Demo-R2: Datenverwaltung mit dem R-Paket stats
Nachdem in Demo-R1: R-Tutorial
der erste Einstieg in die Syntax der Programmiersprache R erfolgt ist, zeigt Demo-R2 im nächsten Schritt, wie
die Datenverwaltung und - visualisierung mit Hilfe der R-Pakete stats
und graphics durchgeführt wird.
Ein Zeitreihen-Datensatz zum Stromverbrauch in Deutschland aus der Open-Power-System-Data (OPSD)-Plattform
dient uns dabei als Anwendungsbeispiel.
Die Daten werden in einer interaktiven
Shiny-App analysiert.
Demo 4: Teil 2: Erstellung einer interaktiven Shiny-App mit RStudio bietet eine
Schritt-für-Schritt-Anleitung zur Erstellung und Ausführung einer Shiny-App.
Motivation
Bei der Datenanalyse ist das Einlesen und Aufbereiten der Daten der erste und aufwendigste Schritt, da die Daten selten in der benötigten Form schon vorliegen. In vielen Fällen enthält die externe Datenquelle (z.B. eine CSV-Datei) mehr Daten als benötigt werden, oder einzelne Datenwerte fehlen, oder haben das falsche Format.
R stellt neben dem base-Paket zwei leistungsfähige Pakete für die Verarbeitung und Visualisierung von Daten zur Verfügung: stats und graphics, deren typische Verwendung wir an einem konkreten Anwendungsfall veranschaulichen.
Warum stats?
stats
ist ein R-Paket, das alle wichtigen statistischen Methoden der deskriptiven, induktiven und explorativen Statistik.
In diesem Abschnitt wird dieses Paket eine zentrale Rolle spielen, da ein Zugriff auf die
R-Datenstruktur ("DataFrames") und eine Modifikationen dessen Variablen und Beobachtungen
durch die Funktionen dieses Paketes ermöglicht wird.
Die "aggregate"-Funktion zerlegt die Daten in ausgewählte Teildatensätze,
aggregiert deren Variablen oder Beobachtungen anhand einer Regel und gibt das Ergebnis zur Weiterverarbeitung wieder im
Teildatensatz aus.
Warum graphics?
graphics
ist eine R-Paket
für die graphische Darstellung von Daten und mathematischen Funktionen und vom Funktionsumfang her
vergleichbar mit MATLABs Plotting-Funktionen.
Die high-level Optionen sind dabei Befehle aus dem graphics-Paket, die ein Grafikfenster erstellen, durch Grafikargument
wird die Grafik z.B. um Achsenbeschriftungen und -grenzen oder Legenden ergänzt und so können graphische
Darstellungen verschönert und professioneller gestaltet werden. Low-level Grafikoptionen, wie lines() und points(),
ergänzen bestehende Grafiken und ermöglichen die Darstellung mehrerer Grafiken in einem Grafik-Fenster.
Übersicht
Demo-R2 ist in 4 Abschnitte gegliedert. Zunächst wird der OPSD-Datensatz beschrieben und die Fragestellung, die wir mit unserer Datenvisualisierung beantworten wollen.
Danach wird das notwendige Datensatz eingelesen und die Vorbereitung benötigter R-Pakete erläutert.
In den folgenden Abschnitten beschreiben wir die Datenverwaltung mit stats und Datenvisualisierung mit graphics.
1 Der OPSD-Datensatz
Open Power System Data ist eine offene Plattform für Energieforscher, die europaweit gesammelte Energiedaten in Form von csv-Dateien und sqlite-Datenbanken zur Verfügung stellt. Die Daten können kostenlos heruntergeladen und genutzt werden. Die Plattform wird von einem Konsortium (Europa-Universität Flensburg, TU Berlin, DIW Berlin und Neon Neue Energieökonomik) betrieben, mit dem Ziel, die Energieforschung zu unterstützen.
Für unsere Demo verwenden wir als Basis einen OPSD-Zeitreihen-Datensatz zur elektrischen Energieerzeugung in Deutschland für den Datenzeitraum: 01.01.2016 - 30.09.2020 mit einer stündlichen Auflösung.
Wir wollen Fragen beantworten wie: Wie ändert sich der Verbrauch von Strom insgesamt, Solar- und Windenergie über die Jahre? Wann im Laufe eines Jahres ist der Verbrauch am höchsten?
2 Data Frames und Pakete
Einen Einstieg in die Erzeugung und den Umgang mit dem R-Objekt "DataFrame" bietet
Teil 1: Variablen, Vektoren, Matrizen, regelmäßigen Folgen und Datensätze
der elab2go R-Tutorial-Reihe. In dieser Demo werden externe Daten mittels der read.csv2()-Funktion des utils-Paketes eingelesen. Ein DataFrame-Objekt ist
ein Objekt des base-Paketes und auf dieses können nützliche, im Verlauf der Demo vorgestellte, Funktionen zur
Datenverwaltung und - visualisierung mit Hilfe der R-Pakete stats
und graphics angewandt werden.
Dazu müssen im ersten Schritt die Pakete utils, lubridate, stats und graphics mit der library()-Funktion des base-Paketes eingelesen werden, dadurch stehen
alle Funktionen und Objekte dieser Pakete in der aktuellen R-Session zur Verfügung:
library(utils)library(stats)library(graphics)library(lubridate)
Das lubridate-Paket mit seinen Funktionen, z.B. second(), minute(), hour(), day(), yday(), mday(), wday(), week(), month() oder year(), erleichtert den Umgang mit Datums-Formaten, wie auch das base-Paket mit den Funktionen weekdays(), months() oder quarters().
3 Aufbereitung des OPSD-Datensatzes
Der OPSD-Datensatz, der in Form einer csv-Datei time_series_60min.csv vorliegt, wird nun mit Hilfe der oben genannten Pakete eingelesen, aufbereitet und tabellarisch ausgegeben.
3-1 Importieren der R-Pakete
Im ersten Schritt werden die Pakete utils, lubridate, stats und graphics mit der library()-Funktion des base-Paketes eingelesen werden, dadurch stehen alle Funktionen und Objekte dieser Pakete in der aktuellen R-Session zur Verfügung:
library(utils)library(stats)library(graphics)library(lubridate)
3-2 Daten einlesen
Die OPSD-Daten, die in der csv-Datei time_series_60min_xs.csv gespeichert sind, werden mit Hilfe der Funktion read.csv2() des utils-Paketes in die aktuelle R-Session eingelesen. Die Funktion read.csv2() speichert die tabellarisch vorliegenden Daten in ein DataFrame mit dem Namen dataVerbrauch.
- Zeile 2: Die Funktion read.csv2() wird mit drei Parametern aufgerufen. Als ersten Parameter übergeben wir den Namen der einzulesenden CSV-Datei. Mit dem zweiten Parametern header = TRUE legen wir fest, dass ein Header in der ersten Zeile der tabellarisch vorliegenden Daten eingelesen wird. Mit dem dritten Parameter sep = "," wird festgelegt, dass das Separationszeichen in der csv.Datei das Komma ist, default interpretiert read.csv2() das Komma auch als Dezimalzeichen.
- Zeile 4: Die Funktion head() zeigt die 6 Beobachtungen des Dataframes an.
# Lese CSV-Datei eindataVerbrauch=read.csv2("time_series_60min.csv",header = TRUE, sep = ",")# Zeige erste 6 Zeilen zur Kontrolle anhead(dataVerbrauch)
Die Ausgabe nach Ausführung dieses Quellcodes sieht ähnlich aus wie abgebildet.

3-3 Datenspalten auswählen
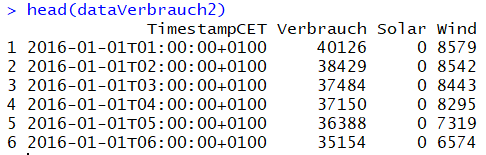
Wir benötigen aus der heruntergeladenen csv-Datei nur die Spalten TimestampCET, Verbrauch, Solar und Wind. dataVerbrauch[, c(2,3,5,7)] bedeutet, dass alle Zeilen, aber nur die Spalten 2, 3, 5 und 7 extrahiert werden. Der neue erzeugte Datensatz wird unter dem Namen dataVerbrauch2 abgespeichert.
# Behalte aus dem Datensatz nur die benötigten SpaltendataVerbrauch2=dataVerbrauch[, c(2,4,6,7)]# Zeige erste 6 Zeilen zur Kontrolle anhead(dataVerbrauch2)
Die Ausgabe nach Ausführung dieses Quellcodes sieht folgendermaßen aus:
3-4 Datenspalten durch 1000 teilen
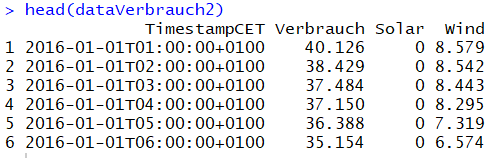
Die Verbrauchs-Spalten wird durch 1000 geteilt, dies stellt sicher, dass die Anzeige der Verbrauchsdaten in GWh erfolgt anstelle von MWh. Die Division erfolgt durch jeweiligen Spaltenaufruf mit dem $-Symbol und Anwendung der Rechenoperation auf die Spalte, die alte Spalte bekommt die neuen Wert zugewiesen.
# Formatierung in GWhdataVerbrauch2$Verbrauch= dataVerbrauch$Verbrauch/1000dataVerbrauch2$Solar= dataVerbrauch$Solar/1000dataVerbrauch2$Wind= dataVerbrauch$Wind/1000# Zeige erste 6 Zeilen zur Kontrolle anhead(dataVerbrauch2)
Die Ausgabe nach Ausführung dieses Quellcodes sieht folgendermaßen aus:
3-5 Extrahiere Jahr, Monat und Tag und Quartal aus der Datumsspalte
Wir fügen dem Datensatz dataVerbrauch2 fünf neue Spalten hinzu, indem wir aus der TimestampCET-Variablen des DataFrames dataVerbrauch2
die entsprechenden Datums-Bestandteile extrahieren.
Dazu muss mit der as.Date()-Funktion die Variable in ein bekanntes Datums-Format formatiert
werden. Die ersten 10 Zeichen werden aus der TimestampCET-Variablen extrahiert (substring(..,1,10)) und in ein Datum-Format umgewandelt (as.Date(..)), dieses Format
wird dann in der ersten Spalte des dataVerbrauch2-Datensatzes abgespeichert, d.h. die TimestampCET-Variable wird damit überschrieben.
Die einzelnen Bestandteile werden mit den Funktionen weekdays(), months() und quarters() des base-Paketes extrahiert oder mit dessen format()-Funktion,
wobei dieses Format dann als numerischer Wert unter den neuen Variablen abgespeichert wird (as.numeric(..)).
# Datenaufbereitung: DatumszerlegungdataVerbrauch2[,1]=as.Date(substring(dataVerbrauch$TimestampCET,1,10))dataVerbrauch2$day=weekdays(dataVerbrauch2$TimestampCET)dataVerbrauch2$month=months(dataVerbrauch2$TimestampCET)dataVerbrauch2$quarter=quarters(dataVerbrauch2$TimestampCET)dataVerbrauch2$year=as.numeric(format(dataVerbrauch2$TimestampCET, "%Y"))dataVerbrauch2$day2=as.numeric(format(dataVerbrauch2$TimestampCET, "%d"))# Zeige erste 6 Zeilen zur Kontrolle anhead(dataVerbrauch2)
Die Ausgabe nach Ausführung dieses Quellcodes sieht folgendermaßen aus:

3-6 Auswertungen auf täglicher, monatlicher und quartalsweiser Basis
Wir haben bisher die stündlichen Verbrauchswerte betrachtet, so wie sie in der heruntergeladenen Datei zur Verfügung gestellt waren. Für die Betrachtung eines größeren Zeitraums (Monate und Jahre) benötigen wir die Verbrauchswerte pro Tag, Monat und Quartal. Dazu werden die Daten entsprechend der Auflösung als tägliche, monatliche oder quartalsweise Daten aggregiert, dies erfolgt mit der aggrerate()-Funktion des stats-Paketes und unter den neuen Datensätzen data1, data2 und data3 abgespeichert.
Beispiel: tägliche Auflösung der Daten
- Zeile 3: Erzeuge einen Hilfsdatensatz mit Namen dd.
- Zeile 5, 6, 7: Für die Variablen Verbrauch, Wind und Solar wird jeweils die aggregate()-Funktion aufgerufen. Dabei bekommt die Funktion eine Formel, die Hilfsdaten dd und einen Parameter FUN=sum übergeben. FUN=sum bedeutet, dass die Werte, die über die Formel gruppiert wurden, summiert werden sollen. Die Formel, hier bei der täglichen Auflösung der Daten, lautet Variable ~ day2+month+year, d.h. für die angegebene Variable werden Gruppen mit gleichem Tag, Jahr und Monat erstellt, also eine tägliche Gruppierung erzeugt.
- Zeile 9: Die in der Formel verwendeten Datums-Bestandteile werden mit der paste()-Funktion zusammengefügt und als Datum (as.Date()) unter einer neuen Variablen date abgespeichert.
- Zeile 11: Die durch Aggregation erzeugten Variablen werden spaltenweise zusammengefügt und unter dem data1 abgespeichert.
- Zeile 12: Die Spalten des Datensatzes data1 werden umbenannt mittels der names()-Funktion.
- Zeile 14: Für die weitere grafische Darstellung werden die Daten sortiert, aufsteigend nach der date-Vaiablen.
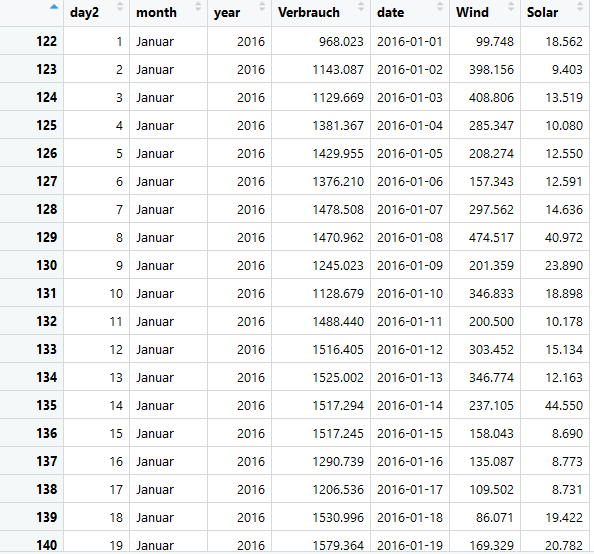
# Datenaufbereitung: Modifizierte Datensätze# tägliche Auflösung:dd=dataVerbrauch2dd.Verbrauch=aggregate(Verbrauch ~ day2+month+year, dd, FUN = sum)dd.Wind=aggregate(Wind ~ day2+month+year, dd, FUN = sum)dd.Solar=aggregate(Solar ~ day2+month+year, dd, FUN = sum)dd.Verbrauch$date=as.Date(paste(dd.Verbrauch$month,dd.Verbrauch$day2, dd.Verbrauch$year),format = "%B %d %Y")data1=cbind(dd.Verbrauch,dd.Wind$Wind,dd.Solar$Solar)names(data1)=c("day2","month","year","Verbrauch","date","Wind","Solar")data1=data1[order(data1$date),]
Ein Ausschnitt der auf täglicher Auflösung basierenden Daten, also von data1, sieht wie folgt aus:
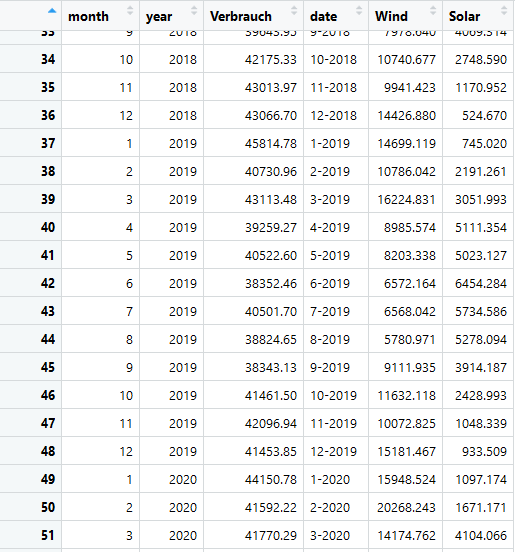
Hinweis: Die monatliche Gruppierung der Daten erfolgt mit aggregate(Verbrauch ~ month+year, dd, FUN = sum) und die quartalsweise Gruppierung mit aggregate(Verbrauch ~ quarter+year, dd, FUN = sum), also ändert sich im Vergleich zur täglichen Auflösung nur die Formel in der aggregate()-Funktion.
Ein Ausschnitt der monatlichen Auflösung und die quartalsweise Auflösung sehen wie folgt aus:
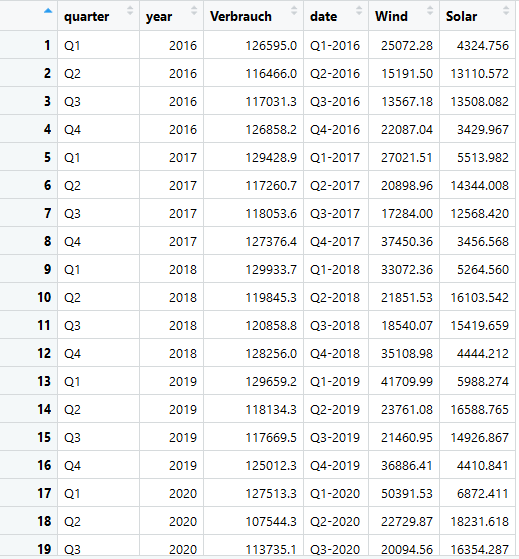
4 Datenvisualisierung mit graphics
Die plot()-Funktion des graphics-Paketes und deren Optionen werden verwendet um die aufbereiteten Stromverbrauchsdaten zu visualisieren. Mehr Informationen und eine Einführung die Erzeugung von Grafiken finden sich unter Teil 3: Grafiken und Zufallszahlen der elab2go R-Tutorial-Reihe.
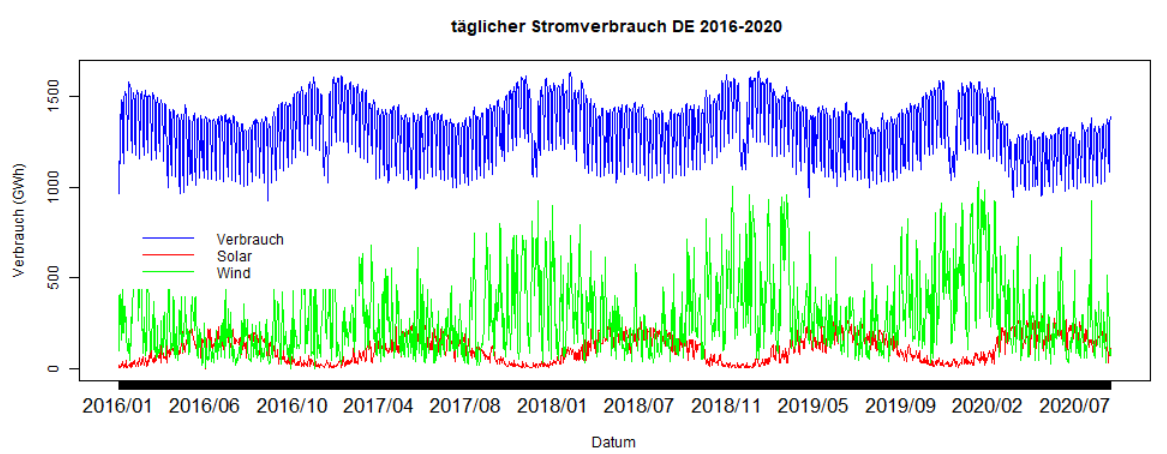
Datenvisualisierung 1: Entwicklung des täglichen Stromverbrauchs
Wir visualisieren die Spalten "Verbrauch", "Solar" und "Wind" des DataFrames "data1", d.h. den täglichen Stromverbrauch in Deutschland vom 01.01.2016 bis 30.09.2020.
- Zeile 1: Eine neue Variable d im Datumsformat wird erzeugt, deren Werte später als x-Werte in der Grafik verwendet werden.
- Zeile 3-6: Die Spalte "Verbrauch" wird mit Hilfe des plot-Befehls und desen Optionen grafisch dargestellt. Als Werte für die x-Koordinaten dient die Datumsvariable d.
- Zeilen 8, 9: Die Spalten "Solar" und "Wind" werden mit Hilfe des lines-Befehls in die bestehende Grafik eingefügt
- Zeilen 11-18: Lege Titel, Beschriftungen der Achsen und die Legende der Grafik fest.
data1$d= as.Date(data1$date, "%m/%d/%Y")plot(Verbrauch ~ d,data1,xaxt="n", type="l",xlab="Datum", ylab="Verbrauch (GWh)",ylim=c(0, max(data1$Verbrauch)),col="blue" )lines(Solar ~ d,data1, lty=1, col="red")lines(Wind ~ d,data1, lty=1, col="green")axis(1, data1$d, format(data1$d, "%Y/%m"), cex.axis = 1.4)text=paste(" täglicher Stromverbrauch DE 2016-2020")title(text)legend(data1$d[1], max(data1$Verbrauch)/2,legend=c("Verbrauch", "Solar","Wind"),lty=c(1,1,1),col=c("blue", "red", "green" ), box.lty=0)
Die Ausgabe nach Ausführung dieses Quellcodes sieht folgendermaßen aus:
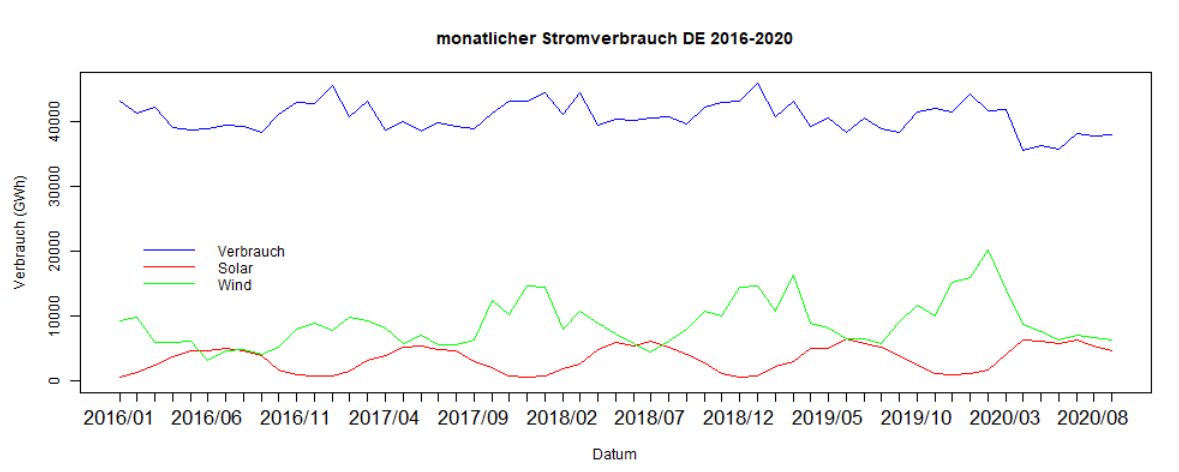
Datenvisualisierung 2: Entwicklung des monatlichen Stromverbrauchs
Im nächsten Schritt wollen wir sehen, wie sich der monatliche Verbrauch von Strom, Solar- und Windenergie von 2016 bis 2020 entwickelt hat. Als Datenquelle verwenden wir nun die aggregierten monatlichen Daten, d.h. den zuvor erstellten DataFrame "data2".
- Zeile 1-3: Eine neue Variable d im Datumsformat wird erzeugt, deren Werte später als x-Werte in der Grafik verwendet werden.
- Zeile 5-10: Plotte die Spalten "Verbrauch", "Solar" und "Wind" des DataFrames mit unterschiedlichen Farben in ein Grafikfenster.
- Zeile 12-19: Lege Titel, Beschriftungen der Achsen und die Legende der Grafik fest.
data1$d= as.Date(data1$date, "%m/%d/%Y")ax=seq(data1$d[1], data1$d[length(data1$d)], length.out=57)data2$d=axplot(Verbrauch ~ d,data2, type="l",xaxt="n", xlab="Datum", ylab="Verbrauch (GWh)",ylim=c(0, max(data2$Verbrauch)),col="blue")lines(Solar ~ d,data2, lty=1, col="red")lines(Wind ~ d,data2, lty=1, col="green")axis(1, data2$d, format(data2$d, "%Y/%m"), cex.axis = 1.4)text=paste("monatlicher Stromverbrauch DE 2016-2020")title(text)legend(data2$d[1], max(data2$Verbrauch)/2,legend=c("Verbrauch", "Solar","Wind"),lty=c(1,1,1), col=c("blue", "red", "green" ),box.lty=0)
Die Ausgabe nach Ausführung dieses Quellcodes sieht folgendermaßen aus:
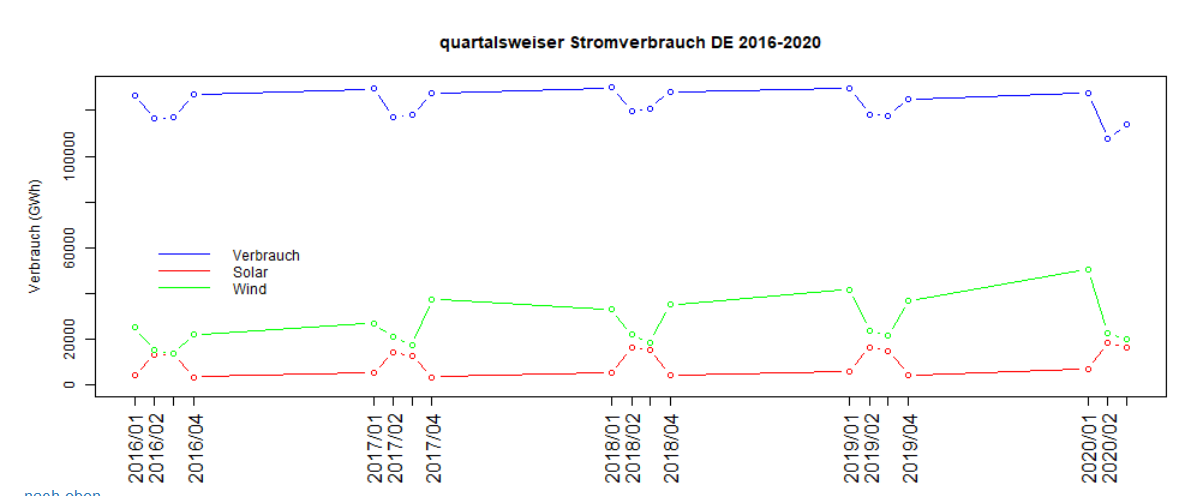
Datenvisualisierung 3: Entwicklung des quartalsweisen Stromverbrauchs
Im nächsten Schritt wollen wir sehen, wie sich der quartalsweise Verbrauch von Strom, Solar- und Windenergie von 2016 bis 2020 entwickelt hat. Als Datenquelle verwenden wir nun die aggregierten quartalsweisen Daten, d.h. den zuvor erstellten DataFrame "data3".
- Zeile 1-3: Eine neue Variable d im Datumsformat wird erzeugt, deren Werte später als x-Werte in der Grafik verwendet werden.
- Zeile 6-11: Plotte die Spalten "Verbrauch", "Solar" und "Wind" des DataFrames mit unterschiedlichen Farben in ein Grafikfenster.
- Zeile 13-19: Lege Titel, Beschriftungen der Achsen und die Legende der Grafik fest.
mydates <- as.Date(c("2016-01-01", "2016-02-01", "2016-03-01","2016-04-01","2017-01-01", "2017-02-01", "2017-03-01","2017-04-01","2018-01-01", "2018-02-01", "2018-03-01","2018-04-01","2019-01-01", "2019-02-01", "2019-03-01","2019-04-01","2020-01-01", "2020-02-01", "2020-03-01"))))data3$d=mydatesplot(Verbrauch ~ d,data3, type="b", xlab="", ylab="Verbrauch (GWh)",ylim=c(0, max(data3$Verbrauch)),col="blue", xaxt="n")lines(Solar ~ d,data3, type="b", lty=1, col="red")lines(Wind ~ d,data3, type="b", lty=1, col="green")text=paste("quartalsweiser Stromverbrauch DE 2016-2018")title(text)axis(1, data3$d, format(data3$d, "%Y/%m"), cex.axis = 1.4, las=2)legend(data3$d[1], max(data3$Verbrauch)/2,legend=c("Verbrauch", "Solar","Wind"), lty=c(1,1,1),col=c("blue", "red", "green" ), box.lty=0)
Die Ausgabe nach Ausführung dieses Quellcodes sieht folgendermaßen aus:
Detail-Ansicht: täglicher Stromverbrauch 2018
Wir verwenden wieder die plot()-Funktion des graphics-Paketes, um den täglichen Stromverbrauch des Jahres 2018 in einer eigenen Grafik darzustellen und somit eine detailreichere Darstellung zu erhalten.
subset1=subset(data1, data1$year ==2018)subset1$d= as.Date(subset1$date, "%m/%d/%Y")plot(Verbrauch ~ d,subset1,xaxt="n", type="l", xlab="Datum", ylab="Verbrauch (GWh)",ylim=c(min(subset1$Verbrauch), max(subset1$Verbrauch)),col="blue" )axis(1, subset1$d, format(subset1$d, "%Y/%m"), cex.axis = 1.4)text=paste(" täglicher Stromverbrauch DE 2018")title(text)
Die Ausgabe nach Ausführung dieses Quellcodes sieht folgendermaßen aus:
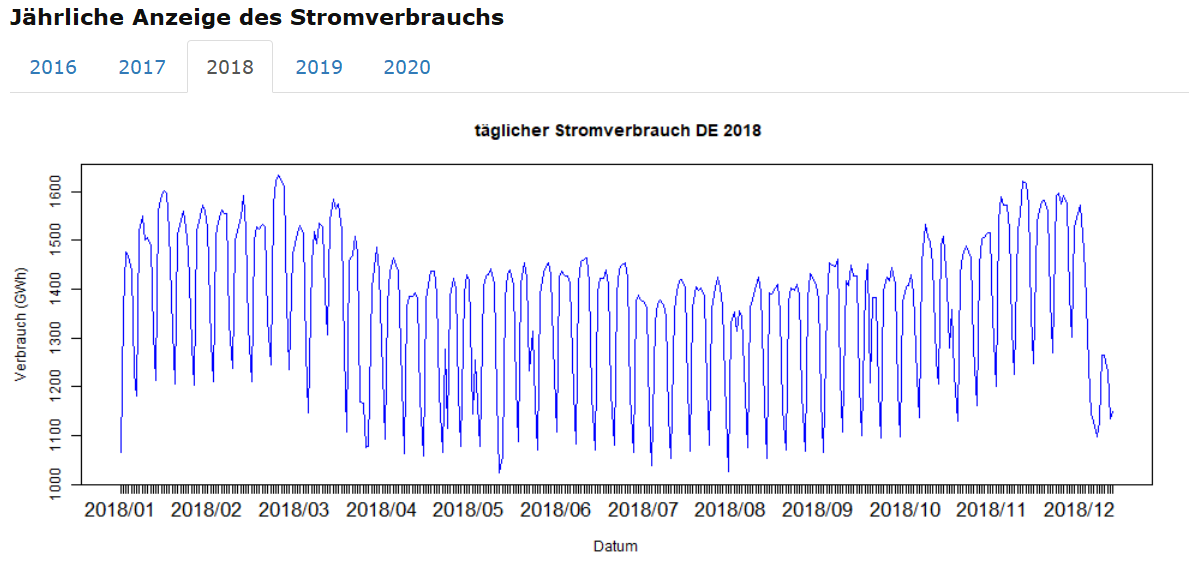
Die grafische Analyse des Stromverbrauchs: Fazit
- Die tägliche Anzeige zeigt den detailliertesten Verlauf der Verbrauchswerte und deren -abdeckung durch Wind und Solar.
- Die monatliche Anzeige gibt einen guten Einblick in den Trend der Verbrauchswerte und der -abdeckung durch Wind und Solar über die Jahre.
- Die quartalsweise Anzeige zeigt einen „gröberen“ Trend.
Die Solarproduktion mit den jahreszeitenabhängigen Schwankungen bleibt über die Jahre auf fast gleichem Niveau.
Die Produktion von Windenergie gerade in den Wintermonaten zeigt einen klaren Trend nach oben.

5 Grafik-App
Die oben beschriebenen Schritte, die zur Datenverwaltung und -visualisierung auf den Zeitreihen-Datensatz zum Stromverbrauch in Deutschland aus der Open-Power-System-Data (OPSD)-Plattform angewandt wurden, werden in der folgenden interaktiven R-Shiny App in der server-Datei ausgeführt und auf einer interkativen Benutzeroberfläche ausgegeben.
Autoren, Tools und Quellen
Autoren:
M. Sc. Anke Welz
Prof. Dr. Eva Maria Kiss
Tools:
R, RStudio,
Shiny Apps
Quellen und weiterführende Links
- R-Tutorial Teil 1: Variablen, Vektoren, Matrizen, regelmäßigen Folgen und Datensätze
- R-Tutorial Teil 2: Kontrollstrukturen und Funktionen
- R-Tutorial Teil 3: Grafiken und Zufallszahlen
- Demo 4: Teil 2: Erstellung einer interaktiven Shiny-App mit RStudio
- R-Dokumentation im Comprehensive R Archive Network (CRAN)