Demo-PY2: Interaktive Datenvisualisierung
von Stromverbrauchsdaten
Nachdem in Demo-PY1: Python Tutorial der erste Einstieg in die Python Syntax erfolgt ist, zeigt Demo-PY2 wie die Datenverwaltung und -visualisierung mit Hilfe der Python-Bibliothek Pandas durchgeführt wird. Ein Zeitreihen-Datensatz zum Stromverbrauch in Deutschland aus der Open-Power-System-Data (OPSD)-Plattform dient als Anwendungsbeispiel. Die Daten werden in der interaktiven, webbasierten Anwendungsumgebung Jupyter Notebook analysiert. Es wird zunächst eine statische Datenvisualisierung mit Hilfe der Bibliothek Matplotlib durchgeführt und danach eine interaktive Visualisierung mit Jupyter Widgets.
Motivation
Bei der Datenanalyse ist das Einlesen und Aufbereiten der Daten der erste und aufwendigste Schritt, da die Daten selten in der benötigten Form schon vorliegen. In vielen Fällen enthält die externe Datenquelle (z.B. eine CSV-Datei) mehr Daten als benötigt werden, oder einzelne Datenwerte fehlen, oder haben das falsche Format.
Python stellt drei leistungsfähige Bibliotheken für die Verarbeitung und Visualisierung von Daten zur Verfügung: Numpy, Pandas, Matplotlib, deren Verwendung hier an einem konkreten Anwendungsfall veranschaulicht wird.
Warum Pandas?
Pandas ist eine Python-Bibliothek, die spezielle Datenstrukturen - Series und DataFrames - für den Zugriff auf Excel-ähnliche beschriftete Datentabellen anbietet, sowie viele Funktionen, mit deren Hilfe die Daten erstellt, bearbeitet und visualisiert werden können. In der Datenanalyse spielt Pandas eine zentrale Rolle, da damit große Excel- und csv-Dateien in den Arbeitsspeicher des Programms geladen werden, mit dem Ziel, die Daten anschließend zu analysieren und visualisieren. Pandas-Funktionen wie iloc(), loc(), resample() werden verwendet, um Zeilen / Spalten / Zellen auszuwählen und Daten zu gruppieren und aggregieren.
Warum Matplotlib?
Matplotlib ist eine Python-Bibliothek für Datenvisualisierung, die über das Paket pyplot das Erstellen von Diagrammen unterschiedlichster Art unterstützt: Linien-, Punkte-, Balkendiagramme, ein- und zweidimensonal, statisch oder interaktiv. Die wichtigsten Befehle zum Plotten sind plot für eindimensionale und surf für mehrdimensionale Diagramme. Der plot-Befehl erhält als Parameter die x- und y-Koordinaten der darzustellenden Daten, und optional einen String mit Formatierungsangaben. Weiterhin stehen viele Optionen zum Hinzufügen von Beschriftungen, Titeln, Legenden etc. zur Verfügung.
Seaborn ist eine Matplotlib-Erweiterung, die speziell auf Pandas Dataframes abgestimmt ist. Mit Hilfe der seaborn-Funktionen können graphische Darstellungen verschönert und professioneller gestaltet werden, z.B. kann man verschiedene Farbschemen auswählen.
Übersicht
Demo-PY2 ist in sieben Abschnitte gegliedert. Zunächst wird der OPSD-Datensatz beschrieben und die Fragestellung, die wir mit unserer Datenvisualisierung beantworten wollen. Danach wird die Erstellung des Jupyter Notebooks und Vorbereitung benötigter Bibliotheken erläutert. In den folgenden Abschnitten beschreiben wir die Datenverwaltung mit Pandas und Datenvisualisierung mit Matplotlib.
4 Aufbereitung des Stromverbrauchs-Datensatzes
4-1 Programmbibliotheken importieren, 4-2 Daten einlesen, 4-3 Datenspalten auswählen, 4-4 Datenframe exportieren, 4-5 Datenspalten skalieren, 4-6 Extrahiere Jahr, Monat und Tag 4-8 Auswertungen auf Tag / Woche / Monat - Basis5 Datenvisualisierung mit Matplotlib
5-1 Entwicklung des täglichen Stromverbrauchs,
5-2 Monatlicher Stromverbrauch vs. Solar- und Windproduktion
5-3 Täglicher Stromverbrauch 2016 vs. 2019
Das Tutorial ist als Google Colab Notebook online verfügbar:
1 Der OPSD-Datensatz
Open Power System Data ist eine offene Plattform für Energieforscher, die europaweit gesammelte Energiedaten in Form von csv-Dateien und sqlite-Datenbanken zur Verfügung stellt. Die Daten können kostenlos heruntergeladen und genutzt werden. Die Plattform wird von einem Konsortium (Europa-Universität Flensburg, TU Berlin, DIW Berlin und Neon Neue Energieökonomik) betrieben, mit dem Ziel, die Energieforschung zu unterstützen.
Für dieses Tutorial verwenden wir einen Datensatz zur elektrischen Energieerzeugung in Deutschland für den Datenzeitraum: 01.01.2016 - 30.09.2020 mit einer stündlichen Auflösung. Wir wollen Fragen beantworten wie: Wie ändern sich Stromverbrauchs- und Kapazitätsdaten für Strom insgesamt, Solar- und Windenergie über die Jahre? Wann im Laufe eines Jahres ist der Verbrauch am höchsten?
2 Jupyter Notebook erstellen
Für die Datenverwaltung und Datenvisualisierung wird ein Jupyter Notebook erstellt. Über Programme öffnen wir die Jupyter Notebook-Anwendung und erstellen mit Hilfe des Menüpunkts "New" ein neues Python3-Notizbuch mit dem Namen elab2go-Demo-PY2.
Die Details der Verwendung von Jupyter Notebooks sind im Abschnitt Jupyter Notebooks verwenden beschrieben.
3 Datenverwaltung mit Pandas
Pandas verfügt über zwei Datenstrukturen, Series und DataFrames, und eine Vielzahl von Funktionen, mit denen man diese Datenstrukturen aufbereiten und manipulieren kann. Die Pandas-Funktionen lassen sich einteilen in Funktionen für das Laden und Speichern von Daten, Funktionen für die Datenaufbereitung, Funktionen für die Aggregation von Daten, und Funktionen zum Visualisieren ("Plotten") der Daten.
3-1 Series
Eine Series ist ein eindimensionales indizierbares Objekt, das Daten in einer Zeile oder Spalte speichert. Die einfachste Series entsteht aus einer Liste von Daten:
import pandas as pdname = pd.Series(["Max Muster", "Anna Test", "John Doe"])adresse = pd.Series(["Schoenstrasse 11", "Unter de Linden 2", "Amperstrasse 1"])tel = pd.Series(["0151 (345678)", "0171 (123456)", "0161 (987654)"])print(name)
3-2 DataFrames
Ein DataFrame repräsentiert eine tabellarische Datenstruktur mit einer geordneten Kollektion von Spalten, die jeweils verschiedene Datentypen haben können. DataFrames können auf verschiedene Arten erzeugt werden, zum Beispiel aus mehreren Series oder aus einem Dictionary, dessen Werte gleich lange Listen sind, wie im folgenden Beispiel:
Beispiel: DataFrame aus Series oder Dictionary erzeugen
import pandas as pdadressbuch = {"Name": ["Max Muster", "Anna Test", "John Doe"],"Adresse": ["Schoenstrasse 11", "Unter de Linden 2", "Amperstrasse 1"],"Telefonnummer": ["0151 (345678)", "0171 (123456)", "0161 (987654)"]}df1 = pd.concat([name, adresse, tel], axis=1) # DataFrame aus Seriesdf2 = pd.DataFrame(adressbuch) # DataFrame aus Dictionarydf1 # Ausgabe des DataFrames df1
4 Aufbereitung des Stromverbrauchs-Datensatzes
Der OPSD-Datensatz, der in Form einer csv-Datei time_series_60min.csv vorliegt, wird nun mit Hilfe der Pandas-Datenstrukturen und Funktionen eingelesen, aufbereitet und tabellarisch ausgegeben.
4-1 Programmbibliotheken importieren
In der ersten Codezelle des Jupyter Notebooks importieren wir die benötigten Programmbibliotheken: Pandas, Matplotlib und Seaborn. In Python kann man mit Hilfe der import-Anweisung entweder eine komplette Programmbibliothek importieren, oder nur einzelne Funktionen der Programmbibliothek. Beim Import werden für die jeweiligen Bibliotheken oder Funktionen Alias-Namen vergeben: für pandas vergeben wir den Alias pd, etc.
import pandas as pd # Wird für Datenverwaltung und Datenbereinigung benötigtimport matplotlib as plt # Wird für die Visualisierung, Plots etc. benötigtimport matplotlib.dates as mpdimport seaborn as sns # Erweiterung von matplotlib, schönere Graphen
4-2 Daten einlesen
In der zweiten Codezelle werden die OPSD-Daten, die in der csv-Datei time_series_60min.csv gespeichert sind, mit Hilfe der Funktion read_csv() der Pandas-Bibliothek in den Arbeitsspeicher des Python-Programms eingelesen und zur Kontrolle wieder ausgegeben. Die Funktion read_csv() speichert die Daten in ein DataFrame mit dem Namen opsd_full.
- Zeile 2: Die Funktion read_csv() wird mit drei Parametern aufgerufen. Als ersten Parameter übergeben wir den Namen der einzulesenden CSV-Datei. Mit dem zweiten Parametern index_col=0 legen wir fest, dass die erste Spalte des DataFrames als Zeilenüberschrift interpretiert wird. Mit dem dritten Parameter parse_dates=True wird festgelegt, dass die Werte der Index-Spalte als Datumswerte interpretiert und geparst werden. Dies ist wichtig, damit wir nachher Jahr, Monat und Tag extrahieren können.
- Zeile 4: Fehlende Werte werden mit 0 ersetzt, dies geschieht mit Hilfe der Funktion fillna.
- Zeile 5-8: Die Funktion display_dataframe ist eine selbstdefinierte Funktion, mit deren Hilfe wir aus einem größeren DataFrame die angegebene Anzahl von Zeilen und Spalten ausgeben.
- Zeile 9-10: Ausgabe der ersten und letzten zwei Zeilen und aller Spalten des DataFrames.
# Lese CSV-Datei einopsd_full = pd.read_csv('time_series_60min_2016-2020.csv', index_col=0, parse_dates=True)# Ersetze fehlende Werte mit 0opsd_full = opsd_full.fillna(0)# Funktion zur formatierten Ausgabe eines DataFramesdef display_dataframe( df, rows=6, cols=None):with pd.option_context('display.max_rows', rows, 'display.max_columns', cols):display(df);# Zeige erste und letzte zwei Zeilen zur Kontrolle andisplay_dataframe(opsd_full, 4)
Die Ausgabe nach Ausführung dieses Codeblocks sieht ähnlich aus wie abgebildet. Die Index-Spalte des DataFrames ist hier die Spalte TimestampUTC und wird als Zeilenüberschrift hervorgehoben.
4-3 Datenspalten auswählen
Wir benötigen aus der heruntergeladenen csv-Datei nur die Spalten TimestampUTC, Verbrauch, Solar und Wind. In der dritten Codezelle wird die Pandas-Funktion iloc() verwendet, um aus dem Dataframe opsd_full die benötigten Spalten auszuwählen und in ein neues DataFrame mit dem Namen opsd_mwh zu kopieren.
- opsd_full.iloc[:,[1,3,5]] bedeutet, dass alle Zeilen, aber nur die Spalten 1, 4 und 6 extrahiert werden.
- .copy() bedeutet, dass durch Kopieren ein neuer DataFrame erstellt wird. Dies stellt sicher, dass der ursprüngliche DataFrame unverändert bleibt und nicht unbeabsichtigt verändert wird.
# Behalte aus dem Datensatz nur die benötigten Spaltenopsd_mwh = opsd_full.iloc[:,[1,3,5]].copy()# Zeige erste und letzte zwei Zeilen zur Kontrolle andisplay_dataframe(opsd_mwh, 4)
Die Ausgabe nach Ausführung dieses Codeblocks sieht folgendermaßen aus:
4-4 Datenframe exportieren
In der vierten Codezelle wird der vereinfachte Datensatz als Sicherung in eine neue csv-Datei exportiert. Für den Export wird die Pandas-Funktion to_csv() verwendet. Die Option "Index=True" bedeutet, dass auch die Index-Spalte bzw. Zeilenüberschrift (in unserem Fall: TimestampUTC) mit exportiert wird.
# Exportiere den vereinfachten Datensatz als Sicherung in eine neue csv-Dateiopsd_mwh.to_csv (r'time_series_60min_xs.csv', index = True, header=True)
4-5 Datenspalten skalieren
In der fünften Datenzelle teilen wir die Verbrauchs-Spalten durch 1000 und sichern das Ergebnis in einem neuen DataFrame opsd. Dies stellt sicher, dass die Anzeige der Verbrauchsdaten in GWh erfolgt anstelle von MWh. Pandas stellt eine Reihe arithmetischer Operationen (add, sub, mul, div) zur Verfügung, die man auf den Elementen eines DataFrames ausführen kann. Hier verwenden wir die Pandas-Funktion div(), um alle Elemente der ausgewählten Spalten durch 1000 zu teilen.
# Teile die Verbrauchsspalten durch 1000, damit die Anzeige in GWh erfolgtopsd = opsd_mwh.iloc[:,0:3].div(1000)# Zeige erste und letzte zwei Zeilen zur Kontrolle andisplay_dataframe(opsd, 4)
Die Ausgabe nach Ausführung dieses Codeblocks sieht folgendermaßen aus:
4-6 Extrahiere Jahr, Monat und Tag
Wir fügen dem Datensatz drei neue Spalten hinzu, indem wir aus der Index-Spalte des DataFrames opsd die entsprechenden Bestandteile extrahieren.
# Extrahiere Jahr, Monat und Tag aus dem Datumopsd['Jahr'] = opsd.index.yearopsd['Monat'] = opsd.index.monthopsd['Tag'] = opsd.index.weekday_name# Zeige erste und letzte zwei Zeilen zur Kontrolle andisplay_dataframe(opsd, 4)
Die Ausgabe nach Ausführung dieses Codeblocks sieht folgendermaßen aus:
4-7 Datumsbereiche auswählen
Wir wählen mit Hilfe der Pandas-Funktion-loc() zwei Datumsbereiche aus, die miteinander verglichen werden sollen. Die Funktion loc() dient ähnlich wie iloc() der Auswahl von Bereichen aus einem DataFrame. Während die iloc()-Funktion den Index einer Spalte als Filter verwendet, passiert die Auswahl bei loc() über Zeilen- und Spaltenüberschriften.
# Wähle den Monat Juli im Jahr 2018 ausopsd_juli_2018 = opsd.loc['2018-07-01 00':'2018-07-31 23']# Wähle den Monat Juli im Jahr 2019 ausopsd_juli_2019 = opsd.loc['2019-07-01 00':'2019-07-31 23']# Zeige erste und letzte zwei Zeilen des Monats Juli 2019 zur Kontrolle andisplay_dataframe(opsd_juli_2019, 4);
Die Ausgabe nach Ausführung dieses Codeblocks sieht folgendermaßen aus:
4-8 Auswertungen auf Tages-,Wochen- und monatlicher Basis
Wir haben bisher die stündlichen Verbrauchswerte betrachtet, so wie sie in der heruntergeladenen Datei zur Verfügung gestellt waren. Für die Betrachtung eines größeren Zeitraums (Monate und Jahre) benötigen wir die Verbrauchswerte pro Tag, Woche und Monat. In diesem Schritt wird nun eine Änderung der Zeitskala, ein sogenanntes Resampling, durchgeführt. Mit Resampling ist der Prozess gemeint, der eine Zeitreihe von einer Frequenz in eine andere überführt, und geschieht in Python mit Hilfe der Pandas-Methode resample().
Beispiel: Berechne Tagessummen, Wochen-Mittelwerte, Monatssummen
- Zeile 1: Wähle die Spalten aus, für die wir die Änderung der Zeitskala durchführen wollen.
- Zeile 4: Führe ein Resampling der ausgewählten Spalten aus. Die Funktion resample() wird mit dem Parameter 'D' aufgerufen, d.h. es wird nach Tagen gruppiert. Auf den gruppierten Elementen wird die sum()- Funktion ausgeführt, d.h. die Stundenwerte eines Tages werden zu einem Tages-Gesamtwert aufaddiert.
- Zeile 8: Hier wird ein Resampling der Tageswerte auf Wochenbasis durchgeführt (Parameter 'W'), und es wird als aggregierende Funktion der Mittelwert verwendet. D.h. wir berechnen den mittleren wöchentlichen Verbrauch.
# Wähle Spalten ausspalten = ['Verbrauch', 'Wind', 'Solar']# Gruppiere jede der Spalten nach Tagopsd_tag = opsd[spalten].resample('D').sum()# Gruppiere jede der Spalten nach Woche# Aggregiere die Werte über den Mittelwertopsd_woche = opsd_tag[spalten].resample('W').mean()# Gruppiere jede der Spalten nach Monat# Monate mit weniger als 28 Tagen werden nicht gezähltopsd_monat = opsd[spalten].resample('M').sum(min_count=28)# Zeige erste und letzte zwei Zeilen zur Kontrolle andisplay_dataframe(opsd_tag, 4)
Die Ausgabe nach Ausführung dieses Codeblocks sieht folgendermaßen aus:
5 Datenvisualisierung mit Matplotlib
Um Matplotlib verwendet zu können, muss die Bibliothek zunächst importiert werden:
import matplotlib.pyplot as plt
Die Syntax von Matplotlib ist einfach und vergleichbar mit der Syntax der MATLAB-plot-Funktionalität. Um ein Diagramm zu erstellen, wird zunächst ein Figure-Objekt erstellt, dem mehrere Subplots hinzugefügt werden können. Die wichtigsten Befehle zum Plotten sind plot für eindimensionale und surf für mehrdimensionale Diagramme. Der plot-Befehl erhält als Parameter die x- und y-Koordinaten der darzustellenden Daten, und optional einen String mit Formatierungsangaben, wie im folgenden Beispiel:
Beispiel: Zeichne die Sinus- und Cosinus-Funktion auf dasselbe Diagramm.
- Zeile 1: Importiere die NumPy-Bibliothek
- Zeile 2: Erzeuge eine Diskretisierung x des Intervalls [0, 10] mit 40 Datenpunkten
- Zeile 3: Berechne die Funktionswerte y1, y2 in den Punkten des Arrays x. y1 und y2 sind jeweils Arrays mit 40 Elementen.
- Zeile 4: Erzeuge eine Figur mit vorgegebener Größe: 4x2 cm.
- Zeile 5: Zeichne die beiden diskretisierten Funktionen in dasselbe Diagramm. Die erste Funktion wird rot eingezeichnet, mit einem Stern als Marker, die zweite Funktion blau mit einem +-Zeichen als Marker.
import numpy as npx = np.linspace(0,10,40)y1 = np.sin(x);y2 = np.cos(x);fig=plt.figure(figsize=[4,2])plt.plot(x, y1,'r*',x, y2,'b+')
Die Ausgabe nach Ausführung dieses Codeblocks sieht ähnlich aus wie abgebildet. Das Diagramm kann weiter verschönert werden, indem man Beschriftungen für die Achsen, einen Titel, eine Legende etc. festlegt.
Bei der Verwendung von Matplotlib mit Pandas ist es nicht erforderlich, die x- und y-Koordinaten des darzustellenden Diagramms explizit anzugeben wie in unserem Minibeispiel. Der plot-Befehl ist als Methode der Pandas-Datenstrukturen integriert, so dass ein DataFrame df direkt mit df.plot() visualisiert werden kann.
5-1 Entwicklung des täglichen Stromverbrauchs
Wir visualisieren zunächst die Spalte "Verbrauch" des DataFrames "opsd_tag", d.h. den täglichen Stromverbrauch in Deutschland vom 01.01.2016 bis 31.12.2019.
- Zeile 1: Größe des Diagramms wird auf 12x4 cm festgelegt.
- Zeile 2: Die Spalte "Verbrauch" wird mit Hilfe des plot-Befehls grafisch dargestellt. Die Werte für die x-Koordinaten werden implizit der Index-Spalte des DataFrames (hier: TimestampUTC) entnommen.
- Zeilen 3-6: Lege Titel, Beschriftungen der Achsen und den Wertebereich der y-Achse fest.
sns.set(rc={'figure.figsize':(12, 4)})ax = opsd_tag['Verbrauch'].plot(linewidth=1, color='b')ax.set_title('Täglicher Stromverbrauch DE 2016 - 2019')ax.set_xlabel('Datum');ax.set_ylabel('Tägl. Verbrauch (GWh)');ax.set_ylim(800,1800)
Die Ausgabe nach Ausführung dieses Codeblocks sieht folgendermaßen aus:

5-2 Monatlicher Stromverbrauch vs Solar- und Windproduktion
Im nächsten Schritt wollen wir sehen, wie sich der monatliche Stromverbrauch im Vergleich zur Solar- und Windproduktion von 2016 bis 2020 entwickelt hat. Als Datenquelle verwenden wir nun die aggregierten monatlichen Daten, d.h. den zuvor erstellten DataFrame opsd_monat.
- Zeile 2-3: Plotte die Spalten "Verbrauch", "Solar" und "Wind" des DataFrames mit unterschiedlichen Farben und Markern.
- Zeile 5-8: Erzeuge Legende, Titel und lege Achsenbeschriftungen fest.
# Visualisiere den monatlichen Verbrauchax = opsd_monat["Verbrauch"].plot(linewidth=2, color='b')ax = opsd_monat["Solar"].plot(linewidth=1.5, color='r', marker='*',)ax = opsd_monat["Wind"].plot(linewidth=1.5, color='g', marker='o')ax.legend();ax.set_title('Monatlicher Stromverbrauch DE 2016 - 2019')ax.set_xlabel('Datum');ax.set_ylabel('GWh');
Die Ausgabe nach Ausführung dieses Codeblocks zeigt, dass während die Solarproduktion mit den jahreszeitenabhängigen
Schwankungen auf gleichem Niveau bleibt, die Produktion von Windenergie gerade in den Wintermonaten einen klaren Trend nach oben zeigt.

5-3 Täglicher Stromverbrauch 2016 vs 2019
Wie hat sich der tägliche Stromverbrauch seit 2016 verändert? Um dies zu analysieren, vergleichen wir die Jahre 2016 und 2019. Wir verwenden wieder die plot-Funktion der Matplotlib, um den Stromverbrauch der Jahre 2016 und 2019 gegenüberzustellen. Die beiden graphischen Darstellungen werden auf derselben Figur / Achsensystem eingezeichnet. Die Diagramme werden mit Titeln und Achsen-Beschriftungen versehen, und es werden mit Hilfe der Funktion set_major_formatter die Monate des Jahres als Beschriftung der x-Achse festgelegt.
import matplotlib.dates as mdates# Extrahiere darzustellende Datenopsd_2016 = opsd_tag.loc['2016-01-01':'2016-12-31']opsd_2019 = opsd_tag.loc['2019-01-01':'2019-12-31']# Setze die Größe der Anzeigesns.set(rc={'figure.figsize':(16, 7)})# Zwei plot auf Achse axfig, ax = plt.subplots()ax.plot(opsd_2016['Verbrauch'].values, label='2016', color='b', marker='*')ax.plot(opsd_2019['Verbrauch'].values, label='2019', color='g', marker='o')ax.set_ylabel('GWh')ax.set_title('Stromverbrauch (täglich) DE 2016 vs. 2019')ax.legend(); # wird aus den labels erzeugt# Beschriftung der x-achse = Monatemonth_day_fmt = mdates.DateFormatter('%b')ax.xaxis.set_major_formatter(month_day_fmt)
Die Ausgabe nach Ausführung dieses Codeblocks zeigt, dass der Stromverbrauch 2019 (grün) in den Wintermonaten Januar bis März höher ist
als der Stromverbrauch 2016 (blau), in einigen Sommermonaten jedoch etwas niedriger.
Für eine genauere Analyse ist eine Änderung der Zeitskala oder des ausgewählten Zeitraums notwendig.

6 Interaktive Datenvisualisierung
Für eine benutzerfreundliche Analyse der Daten erstellen wir eine interaktive Datenvisualisierung mit Hilfe der interactive_output-Funktion des Paketes Jupyter Notebook Widgets. Die Benutzeroberfläche benötigt Steuerfelder bzw. Widgets, um Datumsbereich und Spalten auszuwählen, sowie eine Funktion, die abhängig von den ausgewählten Daten den entsprechenden Bereich des DataFrames opsd_tag darstellt. Das Ergebnis sieht wie abgebildet aus, die verwendeten Widgets sind rot eingezeichnet:
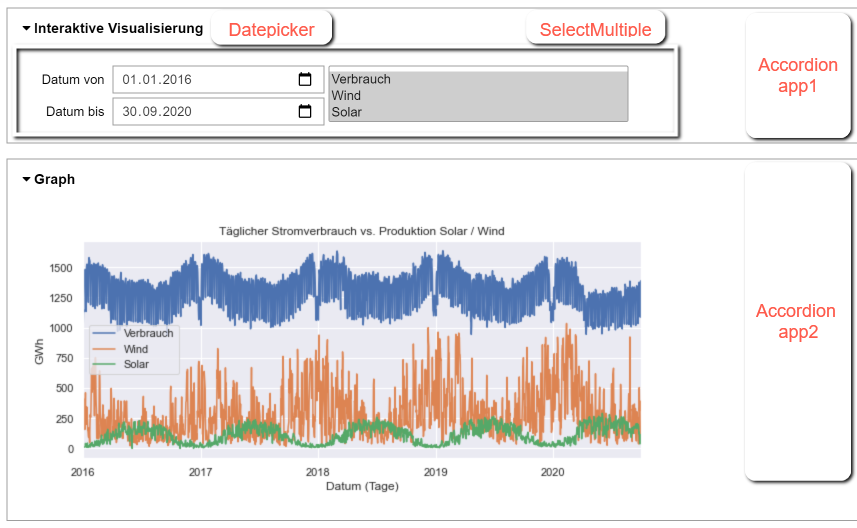
Zunächst wird die Funktion select_data implementiert und getestet, die ausgewählte Zeilen und Spalten des opsd_tag-Datensatzes visualisiert. Die Funktion hat drei Parameter: datumVon - für die Auswahl des Startdatums, datumBis - für die Auwahl des Enddatums und spalten - für die Auswahl der Spalten. Ein Beispiel-Funktionsaufruf in der Form select_data('2016-01-01', '2016-02-01', ['Verbrauch']) zeigt, dass die Implementierung korrekt funktioniert.
# Funktion definierendef select_data(datumVon, datumBis, spalten):df = opsd_tag.loc[datumVon:datumBis,spalten];sns.set(rc={'figure.figsize':(14, 7)})ax = df.plot();ax.set_title("Stromverbrauch vs. Produktion Solar / Wind");ax.set_xlabel('Datum (Tage)')ax.set_ylabel('GWh');# Funktion testenselect_data('2016-01-01', '2016-02-01', ['Verbrauch'])
Im nächsten Schritt werden zwei Datepicker-Widgets für die Auswahl des Start- und Enddatums und ein Auswahlwidget für die Auswahl der Spalten erstellt, zur Verbesserung des Layouts in Box-Widgets verpackt und mit display angezeigt. Nun ist alles vorhanden, um die interaktive Datenvisualisierung mit Hilfe der Funktion interactive_output fertigzustellen: die Funktion select_data, die wir als ersten Parameter übergeben, und die Liste der Widgets, die mit den Parametern der Funktion select_data interagieren.
- Zeile 5-9: Hier werden zwei Datepicker-Widgets erstellt, mit angegebener Beschriftung und Default-Wert. Als Voreinstellung haben wir den gesamten Zeitbereich gewählt.
- Zeile 10-11: Das SelectMultiple-Widget erstellt ein Mehrfach-Auswahlfeld und hat hier als mögliche Optionen die Spalten 0 bis 3 des DataFrames opsd_tag. Wir zeigen von den möglichen 4 Optionen nur die ersten drei an, dies wird mit dem Parameter rows eingestellt.
- Zeile 12: Das Widget ui_parameter wird als Container für horizontal angeordnete Widgets angelegt, der seinerseits eine VBox als Container für die Datum-Auswahlfelder und das Mehrfachauswahlfeld für Spalten enthält.
- Zeile 14-17: Erzeugen der interaktiven Ausgabe mit Hilfe eines Funktionsaufrufs der Funktion interactive_output.
- Zeie 18-23: Für eine Aufteilung der Benutzeroberfläche in zwei ausklappbare Bereiche werden als Container zwei Accordion-Widgets app1 und app2 erstellt, und diese zuletzt mit display angezeigt.
import ipywidgets as wdfrom ipywidgets import interactive_output, VBox, HBox, DatePickerimport datetime as dt# Widgets für die Auswahl des Datums und der Spaltendatum_von = wd.DatePicker(description='Datum von',value = dt.date(2016,1,1))datum_bis = wd.DatePicker(description='Datum bis',value = dt.date(2020,9,30))ui_spalten = wd.SelectMultiple(options=opsd_tag.columns[0:3],value=list(opsd_tag.columns[0:3]), rows=3)ui_parameter = wd.HBox([wd.VBox([datum_von, datum_bis]), ui_spalten])# Interaktive Ausgabe mit interactive_outputout = wd.interactive_output(select_data,{'datumVon': datum_von, 'datumBis': datum_bis,'spalten': ui_spalten})app1 = wd.Accordion([ui_parameter])app1.set_title(0, 'Interaktive Visualisierung')app2 = wd.Accordion([out])app2.set_title(0, 'Graph')display(app1)display(app2)
7 Videos
Die Durchführung der Datenvorwaltung und -Visualisierung mit den Python-Bibliotheken Pandas, Matplotlib und die Verwendung des erstellten Jupyter Notebook wird durch ein 5-Minuten-Youtube-Video (Screencast mit zusätzlichen Erläuterungen) veranschaulicht. Das zweite eingebettete Video zeigt die Verwendung des erweiterten interaktiven Jupyter Notebooks.
Datenverwaltung mit Pandas
Interaktive Visualisierung von Stromverbrauchsdaten
Autoren, Tools und Quellen
Mit Beiträgen von:
Prof. Dr. Eva Maria Kiss
Franc Willy Pouhela, M. Sc. Anke Welz
Tools:
Python,
Anaconda,
Jupyter Notebook
Pandas,
Seaborn
Quellen und weiterführende Links:
- DataQuest Tutorial: Time Series Analysis with Pandas: ps://www.dataquest.io/blog/tutorial-time-series-analysis-with-pandas/
- McKinney, Wes (2019): Datenanalyse mit Python. Auswertung von Daten mit Pandas, NumPy und IPython. 2. Auflage. Heidelberg: O'Reilly.
- Matplotlib: https://matplotlib.org/stable/index.html
- Offizielle Python Dokumentation bei python.org: https://docs.python.org/3/tutorial/
sehr umfangreich, Nachschlagewerk, hier findet man Dokumentationen für spezifische Python-Versionen - Open Power System Data. 2020. Data Package Time series. Version 2020-10-06. https://doi.org/10.25832/time_series/2020-10-06
- Python-Tutorial: https://www.elab2go.de/demo-py1/
- Jupyter Notebooks verwenden: https://www.elab2go.de/demo-py1/jupyter-notebooks.php
- Jupyter Notebook Widgets erstellen: https://www.elab2go.de/demo-py1/jupyter-notebook-widgets.php