Demo-PY3: Clusteranalyse mit scikit-learn
Nachdem in Demo-PY1: Python-Tutorial der erste Einstieg in die Syntax und in Demo-PY2: Datenverwaltung mit Pandas die Datenverwaltung und - visualisierung mit Hilfe der Python-Bibliothek Pandas erfolgt ist, zeigt Demo-PY3 im nächsten Schritt, wie eine Clusteranalyse mit Hilfe der Python-Bibliotheken scikit-learn und SciPy durchgeführt wird.
Ein Datensatz zum Raumklima in Abhängigkeit von Luftfeuchtigkeit und Temperatur dient uns dabei als Anwendungsbeispiel.
Die Daten werden in der interaktiven, webbasierten Anwendungsumgebung Jupyter Notebook analysiert.
Im letzten Schritt der Demo erfolgt die Datenvisualisierung und die Zuordnung zu den Clustern mit Hilfe der Bibliothek Matplotlib.
Motivation
Bei der Datenanalyse (gerade bei großen Datenmengen) stellt sich häufig die Frage nach gemeinsamen Gruppen ("Cluster") innerhalb der
Daten. In einem Datensatz mit Raumklima-Daten sind z.B. die Beobachtungen M1 = {Temp = 23°C, Feuchtigkeit = 69%} und
M2 = {Temp = 21°C, Feuchtigkeit = 80%} einander ähnlich und könnten einer Gruppe "zu feucht" zugeordnet werden.
Gruppen ähnlicher Merkmale werden durch die Verwendung eines bestimmten Ähnlichkeits- bzw. Abstandsmaßes
gebildet. Neue Daten können anhand ihrer Merkmale dann den Clustern zugeordnet werden.
Python stellt zwei leistungsfähige Bibliotheken für die Anwendung von Verfahren zum maschinellen Lernen zur Verfügung:
scikit-learn und
SciPy, deren typische Verwendung wir
an einem konkreten Anwendungsfall veranschaulichen.
Warum scikit-learn?
scikit-learn ist eine Open-Source-Bibliothek zum maschinellen Lernen für die Programmiersprache Python und bietet leistungsstarke Algorithmen, wie Klassifikations-, Regressions- und Clustering-Algorithmen, siehe die sklearn-Funktionen. In diesem Abschnitt wird die Bibliothek scikit-learn eine zentrale Rolle spielen, da sie die von uns benötigten Clusterverfahren "KMeans" und "hierarchische Modelle" zur Verfügung stellt, siehe sklearn.cluster.
Warum SciPy?
SciPy ist eine Python-Programmbibliothek für wissenschaftliches Rechnen und Visualisierung von Modellen. SciPy umfasst numerische Algorithmen und mathematische Werkzeuge, wie das in dieser Demo verwendete Cluster-Paket scipy.cluster.hierarchy, das die Funktionen dendrogram zur Erstellung eines Dendrogramms und linkage zur Durchführung einer Clusteranalyse enthält.
Übersicht
Demo-PY3 ist in 6 Abschnitte gegliedert. Zunächst wird der Raumklima-Datensatz beschrieben und die Fragestellung, die wir mit unserer Datenanalyse beantworten wollen. Danach beschreiben wir kurz die Funktionsweise und Anwendung von Clusteranalysen. Danach wird die Erstellung des Jupyter Notebooks und Vorbereitung benötigter Bibliotheken erläutert. In den folgenden Abschnitten beschreiben wir die Datenanalyse mit scikit-learn und SciPy inkl. der Daten- und Clustervisualisierung mit Matplotlib.
1 Der Raumklima-Datensatz
Der Raumklima-Datensatz enthält 15 Beobachtungen / Messungen zur Temperatur (in Grad Celsius) und der Luftfeuchtigkeit (in %). Je nach Kombination aus Temperatur und Luftfeuchtigkeit wird das Raumklima als "behaglich", "zu trocken" oder "zu feucht" empfunden.
Wir wollen mit Hilfe einer Clusteranalyse Fragen beantworten wie:
Welche Kombination aus Temperatur und Luftfeuchtigkeit führt zu einem optimalen Klima?
Können Daten mit gewissen Kombinationen aus Temperatur und Luftfeuchtigkeit
einer Gruppe bzw. einem Cluster "behaglich",
"zu trocken" oder "zu feucht" zugeordnet werden?
2 Was ist eine Clusteranalyse?
Eine Clusteranalyse ist ein Verfahren des maschinellen Lernens,
mit dessen Hilfe man in einem Datensatz Gruppen ähnlicher Beobachtungen ("Cluster") identifizieren kann.
Die Clusterbildung kann mit unterschiedlichen Algorithmen umgesetzt werden.
Zwei der bekanntesten Verfahren sind K-Means-Clustering und hierarchisches Clustering.
Die Idee bei K-Means-Clustering ist, dem Algorithmus als Input eine feste Anzahl k von Clustern vorzugeben, der zu diesen Clustern die Clusterzentren bestimmt, und diese so lange verschiebt, bis sich die Zuordnung der Beobachtungen zu den Clusterzentren nicht mehr verändert. Dabei wird eine vorgegebene Fehlerfunktion minimiert.
Die Idee beim hierarchischen Clustering ist, dass der Algorithmus eine hierarchische Struktur der Daten aufbaut, ein sogenanntes Dendogramm. Beim agglomerativen ("bottom up") Clustering bildet zunächst jede Beobachtung ein Cluster, d.h. man hat zunächst ebensoviele Cluster wie Datenpunkte. Diese werden dann sukzessiv zusammengeführt in größere Cluster, wobei die Zusammenfassung auf Basis einer Fusionsvorschrift (engl. Linkage) geschieht. Bei Single Linkage werden die Cluster, deren nächste Objekte die kleinste Distanz zueinander haben, fusioniert. Bei der Ward-Methode werden die Cluster, die den kleinsten Zuwachs der totalen Varianz haben, fusioniert.
3 Jupyter Notebook erstellen
Für die Datenverwaltung, die Clusteranalyse und die Datenvisualisierung wird ein Jupyter Notebook erstellt. Über Programme öffnen wir die Jupyter Notebooks-Anwendung und erstellen mit Hilfe des Menüpunkts "New" ein neues Python3-Notizbuch mit dem Namen elab2go-Demo-PY3.
Die Details der Verwendung von Jupyter Notebooks sind im Abschnitt Jupyter Notebooks verwenden beschrieben.
4 Clusteranalyse mit K-Means-Verfahren
Die Clusteranalyse mit K-Means-Verfahren ist einfach anzuwenden, benötigt jedoch als Input die Anzahl der Cluster, diese ist bei den meisten Datensätzen nicht vorab bekannt.
4-1 Importieren der Programmbibliotheken
In der ersten Codezelle des Jupyter Notebooks importieren wir die benötigten Programmbibliotheken: scikit-learn und sciPy, sowie die aus
Demo-PY2: Datenverwaltung mit Pandas
bekannten Bibliotheken Pandas, Matplotlib, Seaborn und NumPy.
In Python kann man mit Hilfe der import-Anweisung entweder eine komplette Programmbibliothek importieren,
oder nur einzelne Funktionen der Programmbibliothek (from-import-Anweisung).
Beim Import werden für die jeweiligen Bibliotheken oder Funktionen Alias-Namen vergeben: für pandas vergeben wir den Alias pd, etc.
Die erste Codezelle enthält insgesamt sieben Import-Anweisungen und den Befehl %matplotlib inline, der bewirkt, dass die Plots innerhalb des Notizbuches erzeugt werden.
- Zeile 1: Matplotlib: Wird für die Visualisierung, Plots etc. benötigt.
- Zeile 2: Seaborn: Erweiterung von matplotlib, schönere Graphen.
- Zeile 3: NumPy: Wird für den Umgang mit Vektoren, Matrizen oder generell Arrays benötigt.
- Zeile 4: Pandas: Wird für Datenverwaltung und Datenbereinigung benötigt
- Zeile 5: scipy.cluster.hierarchy: Wird für die Anwendung der hierarchischen Verfahren benötigt.
- Zeile 6: KMeans: wird für die Anwendung der KMeans-Methode benötigt.
- Zeile 7: AgglomerativeClustering: wird für die Anwendung der hierarchischen Methoden benötigt.
import matplotlib.pyplot as pltimport seaborn as sns; sns.set()import numpy as npimport pandas as pdimport scipy.cluster.hierarchy as shcfrom sklearn.cluster import KMeansfrom sklearn.cluster import AgglomerativeClustering%matplotlib inline # Erzeuge Plots innerhalb des Notizbuches
4-2 Daten einlesen
In der zweiten Codezelle werden Daten, die in der csv-Datei raumklima.csv gespeichert sind, mit Hilfe der Funktion read_csv() der Pandas-Bibliothek eingelesen, siehe auch Demo-PY2: Datenverwaltung mit Pandas.
- Zeile 2: Die Funktion read_csv() wird mit zum Einlesen des Datensatzes aufgerufen.
- Zeile 5: Die Merkmale der Beobachtungen werden in ein DataFrame mit Namen X kopiert.
- Zeile 8: Die wahren Zuordnungen der Beobachtungen zu den Kategorien werden in ein DataFrame mit Namen cluster_true kopiert.
- Zeile 11: Die ersten 10 Beobachtungen des Datensatzes werden ausgegeben.
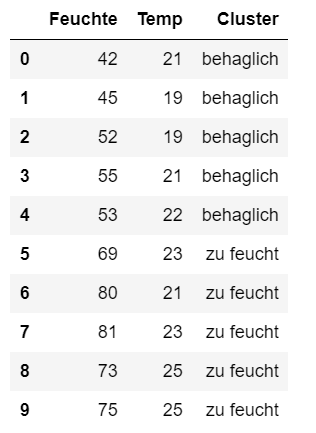
# Lese CSV-Datei einklima_data = pd.read_csv('raumklima.csv',sep=';', header=0)# Merkmale/Variablen Feuchtigk. und Temp. separat speichernX = klima_data.iloc[:,[0,1]].copy()# Wahre Zuordnung zu den Kategorien speicherncluster_true=klima_data.iloc[:,2].copy()# Zeige ausgewählte Zeilen zur Kontrolle anklima_data.head(10)
Die Ausgabe nach Ausführung dieses Codeblocks sieht ähnlich aus wie abgebildet.
4-3 Daten visualisieren
Nach einer Datenkonvertierung des DataFrames in ein Array mittels der NumPy-Bibliothek werden die Daten mit der scatter-Anweisung der Matplotlib-Bibliothek als Streudiagramm dargestellt. Ein Streudiagramm (auch: Punktwolke, engl. scatter plot) ist die graphische Darstellung der (x,y) Wertepaare zweier statistischer Merkmale (hier: Feuchtigkeit und Temperatur). Durch das Muster der Punkte im Streudiagramm erkennt man Informationen über die Abhängigkeitsstruktur der beiden Merkmale.
X = np.array(X) # Typkonvertierung: DataFrame->Arrayprint(type(X))# Daten visualisierenplt.scatter(X[:,0], X[:,1],s=40);plt.title('Raumklima-Daten als Scatter-Plot')plt.xlabel('Feuchtigkeit (%)');plt.ylabel('Temperatur ()');
Die Ausgabe nach Ausführung dieses Codeblocks sieht ähnlich aus wie abgebildet. Das Streudiagramm zeigt die Anordnung der Merkmale in drei klar abgegrenzte Punktwolken.

4-4 Clusteranalyse durchführen
Die Clusteranalyse wird mittels der KMeans-Funktion aus dem sklearn.cluster-Paket der scikit-learn-Bibliothek durchgeführt.
- Zeile 2: Die Anzahl der Zentren/Cluster wird als Option der KMeans-Funktion übergeben, hier 3 Cluster.
- Zeile 5: Die Clusteranalyse wird auf die Daten mit Namen X angewandt.
- Zeile 6: Für die Daten aus dem DataFrame X werden Vorhersagen zu den Clustern erstellt.
- Zeile 9: Die Zuordnungen zu den Clustern werden für die Beobachtungen ausgegeben, es wird der Index des Clusters angezeigt, hier: 0, 1 oder 2.
#Anzahl der Zentren festlegenkmeans = KMeans(n_clusters=3)# Vorhersage mittels K-Means-Verfahrenkmeans.fit(X)y_kmeans = kmeans.predict(X)# vorhergesagte Zuordnungen der Merkmalskombinationen zu den geschätzten Zentreny_kmeans
Die Ausgabe nach Ausführung dieses Codeblocks sieht ähnlich aus wie abgebildet.
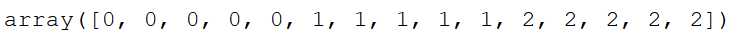
4-5 Zuordnung der Daten zu den Clustern visualisieren
Die Ergebnis, d.h. die Zuordnung der Beobachtungen zu den drei möglichen Zentren/Clustern, wird als Plot dargestellt.
- Zeile 2: Es wird ein Plot erstellt, der die Beobachtungen je nach Zuordnung zu den Clustern (c=y_kmeans) unterschiedlich einfärbt, nach dem Farbschema magma (cmap='magma').
- Zeile 5: Die Merkmalskombinationen der Cluster/Zentren werden mittels der cluster_centers_-Anweisung ausgelesen und unter centers abgespeichert.
- Zeile 6: Die Zentren werden im Plot ergänzt.
- Zeile 8-9: Der Titel und die Achsen des Plots werden angepasst.
- Zeile 11-13: Die Merkmalskombinationen der Cluster/Zentren werden ausgegeben.
# Daten visualisieren: Merkmaleplt.scatter(X[:, 0], X[:, 1], c=y_kmeans, s=40, cmap='magma')# Daten visualisieren: Zentrencenters = kmeans.cluster_centers_plt.scatter(centers[:, 0], centers[:, 1], c='black', s=60, alpha=0.7);plt.title("Raumklima")plt.xlabel('Feuchtigkeit (%)');plt.ylabel('Temperatur ()');# Merkmalswerte der Zentren ausgebenprint('Merkmalswerte der Zentren:')print(centers)
Die Ausgabe nach Ausführung dieses Codeblocks sieht ähnlich aus wie abgebildet.
| Output 1 | Output 2 |
|---|---|

|

|
5 Clusteranalyse mit Hilfe hierarchischer Modelle
Bei Ungewissheit zur Anzahl der Cluster/Zentren wird als vorbereitendes Mittel zur Auswahl der Clusteranzahl über eine hierarchische Clusteranalyse [1,3] ein Dendogramm erstellt. Aus diesem kann die Anzahl der Cluster abgelesen werden. In einem zweiten Schritt kann eine detaillierte agglomerative Clusteranalyse [4] verwendet werden, die als Input die Vorgabe einer festen Anzahl von Clustern erfordert.
Das Importieren der benötigten Bibliotheken bzw. derer Funktionen und das Einlesen und Visualisieren der Daten erfolgt wie bereits im vorherigen Abschnitt beschrieben. Wir starten in diesem Abschnitt direkt bei der Durchführung der Clusteranalyse und der Erstellung eines Dendrogramms mit Hilfe der entsprechenden Funktionen der scikit-learn- und SciPy-Bibliotheken.
5-1 Vorbereitung: Dendrogramm erstellen
Das Dendrogramm wird mittels dendrogram-Funktion des cluster.hierarchy-Pakets der sciPy-Bibliothek erstellt.
- Zeile 1, 2: Bereitet ein Grafikfenster mit einer festen Größe und einem Titel vor.
- Zeile 3: Die linkage-Funktion des cluster.hierarchy-Pakets der SciPy-Bibliothek erstellt führt ein hierarchisches Clustering mit Hilfe der Ward-Methode durch. Die Ward-Methode ist ein allgemeines hierarchisches Clustering-Verfahren, bei dem das Kriterium für die Auswahl des Clusterpaars, das bei jedem Schritt zusammengeführt werden soll, auf dem optimalen Wert einer Zielfunktion (z.B. Kleinste Quadrate) basiert. Der Rückgabewert der linkage-Funktion wird der dendrogram-Funktion übergeben, um ein Dendrogramm zu erstellen.
plt.figure(figsize=(10, 7))plt.title("Dendrogramm")dend = shc.dendrogram(shc.linkage(X, method='ward'))
Die Ausgabe nach Ausführung dieses Codeblocks sieht ähnlich aus wie abgebildet.

Die Wurzel des Dendogramms entspricht dem kompletten Raumklima-Datensatz mit 15 Beobachtungen.
Die Blätter des Dendogramms sind mit den IDs der Beobachtungen beschriftet, d.h. das äußerste linke Blatt
mit der Beschriftung 6 entspricht der Beobachtung M6 = {ID = 6, Feuchte = 80%, Temp = 21°C}.
Das Dendrogramm bestätigt das Vorhandensein von 3 Clustern.
Der erste Cluster enthält die Beobachtungen mit den IDs {6,7,5,8,9}, die dem Cluster "zu feucht" entsprechen.
Der zweite Cluster enthält die Beobachtungen mit den IDs {10,14,13,11,12}, die dem Cluster "zu trocken" entsprechen.
Der dritte Cluster enthält die Beobachtungen mit den IDs {0, 1, 2, 3, 4}, die dem Cluster "behaglich" entsprechen.
Die Information über die Anzahl der Cluster verwenden wir bei der Durchführung der Clusteranalyse, die im nächsten Schritt erfolgt.
5-2 Detaillierte Clusteranalyse durchführen
Die detaillierte Clusteranalyse wird mittels der AgglomerativeClustering aus dem sklearn.cluster-Paket der scikit-learn-Bibliothek durchgeführt.
- Zeile 2: Die Anzahl der Zentren/Cluster wird als Option der AgglomerativeClustering-Funktion übergeben, hier 3 Cluster, auch wird die euklidische Distanz als Abstandsmaß und die Ward-Funktion als Linkage-Methode übergeben.
- Zeile 5: Die Clusteranalyse wird auf die Daten mit Namen X angewandt.
- Zeile 6: Für die Daten aus dem DataFrame X werden Vorhersagen zu den Clustern erstellt.
- Zeile 9: Die Zuordnungen zu den Clustern werden für die Beobachtungen ausgegeben, es wird der Index des Clusters angezeigt, hier: 0, 1 oder 2.
# hierarchisches Modell festlegen, inkl. Anzahl der Clustercluster = AgglomerativeClustering(n_clusters=3, affinity='euclidean', linkage='ward')# Vorhersage mittels des hierarchischen Modellscluster = cluster.fit(X)y_cluster = cluster.fit_predict(X)# vorhergesagte Zuordnungen der Merkmalskombinationen zu den geschätzten Zentreny_cluster #or:# print(cluster.labels_)
Die Ausgabe nach Ausführung dieses Codeblocks sieht ähnlich aus wie abgebildet.

5-3 Zuordnung der Daten zu den Clustern visualisieren
Das Ergebnis der Clusteranalyse, d.h. die Zuordnung der Beobachtungen zu den drei möglichen Zentren/Clustern, wird als Plot dargestellt.
- Zeile 2: Es wird ein Plot erstellt, der die Beobachtungen je nach Zuordnung zu den Clustern (c=cluster.labels_) unterschiedlich einfärbt, nach dem Farbschema rainbow (cmap='rainbow').
- Zeile 4-6: Der Titel und die Achsen des Plots werden angepasst.
# Daten visualisieren: Merkmaleplt.scatter(X[:, 0], X[:, 1], c=cluster.labels_, s=40, cmap='rainbow')plt.title("Raumklima")plt.xlabel("Luftfeuchtigkeit(%)")plt.ylabel("Temperatur(Celsius)")
Die Ausgabe nach Ausführung dieses Codeblocks sieht ähnlich aus wie abgebildet.

6 YouTube-Video
Die Verwendung des erstellten Jupyter Notebook wird durch ein Video (Screencast mit zusätzlichen Erläuterungen) veranschaulicht.
Autoren, Tools und Quellen
Autoren:
M. Sc. Anke Welz
Prof. Dr. Eva Maria Kiss
Tools:
Python,
Anaconda,
Jupyter Notebook,
Pandas,
Matplotlib,
NumPy
elab2go Links:
- [1] Was ist Machine Learning? (elab2go)
- [2] Predictive Maintenance: Die Datenanalyse (elab2go)
- [3] Predictive Maintenance: Die Performance und die Kreuzvalidierung (elab2go)
- [4] Demo-PY4: Predictive Maintenance mit scikit-learn (elab2go)
Quellen und weiterführende Links: