;20;10;nein 15;17;14;nein
Interpretation der Daten
Eine Zeile stellt eine Messung bzw. Beobachtung dar und ist wie folgt zu interpretieren: Bei der Messung 1 wurde temp=40 und feucht=10 gemessen und es ist ein Ausfall aufgetreten. Bei der Messung 6 wurde temp=21 und feucht=11 gemessen und es ist kein Ausfall aufgetreten.
Die Spalten temp und feucht sind in der Sprache der Statistik Merkmale (features), die Spalte ausfall ist die Zielvariable, für die man aus den bekannten Vergangenheitsdaten Vorhersagen für neue Daten treffen möchte.
Vorbereitung: Verzeichnisstruktur und Paketinstallation
Als Vorbereitung wird die Verzeichnisstruktur für das Beispiel erstellt und
ggf. benötigte Pakete installiert.
Die Verzeichnisstruktur für dies Beispiel ist wie folgt. In der Entwicklungsumgebung Visual Studio Code den Ordner scikitlearn-tutorial öffnen und die beiden Dateien daten.csv und my-classifier.py darin anlegen.
├─ scikitlearn-tutorial │ ├─ daten.csv │ ├─ my-classifier.py
Scikit-Learn und andere benötigten Pakete (Pandas, NumPy, Matplotlib) müssen dann installiert werden, wenn man sie zuvor noch nicht verwendet hat. In Visual Studio Code wird dies wie alle Python-Installationen im Terminal-Fenster durchgeführt, durch Aufrufen des Paketmanagers pip.
pip install scikit-learn pip install pandas pip install numpy
Weitere Informationen zur Installation von Python-Paketen und Verwendung des
Paketmanagement-Tools pip finden Sie hier:
Python-Tutorial Teil 2: Pakete installieren.
Entscheidungsbaum-Modell trainieren
Im ersten Schritt werden die Daten eingelesen, die Merkmale und Zielvariable werden
aus den Spalten extrahiert, das Entscheidungsbaum-Modell wird trainiert, d.h. es
wird ein Modell erstellt, das zu den vorhandenen Daten passt, und schließlich visualisiert.
import pandas as pdimport matplotlib.pyplot as pltfrom sklearn.model_selection import train_test_splitfrom sklearn.tree import DecisionTreeClassifier, plot_treedf = pd.read_csv("https://www.elab2go.de/demo-py1/daten/daten.csv", index_col=0, header=0, sep = ";")print('Daten:\n', df);# Extrahiere Merkmale in ein Numpy-Array xX = df.iloc[:,0:2].to_numpy()# Extrahiere Zielvariable in ein Numpy-Array yy = df[['ausfall']]; y = y.values;# 80% Trainingsdaten und 20% TestdatenX_train, X_test, y_train, y_test =train_test_split(X, y, test_size=0.2, random_state=1)# Erzeuge Entscheidungsbaummodel = DecisionTreeClassifier(criterion='entropy', splitter='best')model.fit(X_train, y_train)# Visualisiere Entscheidungsbaumfig, ax = plt.subplots(figsize=(5, 5))plot_tree(model, filled=True, feature_names=df.columns[0:2],class_names=['ja','nein'])plt.show()
Erläuterung des Codes
- Daten einlesen, Zeile 5
Die Daten werden mit Hilfe der Pandas-Funktion read_csv aus der Datei daten.csv eingelesen. Der Parameter index_col=0 legt fest, dass die erste Spalte als Zeilenüberschrift interpretiert wird. - Merkmale und Zielvariable extrahieren (Zeile 7-11)
Die Merkmals-Spalten temp und feucht werden mittels der Pandas-Funktionen iloc und to_numpy in ein NumPy-Array X extrahiert. Die Zielvariable ausfall wird ein NumPy-Array y extrahiert. - Aufteilen in Trainings- und Validierungsdaten (Zeile 12-13)
Die Funktion train_test_split wird verwendet, um Merkmale und Zielvariablen jeweils in einen Trainings- und einen Testdatensatz aufzuteilen. Hier werden jeweils 80% der Daten für das Training und 20% der Daten für die Validierung verwendet. - Modell erstellen und mitfit trainieren (Zeile 15-16)
Bei der Erstellung eines neuen DecisionTreeClassifier-Modells werden eine Reihe von Parametern übergeben. Der Entscheidungsbaum wird so aufgebaut, dass die Daten von der Wurzel ausgehend in Teilmengen / Kindknoten aufgeteilt werden, wobei ein Knoten möglichst viele Daten derselben Klasse haben sollte. Für die Aufteilung können zwei Kriterien herangezogen werden, Entropie oder Gini-Index. Eine hohe Entropie bedeutet: geringer Informationsgehalt des Knotens bzw. inhomogener Knoten. Entropie gleich Null bedeutet: alle Beobachtungen des Knotens sind in derselben Kategorie / Klasse. - Visualisierung des Entscheidungsbaums (Zeile 17-20)
Verwendete Funktion: plot_tree()
Die Funktion plot_tree aus dem Paket sklearn.tree wird für die Visualisierung des Entscheidungsbaums verwendet. Sie erwartet als Parameter die Merkmalsspalten (feature_names=df.columns[0:2]) und die Namen der Klassen (class_names=['ja','nein']), d.h. die Ausprägungen der Zielvariablen, so wie sie auch im Datensatz verwendet wurden.
Merkmale
[[40 10] [41 0] [39 60] ... [21 15] [20 10] [17 14]]
Zielvariable
[['ja'] ['ja'] ['ja'] ... ['nein'] ['nein'] ['nein']]
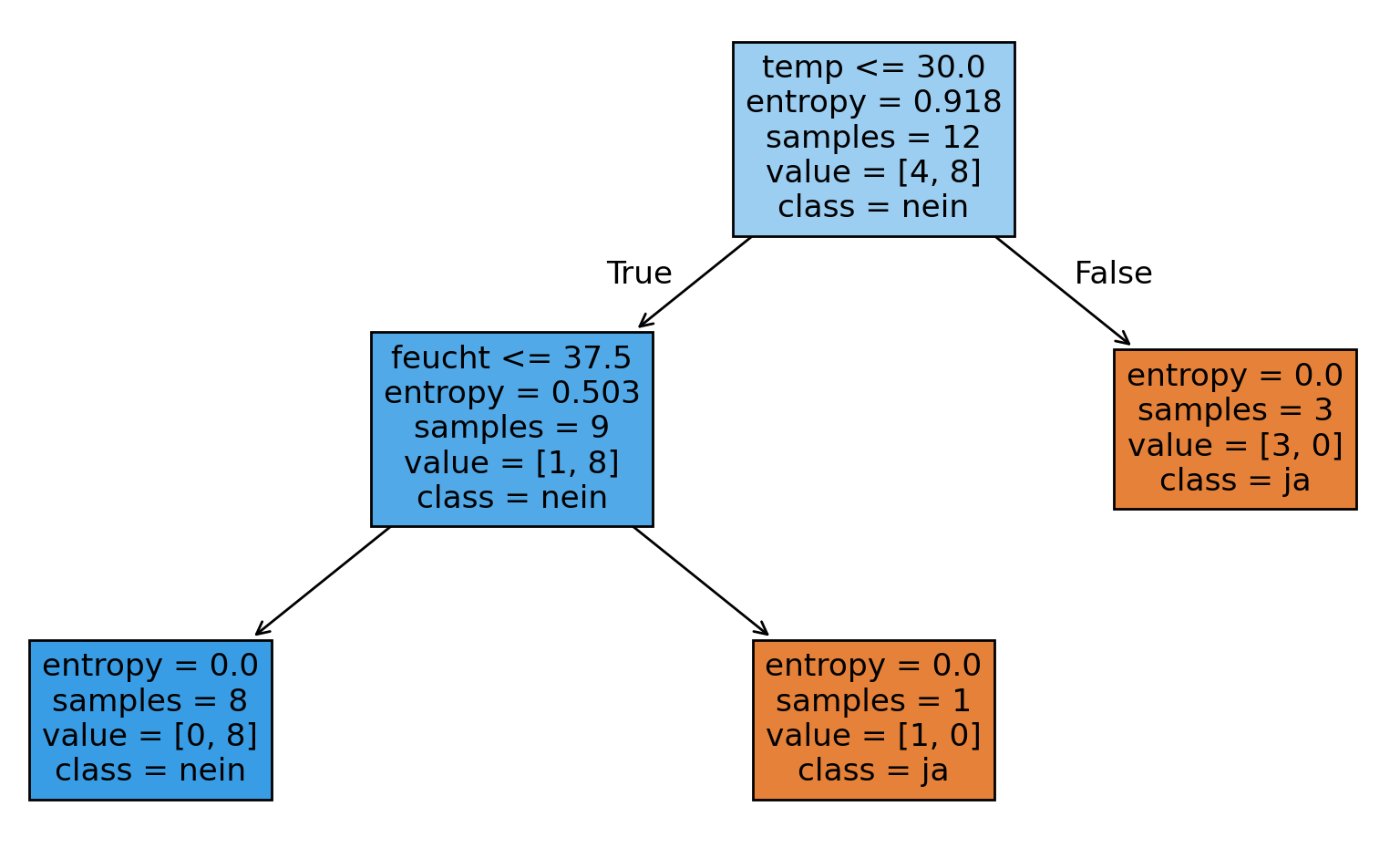
Visualisierung des Entscheidungsbaums
Wie kann der Entscheidungsbaum interpretiert werden?
Wir erkennen, dass die Wurzel des Entscheidungsbaums den Datensatz in zwei Teile aufteilt:
Beobachtungen mit Temperatur > 30.0 führen direkt zu einem Ausfall.
Die 12 Beobachtungen mit Temperatur <= 30.0 führen in den linken Zweig, hier werden sie
abhängig von der Feuchtigkeit noch weiter verzweigt.
Am Entscheidungsbaum kann abgelesen werden, dass Ausfälle auftreten, wenn entweder Temperatur
oder Feuchtigkeit über einem bestimmten Wert liegen.
Vorhersage / Klassifikation mittels Entscheidungsbaum
Die Aufgabe eines Entscheidungsbaum-Modells besteht darin, eine Vorhersage (eigentlich: Klassifikation) für neue noch nicht bewertete Daten zu erstellen. Vorhersagen bzw. Klassifikationen werden in Python mittels der Scikit-Learn-Funktion predict durchgeführt.
Eine Vorhersage kann durch unterschiedliche Performance-Kennzahlen bzw. Metriken bewertet werden, im Falle des Entscheidungsbaums z.B. mit Vertrauenswahrscheinlichkeit (accuracy), Genauigkeit (recision) und Trefferquote (recall).
my-classifier.py Teil 2: Vorhersage mit predict
Im zweiten Teil des Python-Skripts wird eine Vorhersage auf dem Test-Anteil X_test
des ursprünglichen Datensatzes ausgeführt,
da für diese Daten die tatsächlichen Bewertungen ("ja", "nein") schon bekannt sind.
Die Erwartung ist hier, dass alle Ausfälle korrekt klassifiziert werden.
print('Test-Daten X_test:\n', X_test)y_pred = model.predict(X_test)print('Vorhersage y_pred:\n', y_pred)from sklearn.metrics import accuracy_score, precision_score, recall_scoreprint('PERFORMANCE-KENNZAHLEN:')# Vertrauenswahrscheinlichkeitprint("Accuracy: %.2f%%" %(100 * accuracy_score(y_test, y_pred)))# Genauigkeitprint("Precision: %.2f%%" %(100 * precision_score(y_test, y_pred, pos_label='ja', average='binary')))# Trefferquoteprint("Recall: %.2f%%" %(100 * recall_score(y_test, y_pred, pos_label='ja', average='binary')))
Ausgabe
Test-Daten X_test: [[40 60] [18 11] [20 10]] Vorhersage y_pred: ['ja' 'nein' 'nein'] PERFORMANCE-KENNZAHLEN: Accuracy: 100.00%, Precision: 100.00%, Recall: 100.00%
Entscheidungsbaum-Modell evaluieren
In diesem Schritt wird die Güte des Modells mittels unterschiedlichen Kennzahlen und Verfahren bewertet. Eine häufig verwendetes Evaluierungs-Verfahren ist die Kreuzvalidierung. Für die k-fache Kreuzvalidierung werden die Daten in k gleich große Teildatensätze zerlegt. Training und Evaluation werden k-mal durchgeführt, wobei in dem k-ten Schritt der k-te Teildatensatz für die Validierung und die anderen k-1 Teile als Trainingsdaten verwendet werden. Ergebnis der Kreuzvalidierung sind die gemittelten Kennzahlen.
my-classifier.py Teil 3: Kreuzvalidierung mit cross_val_score
Die Funktion cross_val_score führt die Kreuzvalidierung an dem kompletten Datensatz durch.
Als Parameter erhält sie das zuvor erstellte Entscheidungsbaum-Modell model,
die Merkmale X und Zielvariable y, die Anzahl der Folds (hier: cv = 3) und das zu verwendende
Performance-Kriterium (hier: accuracy).
Man erhält als Rückgabewert ein NumPy-Array mit cv = 3 Werten, da die Performance-Kennzahl für jeden Durchlauf
berechnet wird. Die gemittelte Performance-Kennzahl accuracy hat demnach den Wert 0.8 = (0.6 + 1 + 0.8) / 3.
from sklearn.model_selection import cross_val_scoreimport numpy as npscores = cross_val_score(model, X, y, cv=3, scoring='accuracy')print('Kreuzvalidierung\nAccuracy-Array: ', scores)print('Accuracy, gemittelt:', np.mean(scores))
Ausgabe
Kreuzvalidierung Accuracy-Array: [0.6 1. 0.8] Accuracy, gemittelt: 0.80000000
my-classifier.py Teil 4: Kreuzvalidierung mit cross_validate
Die Funktion cross_validate führt ebenfalls die Kreuzvalidierung durch,
ermöglicht jedoch die gleichzeitige Auswertung mehrerer Performance-Kennzahlen.
from sklearn.model_selection import cross_validatescores = cross_validate(model, X, y, cv=3, return_train_score=True)print('cross_validate train_score:\n', scores.get('train_score'))print('cross_validate test_score:\n', scores.get('test_score'))
Ausgabe
cross_validate train_score: [1. 1. 1.] cross_validate test_score: [0.6 1. 0.8]
Weitere Scikit-Learn Anwendungsbeispiele
Ein weiteres Anwendungsbeispiel für den Einsatz von Entscheidungsbäumen ist in
Demo-PY4: Predictive Maintenance mit scikit-learn
beschrieben.
2-2 Keras - Deep Learning
Keras ist ein Python-Paket, das als benutzerfreundliche Programmierschnittstelle für verschiedene Machine Learning Frameworks wie Tensorflow, PyTorch und JAX verwendet wird.
Keras bietet zum Erstellen eines neuronalen Netzwerks zwei Klassen: Sequential und Functional,
die beide die Erstellung mehrschichtiger Netzwerke unterstützen.
Die Sequential-API ermöglicht das sequentielle Zusammenzufügen von Schichten (Layer), während mit Hilfe der Functional-API
komplexere Anordnungen von Schichten erstellt werden können.
Die Schichten eines Künstlichen Neuronalen Netzwerks sind in Keras durch die Klassen der Layer-API realisiert:
Conv2D, MaxPooling2D, Flatten, Dense, LSTM etc.
Jede Layer-Klasse hat eine Gewichtsmatrix, eine Größenangabe für die Anzahl verwendeter Neuronen (units),
eine Formatbeschreibung der Eingabedaten (input_shape), eine Aktivierungsfunktion (activation), und eine Reihe weiterer Parameter,
die die Gestaltung der Schicht steuern.
Die üblichen Schritte beim Erstellen eines Neuronalen Netzwerks (Modell erstellen, Modell trainieren, Modell validieren und verwenden) werden in
Keras mit Hilfe der Funktionen compile(), fit() und predict() durchgeführt.
2-3 Tensorflow - Deep Learning
Tensorflow ist ein Framework für Machine Learning, das insbesondere für Anwendungen in der Bild- und Spracherkennung genutzt wird. Tensorflow bietet Programmierschnittstellen für verschiedene Programmiersprachen an, insbesondere Python, Java und C++, davon ist die meistgenutzte und stabilste Schnittstelle die Python API. Die Dokumentation der Tensorflow-API ist umfangreich und die zur Verfügung gestellten Beispiele können durch Ausführung der verlinkten Colab-Notebooks praktisch nachvollzogen werden.
Tensorflow wird zunächst für Aufgaben in der Bild- und Videobearbeitung eingesetzt, sowohl für Aufgaben der Bilderkennung (ist ein Objekt da?) als auch der Bild-Klassifikation (um welches Objekt handelt es sich?). Das Trainieren eines Modells in der Bildklassifikation ist sehr aufwendig - hier kann man mit Tensorflow auf vortrainierte Modelle zurückgreifen und einfach diese für die Klassifikation verwenden.
https://www.tensorflow.org/guide/tensorimport tensorflow as tfimport numpy as nprank_3_tensor = tf.constant([[[0, 1, 2, 3, 4],[5, 6, 7, 8, 9]],[[10, 11, 12, 13, 14],[15, 16, 17, 18, 19]],[[20, 21, 22, 23, 24],[25, 26, 27, 28, 29]],])print(rank_3_tensor)
2-4 Bilderkennung mit Keras und Tensorflow
Das Anwendungsbeispiel "Bilderkennung" zeigt,
wie ein Künstliches Neuronales Netzwerk für die Ziffernerkennung mit Hilfe von Keras trainiert
und für die Klassifikation verwendet wird.
Ziel ist, ein Modell zu erstellen und zu trainieren, das handgeschriebene
Ziffern (grau-weiß-Bilder im Format 28x28 Pixel, die die Ziffern 0,1,2,...,9 darstellen) korrekt klassifizieren kann.
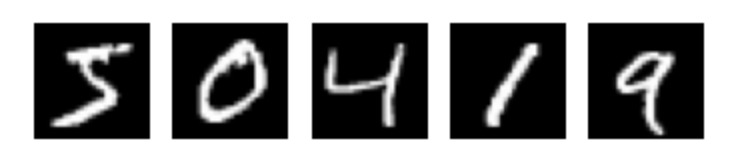
Dies Beispiel für Ziffernerkennung ist an das Simple MNIST convnet aus der Sammlung der Keras-Codebeispiele angelehnt. Der vollständige Quellcode mit zusätzlichen Erläuterungen ist als Google Colab Notebook online verfügbar.
Schritt 1: Daten einlesen und vorbereiten
Als Trainings- und Validierungsdatensatz werden 60.000 Ziffern-Bilder aus dem MNIST-Ziffern-Datensatz verwendet.
Der MNIST-Ziffern Datensatz kann direkt über Keras geladen werden.
Die Datenvorbereitung bedeutet, dass die
Bild-Daten in eine vorgegebene numerische Form umgewandelt, normalisiert und codiert werden müssen.
Verwendete Funktionen: load_data(), reshape(), to_categorical()
Ausgabeimport numpy as npimport matplotlib.pyplot as pltfrom keras.datasets import mnistfrom keras.utils import to_categorical, plot_modelfrom keras.models import Sequentialfrom keras.layers import Conv2D, MaxPooling2D, Dense, Flattenprint("1. Lade MNIST-Datensatz")(trainX, trainY), (testX, testY) = mnist.load_data()# Ausgabe der Dimensionen des Datensatzesprint('Train: X=%s, Y=%s' % (trainX.shape, trainY.shape))print('Test: X=%s, Y=%s' % (testX.shape, testY.shape))print("2. Datenvorbereitung")trainX = trainX.reshape((trainX.shape[0], 28, 28, 1))testX = testX.reshape((testX.shape[0], 28, 28, 1))# Daten werden in den Bereich [0, 1] normalisierttrainX = trainX.astype("float32") / 255.0testX = testX.astype("float32") / 255.0# Zielvariable wird numerisch codierttrainY = to_categorical(trainY)testY = to_categorical(testY)print('Train: X=%s, Y=%s' % (trainX.shape, trainY.shape))print('Test: X=%s, Y=%s' % (testX.shape, testY.shape))

Schritt 2: Modell definieren und trainieren
In diesem Schritt wird ein Deep Learning-Modell erstellt, für die Trainingsphase konfiguriert
und anschließend anhand der zuvor festgelegten Trainingsdaten trainiert.
Das Modell wird durch Hinzufügen passender Schichten erstellt. Für jede Schicht kann eine Aktivierungsfunktion angegeben werden.
Verwendete Klassen: Sequential, Conv2D, MaxPooling2D, Flatten, Dense
Verwendete Methoden: compile(), summary(), fit(), save()
Ausgabe# Definiere das Modellprint("3. Definiere das Modell")model = Sequential()model.add(Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)))model.add(MaxPooling2D((2, 2)))model.add(Conv2D(64, (3, 3), activation='relu'))model.add(MaxPooling2D((2, 2)))model.add(Flatten())model.add(Dense(10, activation='softmax'))model.compile(loss='categorical_crossentropy', metrics=['accuracy'])model.summary()# Trainiere das Modellprint("4. Trainiere das Modell\n")model.fit(trainX, trainY, epochs=8, batch_size=64, verbose=2)# Speichere das Modellmodel.save('digits_model.keras')


Schritt 3: Modell evaluieren
In diesem Schritt wird die Güte des Modells bestimmt, dabei werden die Indikatoren loss und accuracy (Vertrauenswahrscheinlichkeit) verwendet.
Mit Hilfe des Parameters loss wurde bei Erstellung konfiguriert, welche Performance-Metrik während des Trainings minimiert werden soll.
Die Vertrauenswahrscheinlichkeit ist die Wahrscheinlichkeit, dass für eine Beobachtung eine richtige Vorhersage getroffen wird.
Verwendete Funktionen: evaluate()
score = model.evaluate(testX, testY, verbose=0)print("Test loss:", score[0]) # Ausgabe: Test loss: 0.03print("Test accuracy:", score[1]) # Ausgabe: Test accuracy: 0.99
Schritt 4: Modell für die Klassifikation neuer Bilder verwenden
In diesem Schritt wird das zuvor erstellte Modell verwendet, um neue Bilder korrekt zu klassifizieren.
4-1 Bild laden
Zunächst muss das zu klassifizierende Bild geladen und numerisch dargestellt werden.
Konkret wird hier ein Bild, das die Ziffer 5 darstellt, aus einer URL
geladen und in die von dem Modell benötigte numerische Darstellung umgewandelt.
Die selbstdefinierte Funktion prepare_image() hat die Aufgabe, ein als URL übergebenes
Bild zu laden und numerisch codiert als NumPy-Array darzustellen.
Verwendete Funktionen: load_img(), img_to_array()
from keras.preprocessing import imagefrom keras.utils import get_filedef prepare_image(img_url):'''Funktion lädt ein Bild aus einer URLund stellt es numerisch codiert als NumPy-Array dar'''img = Nonetry:file = get_file('fname',img_url) # Lade die Datei aus der URL in eine lokale Datei# Lade Bild im PIL-Format, 28x28 Pixelimg = image.load_img(file, color_mode = 'grayscale', target_size=(28, 28))# Wandle es in ein Array umimg = image.img_to_array(img)img = img.reshape(1, 28, 28, 1)img = img.astype('float32') / 255.0except Exception as error:print("Error: %s" % error)return img# Test-Bild laden und codieren: digit-5 kann ersetzt werden durch digit-7 etc.img_url = 'https://elab2go.de/demo-py1/images/digit-5.png'img = prepare_image(img_url)print(img) #
4-2 Modell laden und Vorhersage durchführen
Das Modell wird aus der zuvor gespeicherten *.keras Datei geladen.
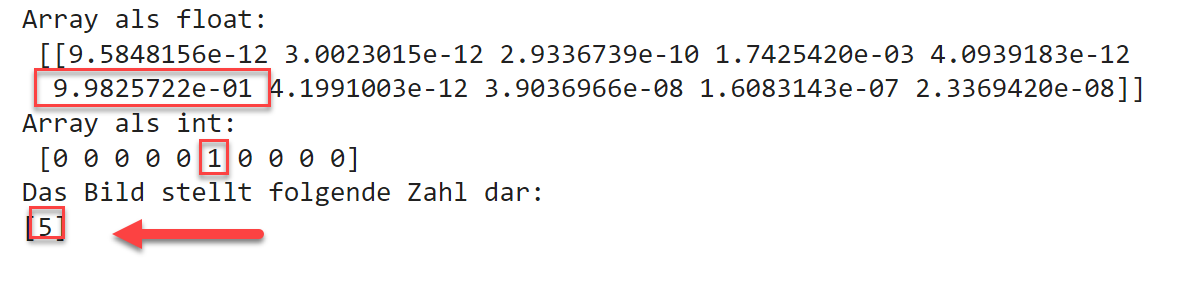
Die Klassifikation mittels der predict-Funktion liefert als Ergebnis ein NumPy-Array aus 9 Werten zurück,
wobei eine 1 an der Stelle i bedeutet, dass das Bild als Zahl i klassifiziert wurde
(hier: [0,0,0,0,1,0,0,0,0] wird als 5 interpretiert.
Verwendete Funktionen: load_model(), predict()
Ausgabe für das Bild digit-5.pngfrom keras.models import load_model# Modell aus Datei ladenmodel = load_model('digits_model.keras')# Vorhersage / Klassifikation erstellenarr = model.predict(img)# Das Ergebnis ist ein Array z.B. [0,0,0,0,1,0,0,0,0]print("Array als float:\n", arr)# Konvertiere digit_arr in ein ganzzahliges Arrayarr = (np.rint(arr[0])).astype(int)print("Array als int:\n", arr)print("Das Bild stellt folgende Zahl dar:")print(np.where(arr == 1)[0])
Zusammenfassung
Während in Teil 1 des Python-Tutorials die grundlegende Python-Syntax beschrieben wurde, beschäftigt sich Teil 3 "Python Bibliotheken" mit ausgewählten Python-Bibliotheken für Datenanalyse und Machine Learning: NumPy, Matplotlib, Pandas, Scikit-Learn, Keras, Tensorflow. Für jede der angeführten Bibliotheken werden die wichtigsten Funktionen beschrieben und einige repräsentative Code-Beispiele gegeben.
Quizzes: Python Listen und NumPy Arrays
Testen Sie Ihr Grundverständnis über die Verwendung von Python Listen und NumPy Arrays mit den folgenden Quizzes.
Themen: Python Listen und NumPy Arrays.
Python-Listen speichern Daten beliebigen Datentyps dynamisch und unterstützen effiziente
Operationen wie Einfügen, Anhängen, Sortieren, Umkehren usw.
NumPy-Arrays speichern Daten desselben Datentyps und bieten elementweise Operationen
und statistischen Funktionen, sowie das Erstellen von Sequenzen, Zufallszahlen und mehrdimensionalen Arrays.
Quiz "NumPy 1D-Arrays" (5 Fragen)
Quiz "NumPy 2D-Arrays" (5 Fragen)
Nächste Schritte
Die Anleitung Installation Python und Anaconda beschreibt die Installation und Verwendung der Paketverwaltungsplattform Anaconda, als Hilfsmittel für Python-Programmierung im Rahmen des Maschinellen Lernens. Anaconda bietet eine grafische Benutzeroberfläche zum Installieren von Python-Tools und -Paketen, sowie zum Erstellen virtueller Environments.
In Python Tutorial Teil 2: Pakete installieren wird beschrieben, wie man mit Hilfe der Paketverwaltungssysteme pip und conda Python-Pakete installiert, aktualisiert und deinstalliert, wie man für verschiedene Projekte passende Anwendungsumgebungen ("environments") erstellt und wie man die installierten Pakete in Python-Skripten mit Hilfe der import-Anweisung korrekt importiert. Die Entwicklung selbstdefinierter Pakete, mit deren Hilfe man größere Projekte strukturieren kann, wird an einem Beispiel vorgestellt.
Teil 4: Kryptographie dieses kompakten Python-Tutorials gibt eine Übersicht über die wichtigsten Pakete für Kryptographie. Zunächst wird die Python-Bibliothek PyCryptodome vorgestellt, mit Beispielen für drei verschiedenen Betriebsmodi der AES-Verschlüsselung, und einem Beispiel, wie RSA und AES zusammen für die sichere Datenübertragung eingesetzt werden. Anschließend werden verschiedene Pakete für Hashing und Message Authentication Codes am Beispiel vorgestellt: hashlib und hmac für einfaches Hashing, sowie bcrypt für Passwort-Hashing.
Demo-PY2: Datenverwaltung und -Visualisierung mit Pandas zeigt am Beispiel eines Zeitreihen-Datensatzes zum Stromverbrauch in Deutschland, wie die Datenverwaltung und - visualisierung mit Hilfe der Python-Bibliotheken Pandas und Matplotlib durchgeführt wird. Die Daten werden in der interaktiven, webbasierten Anwendungsumgebung Jupyter Notebook analysiert.
Demo-PY3: Clusteranalyse mit scikit-learn zeigt am Beispiel eines Mini-Datensatzes mit Raumklima-Messungen, wie eine Clusteranalyse mit Hilfe der Python-Bibliothek Scikit-Learn für maschinelles Lernen durchgeführt wird.
Autoren, Tools und Quellen
Autor:
Prof. Dr. Eva Maria Kiss
Tools:
- Python: python.org/
- Anaconda: anaconda.com/
- Jupyter Notebook / JupyterLab: jupyter.org/
- Visual Studio Code (VSCode): code.visualstudio.com/
- Spyder: spyder-ide.org/
elab2go-Links
- [1] Datenverwaltung und -Visualisierung mit Pandas: elab2go.de/demo-py2/
- [2] Clusteranalyse mit scikit-learn: elab2go.de/demo-py3/
- [3] Predictive Maintenance mit scikit-learn: elab2go.de/demo-py4/
- [4] Machine Learning mit Keras und Tensorflow: elab2go.de/demo-py5/
Quellen und weiterführende Links
- [1] Offizielle Python Dokumentation bei python.org: docs.python.org/3/tutorial/
sehr umfangreich, Nachschlagewerk, hier findet man Dokumentationen für verschiedene Python-Versionen - [2] Python Tutorial: evamariakiss.de/tutorial/python/ – zum Nachschlagen der wichtigsten Python-Befehle, mit Selbsttest / Quiz
- [3] NumPy: numpy.org/ – Mehrdimensionale Arrays, Mathematische Funktionen, Zufallszahlen
- [4] Matplotlib: matplotlib.org/ – Datenvisualisierung, Plotten
- [5] Pandas: pandas.pydata.org/ – Datenverwaltung, Datenvorbereitung, DataFrames, Series
- [6] Scikit-Learn: scikit-learn.org – Algorithmen für Maschinelles Lernen
- [7] Keras: keras.io – Künstliche Neuronale Netzwerke, Deep Learning