Predictive Maintenance mit Python:
Ausfallerkennung mit DecisionTreeClassifier
Dies Tutorial zeigt, wie in einem Predictive Maintenance-Szenario Ausfälle mit Hilfe des DecisionTree-Klassifikators der Python-Bibliothek Scikit-Learn vorhergesagt werden können. Wir verwenden einen Automotive-Datensatz automotive_data.csv mit 22 Merkmalen, die Sensor-Messwerte am Motor enthalten, und einer Zielvariablen: Ausfall. Die Fragestellung lautet: "Bei welcher Kombination von Merkmalen tritt ein Ausfall ein?".
Motivation
Bei der Durchführung der Datenanalyse im Rahmen der
Predictive Maintenance
sind Entscheidungsbäume ein wichtiges Modell für die Vorhersage von Ausfällen.
Während im produktiven Einsatz optimierte Klassifikatoren wie Random Forest eingesetzt werden,
ist das Entscheidungsbaum-Modell wegen seiner einfachen Interpretierbarkeit
eine gute Wahl, um eine erste Datenanalyse durchzuführen und die Daten zu verstehen.
Voraussetzung für den Einsatz eines Entscheidungsbaum-Modells ist das Vorliegen von
Vergangenheitsdaten, bei denen bekannt ist, bei welcher Merkmalskombination ein Ausfall eingetreten ist.
Hier verwenden wir die Funktionen der Python-Bibliothek Scikit-Learn,
sowie Graphviz für die Visualisierung des Entscheidungsbaums,
und setzen als Entwicklungsumgebung Visual Studio Code ein.
Warum Scikit-Learn?
Scikit-Learn ist eine der wichtigen Python-Bibliotheken für Machine Learning und bietet Unterstützung für die üblichen Schritte des Überwachten und Unüberwachten Lernens: Datenvorbereitung, Trainingsphase und Modellevaluation, ebenso leistungsstarke Algorithmen für Klassifikations-, Regressions- und Clustering-Probleme.
Warum graphviz?
Graphviz ist ein Open-Source-Programmpaket zur Visualisierung von Graphen, das in scikit-learn mittels der Funktion export_graphviz() für die Visualisierung von Entscheidungsbäumen verwendet wird. Die mit graphviz erzeugten Entscheidungsbäume können in verschiedenen Bildformaten gespeichert werden, insbesondere auch im SVG-Format, und haben damit eine bessere Qualität als die Default-Visualisierung mit der sklearn-Funktion plot_tree().
Übersicht
Demo-PY4 ist in 8 Abschnitte gegliedert. Zunächst wird der Datensatz beschrieben und die Fragestellung formuliert, die mit der Datenanalyse beantwortet werden soll. Danach wird die Funktionsweise von Entscheidungsbäumen kurz vorgestellt, sowie die Vorbereitung der Entwicklungsumgebung und Installation benötigter Bibliotheken. In den folgenden Abschnitten erfolgt die Erstellung eines Entscheidungsbaum-Vorhersagemodells, danach die Visualisierung, zuletzt die Ermittlung von Performance-Kennzahlen.
- 1 Der Automotive-Datensatz
- 2 Die Fragestellung
- 3 Ablauf der Datenanalyse
- 4 Was ist ein Entscheidungsbaum?
- 5 Vorbereitung der Entwicklungsumgebung
- 6 Umsetzung der Machine Learning-Pipeline
6-1 Daten einlesen und vorbereiten
6-2 Zielvariable und Trainingsdaten
6-3 Entscheidungsbaum-Modell erstellen
6-4 Optimierte Visualisierung mit Graphviz - 7 Performance-Evaluierung
7-1 Vorhersage mit predict
7-2 Metriken: Accuracy, Precision, Recall
7-3 Kreuzvalidierung
7-4 Konfusionsmatrix und ROC-Kurve - 8 Interaktive Visualisierung
- Nächste Schritte
Die Tutorials können unten als Python-Skript (*.py) oder als Jupyter Notebook (*.ipynb) heruntergeladen werden.
1 Der Automotive-Datensatz
Der Automobildatensatz ist eine csv-Datei, die aus 648 Beobachtungen besteht. Jede Beobachtung / Zeile enthält numerische Sensorwerte zu insgesamt 22 Merkmalen, sowie die Spalte Ausfall, die nur zwei Werte annimmt: 0 für "kein Ausfall", und 1 für "Ausfall". Die erhobenen Merkmalswerte stammen aus Temperatur- und Druckmessungen sowie Mengenangaben zum Kraftstoff und zu Abgasdämpfen, die an verschiedenen Stellen im Motor erfasst wurden. Weiterhin enthält der Datensatz acht Merkmale zu den Lambdasonden, die an jeweils einem Zylinder im Motor Messwerte liefern und in 2 Bänke unterteilt sind. Z.B. das Merkmal Lambdasonde32 gibt den Sensorwert vom dritten Zylinder innerhalb der zweiten Bank an. Als Trennzeichen für die Spalten wird das Semikolon verwendet.
Ausfall;Kuehlmitteltemp;EinspritzmKurz;EinspritzmLang;Kraftstoffdruck;Ansaugkrdruck;Drosselklstellung;Einlasslufttemp;LS11;LS21;LS22;LS41;LS12;LS22.1;LS32;LS42;Kraftstoffleitdruck;Abgasrueckf;Kraftstoffdampfsaeub.;Kraftstoffeinsatz;EVAPDruck;Luftdruck;KatTemp 0;3.0;7.0;27.7;12.0;4.1;2.9;2.0;1.4;1.5;1.3;1.0;0.8;0.5;1.7;1.6;1.2;1.4;1.0;1.0;0.4;0.3;0.2 0;7.0;27.2;12.5;4.9;3.1;2.6;1.7;1.4;1.4;1.4;0.8;0.8;0.5;2.4;2.4;2.2;2.5;2.4;2.8;3.0;3.0;3.1 0;3.3;28.5;8.9;5.0;3.7;3.1;1.9;1.5;1.5;1.4;1.1;0.9;0.9;1.5;1.5;1.3;1.2;1.1;1.1;0.3;0.3;0.1 1;1.8;2.4;3.1;10.7;18.6;11.4;11.5;1.2;1.8;1.5;1.2;0.6;0.5;2.4;2.2;0.2;0.3;0.6;0.7;0.7;0.9;0.5 0;11.2;21.1;18.0;7.8;3.0;2.2;0.8;0.5;0.4;0.2;0.4;0.2;3.1;0.7;1.2;1.8;1.1;1.9;0.8;2.6;2.3;2.7
Der Automotive-Datensatz ist nicht ganz balanciert: denn die Anzahl der Beobachtungen mit Label "Kein Ausfall" beträgt etwa 2/3, die der Beobachtungen mit Label "Ausfall" nur ein Drittel der Zeilen. Diese Information ist wichtig für die Art, wie der Entscheidungsbaum konfiguriert wird und welche Performance-Kennzahlen relevant sind. Bei balancierten Entscheidungsbäumen kann die Kennzahl Accuracy als Performance-Kennzahl verwendet werden, sie ist ein Maß für den Anteil an falschen Klassifikationen. Bei nicht balancierten Datensatzen, die nur wenige Ausfälle enthalten, sind andere Kennzahlen zu verwenden, genauer: Recall.
Dieser Automotive-Datensatz enthält keine Timestamps, d.h. die Beobachtungen stammen nicht aus regelmäßig nacheinanderfolgenden Messungen. Es liegen lediglich Vergangenheitsdaten vor, bei denen bekannt ist, bei welcher Kombination von Sensorwerten ein Ausfall aufgetreten ist. Für derartige Datensätzen können Machine Learning-Algorithmen wie Entscheidungsbäume, Random Forest oder Isolation Forest eingesetzt werden, es sind jedoch keine Zeitreihenanalysen möglich. Datensätze, die in der Produktion auftreten, und als Zeitreihen erfasst werden, enthalten seltener Ausfälle und sind damit nicht balanciert.
2 Die Fragestellung
Uns interessiert, welche Merkmalskombinationen, d.h. welches Zusammenspiel der Sensorwerte, zu einem Ausfall des Motors führen. Die Frage, die der Entscheidungsbaum beantworten soll, lautet also: Welche Kombination von Merkmalen wird zu einem Ausfall führen? Werden alle Merkmale einen Einfluss auf den Ausfall haben und falls nein, mit welchem Gewicht werden welche Merkmale einen Ausfall bewirken?
3 Ablauf der Datenanalyse
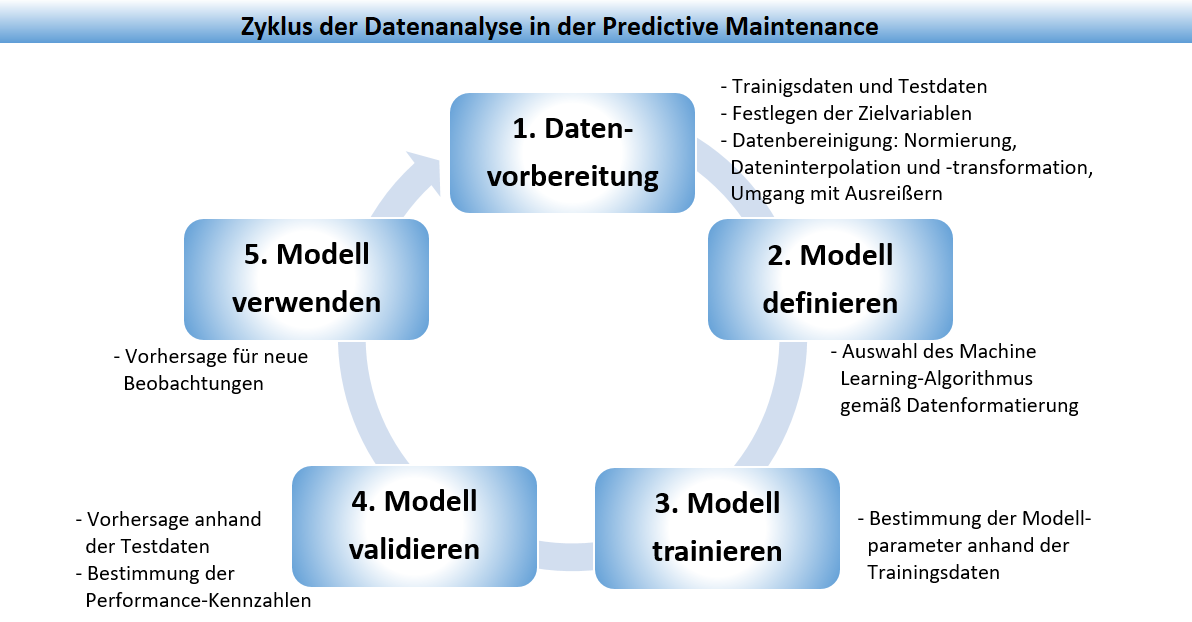
Die Datenanalyse für die Predictive Maintenance läuft in fünf Schritten ab, wobei einige der Teilschritte je nach Daten und ausgewähltem Modell auch entfallen können. Z.B. ist bei einem Entscheidungsbaum-Modell keine Normalisierung der Daten erforderlich.
- Schritt 1. Datenvorbereitung: Der Datensatz wird in Trainings- und Testdaten zerlegt, die Zielvariable wird festgelegt und die Daten
werden bereinigt, d.h. je nach Datenlage normalisiert und transformiert, bei fehlenden Werte interpoliert und durch Algorithmen werden
Ausreißer erkannt und behandelt.
- Schritt 2. Modell definieren: Gemäß den Daten wird ein passendes Modell gewählt, dies kann ein Entscheidungsbaum-Modell für
Klassifikation oder Regression sein, oder eine Nächste Nachbarn-Klassifikation, dies hängt von der Fragestellung ab.
- Schritt 3. Modell trainieren: Mit den Trainingsdaten wird das Modell erstellt, d.h. die Parameter des Modells geschätzt, z.B. die Verzweigungen und Blätter eines Entscheidungsbaums, oder die Parameter als Kleinste-Quadrate-Schätzer in einem Regressionsmodell.
- Schritt 4. Modell validieren: Das Modell wird auf die Testdaten angewendet um eine Vorhersage zu erhalten, der Vergleich
der Vorhersagen mit den bekannten Werten der Zielvariablen liefert die
Performance-Kennzahlen, die den Testfehler beschreiben, und angeben wie gut ein
Modell ist.
- Schritt 5. Modell verwenden: Durch Anwendung des Modells auf neue Beobachtungen, bei denen die Werte der Zielvariablen unbekannt sind, Vorhersagen getätigt.
4 Was ist ein Entscheidungsbaum?
Ein binärer Entscheidungsbaum ist ein Klassifikationsmodell, mit dessen Hilfe eine Ja-Nein Fragestellung beantwortet werden kann. In einem Predictive Maintenance-Szenario soll z.B. vorhergesagt werden, ob bei einer bestimmten Kombination von Messungen ein Ausfall eintritt oder nicht. Diese "Vorhersage" ist strenggenommen eine Klassifikation, also eine Funktion / Zuordnung, die die Merkmale einer Beobachtung auf die korrekten Zustände ("Ausfall" oder "Kein Ausfall") abbildet. Das Modell entsteht, indem die Datentabelle, die bei der Datenerhebung erfasst wurde, um eine Spalte ergänzt wird, die Zielvariable genannt wird und die die Bewertung des Zustands enthält. Für die Vergangenheitsdaten ist die Bewertung bekannt, für neue Daten wird die Bewertung durch das Modell vorhergesagt.
Ein Entscheidungsbaum besteht aus einer Wurzel, Knoten und Blättern, wobei jeder Knoten eine Entscheidungsregel und jedes Blatt eine Antwort auf die Fragestellung darstellt. Um eine Klassifikation eines einzelnen Datenobjektes abzulesen, geht man vom Wurzelknoten entlang des Baumes abwärts. Bei jedem Knoten wird ein Merkmal abgefragt und eine Entscheidung über die Auswahl des folgenden Knoten getroffen. Dies wird so lange fortgesetzt, bis man ein Blatt erreicht. Das Blatt entspricht der Klassifikation.
Mini-Beispiel
Zur Veranschaulichung betrachten wir einen Datensatz mit Sensor-Messwerten mit nur zwei Merkmalen: Temperatur und Druck und einer Zielvariablen: Ausfall.
Der Entscheidungsbaum für das Mini-Beispiel gibt eine Antwort auf die Frage,
bei welcher Kombination von Werten für die Merkmale temp und druck das Gerät ausfallen wird.
Datensatz mit Zielvariable
| id | temp | druck | ausfall |
|---|---|---|---|
| 1 | normal | hoch | nein |
| 2 | hoch | normal | nein |
| 3 | hoch | hoch | ja |
| 4 | hoch | normal | ja |
| 5 | hoch | hoch | ? |
Die Zeilen 1 bis 4 enthalten die Vergangenheitsdaten mit bekannter Bewertung der Zielvariablen. Zeile 5 enthält eine neue Beobachtung, für die auf Basis des Entscheidungsbaums der Ausfall vorhergesagt wird.
Entscheidungsbaum
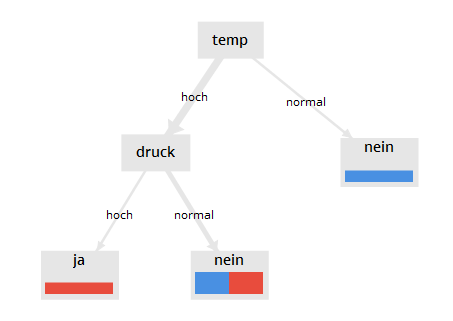
Wenn die Temperatur hoch und der Druck hoch ist, wird ein Ausfall vorhergesagt. Wenn die Temperatur normal ist, wird kein Ausfall eintreten.
Wie entsteht der Entscheidungsbaum?
Die genaue Form des Entscheidungsbaums entsteht durch den Trainingsprozess des überwachten Lernens.
Die Input-Daten werden in Trainingsdaten und Testdaten unterteilt.
Auf Basis der Trainingsdaten wird mittels eines passenden Algorithmus (CART, C4.5 oder ID3) der Entscheidungsbaum erstellt,
dessen Güte mit Hilfe von Performance-Kennzahlen
(z.B. Vertrauenswahrscheinlichkeit, Genauigkeit, Trefferquote) ermittelt wird.
Der Trainingsprozess wird solange wiederholt, bis das Modell eine gewünschte Performance erreicht.
Danach kann es für die Vorhersage auf neuen Datensätzen verwendet werden.
5 Vorbereitung der Entwicklungsumgebung
Als Vorbereitung für die Umsetzung der Machine Learning Pipeline mit Python muss zunächst die Entwicklungsumgebung Visual Studio Code installiert werden, sowie eine neuere Python-Version und drei Python-Bibliotheken für Datenanalyse und Machine Learning: NumPy, Pandas und ScikitLearn.
Grundlagen der Python-Programmierung mit Visual Studio Code werden in Demo-PY1: Python-Tutorial
beschrieben.
Die Verwendung benötigter Python-Bibliotheken wie Numpy, Pandas und Scikit-Learn werden im dritten Teil des
Python-Tutorials
"Python-Bibliotheken"
genauer beschrieben.
Die Details der Verwendung von Jupyter Notebooks sind im Tutorial
Jupyter Notebooks verwenden
beschrieben.
Für die Programmierung des Entscheidungsbaum-Vorhersagemodells kann anschließend entweder ein Python-Skript oder ein Jupyter Notebook erstellt werden. Um in Visual Studio Code mit Jupyter Notebooks arbeiten zu können, muss die Jupyter Extension installiert werden. Das Arbeiten mit Jupyter Notebook hat den Vorteil, dass man Codezellen separat ausführen kann, dies ist vor allem beim Ausprobieren neuer Funktionen nützlich.
Benötigte Programmbibliotheken
NumPy wird für die Speicherung und Verarbeitung der Daten in mehrdimensionale Arrays benötigt.
Pandas wird für das Lesen des Datensatzes aus der csv-Datei in eine interne Datenstruktur (DataFrame)
und statistische Auswertung der Daten benötigt.
Scikit-Learn bildet gängige Machine Learning-Algorithmen ab und besteht aus Modulen, die die Funktionen entsprechend der
Machine Learning-Pipeline gruppieren. Das Modul tree enthält Klassen wie DecisionTreeClassifier und RandomForest.
Das Modul preprocessing enthält Funktionen für Datenvorbereitung, z.B. Skalierung der Daten.
Das sklearn-Modul metrics enthält Funktionen, mit denen man die Güte eines Vorhersagemodells bewerten kann.
Wir importieren nur diejenigen Scikit-Learn Klassen und Funktionen, die in unserem Anwendungsfall benötigt werden, insbesondere:
DecisionTreeClassifier, train_test_split, cross_validate, KFold,
Scikit-Learn wird laufend weiterentwickelt, z.B. sind einige Funktionen aus dem Modul metrics erst ab der Version 1.7 verfügbar. Die Version der Scikit-Learn Installation kann im Terminal überprüft werden, mit dem folgenden Befehl:
pip show scikit-learn
6 Umsetzung der Machine Learning Pipeline
Die Machine Learning Pipeline zur Erstellung eines Entscheidungsbaum-Vorhersagemodells besteht in der Abfolge der der Schritte: 1. Daten einlesen und vorbereiten, 2. Zielvariable und Trainingsdaten festlegen, 3. Vorhersagemodell erstellen, 4. Performance evaluieren, 5. Modell auf neue Daten anwenden.
6-1 Datenvorbereitung: Daten einlesen
Im Schritt "Datenvorbereitung" werden die Daten aus der csv-Datei automotive_data_648.csv eingelesen und statistisch untersucht.
Python-Code: "Daten einlesen"Ausgabe:import numpy as npimport pandas as pd# Daten aus csv-Datei einlesenfile = "https://www.elab2go.de/demo-py4/automotive_data_648.csv"df = pd.read_csv(file, header=0, index_col=None, sep = ";")# Überprüfe Größe des Arraysprint(f"Anzahl Zeilen {df.shape[0]}, Anzahl Spalten: {df.shape[1]}")# Überprüfe Ausfallverteilungprint("Ausfallverteilung")print(df['Ausfall'].value_counts())
Anzahl Zeilen 648, Anzahl Spalten: 23 Ausfallverteilung: Ausfall 0 420 1 228
Verwendete Funktionen
Mit import werden benötigte Bibliotheken importiert.
In Python kann mit Hilfe der import-Anweisung entweder eine komplette Programmbibliothek importiert werden,
oder nur einzelne Funktionen (from-import-Anweisung).
Beim Import werden für die jeweiligen Bibliotheken oder Funktionen Alias-Namen vergeben: für Numpy vergeben wird den Alias np,
für Pandas vergeben wir den Alias pd.
Die Pandas-Funktion read_csv() liest Daten aus einer CSV-Datei in ein DataFrame df ein.
Sie erhält als ersten Parameter den Namen der einzulesenden Datei, hier als URL angegeben. Falls die Datei lokal in demselben Ordner
wie das Skript gespeichert wird, kann auch einfach der Dateiname angegeben werden, ohne Pfadangaben.
Die weiteren Parameter sind Optionen, die den Import steuern.
header=0 bedeutet, dass die erste Zeile der CSV-Datei Spaltenüberschriften enthält.
index_col=0 bedeutet, dass die erste Spalte Zeilenüberschriften enthält.
sep = ";" bedeutet, dass ein Semikolon als Trennzeichen (engl. separator) verwendet wird.
df.shape ermittelt die Dimensionen des Datensatzes, df.shape[0] die Anzahl der Zeilen,
df.shape[1] die Anzahl der Spalten. Wir überprüfen die Dimensionen des DataFrames um zu sehen, dass alle Zeilen und Spalten korrekt
eingelesen wurden.
Mit df['Ausfall'].value_counts() wird Anzahl der Zeilen mit Label "Ausfall" vs. "kein Ausfall" gezählt.
Statistische Auswertung des Datensatzes
Die statistische Untersuchung des Datensatzes ist wichtig, um herauszufinden, welche von den vielen Spalten
stärker mit dem Ausfall korreliert sind, und welche statistischen Eigenschaften die Spalten im allgemeinen haben.
Zunächst werden die Spalten bestimmt, die eine Korrelation > 0.25 mit dem Ausfall haben.
Ausgabe:# Bestimme die Spalten, die eine Korrelation > 0.25 mit dem Ausfall habencorr = df.corr()cor_target= abs(corr["Ausfall"])relevant_features = cor_target[cor_target > 0.25]print("Relevante Merkmale:")print(relevant_features)print("Statistik:")print(df[["Drosselklstellung", "Ansaugkrdruck"]].describe() )
Relevante Merkmale:
Ausfall 1.000000
EinspritzmKurz 0.293867
Ansaugkrdruck 0.297388
Drosselklstellung 0.293468
Einlasslufttemp 0.305100
Name: Ausfall, dtype: float64
Statistik:
Drosselklstellung Ansaugkrdruck
count 648.000000 648.000000
mean 6.183025 11.109414
std 5.584624 9.046221
min 0.600000 0.600000
25% 2.700000 4.175000
50% 4.300000 8.000000
75% 8.000000 15.100000
max 26.600000 32.100000
Verwendete Funktionen
Die Pandas-Funktion df.corr berechnet die paarweise Korrelation der Spalten eines DataFrames.
Das Ergebnis ist eine Matrix, deren Einträge Werte zwischen 0 und 1 sind, wobei ein Wert größer als 0.25
als eine vorhandene Korrelation interpretiert werden kann.
df.describe() ist eine Pandas-Funktion, die statistische Kennzahlen wie
Anzahl Werte, Mittelwert und Standardabweichung der Spalten eines Datensatzes ausgibt.
6-2 Datenvorbereitung: Zielvariable und Trainingsdaten festlegen
Das Entscheidungsbaum-Modell ist ein Algorithmus des Überwachten Lernens, d.h. der Entscheidungsbaum wird aufgebaut, indem man ihn anhand der Vergangenheitsdaten mit bekannter Zielvariable "Ausfall" trainiert. Als Vorbereitung für das Training des Entscheidungsbaum-Modells müssen die Daten, die in Form eines DataFrames df vorliegen, in passende Datenstrukturen extrahiert und aufgeteilt werden.
Zunächst werden die Merkmale von der Zielvariablen getrennt: Alle Spalten außer der Spalte "Ausfall" werden in ein neues DataFrame x extrahiert.
Die Spalte "Ausfall" wird als Zielvariable in ein DataFrame y extrahiert.
Danach werden Merkmale und Zielvariable jeweils in einen Trainings- und einen Testdatensatz aufgeteilt.
Der Trainingsdatensatz wird verwendet, um das Vorhersagemodell zu erstellen und der Testdatensatz wird verwendet, um das Modell zu validieren.
Ausgabe:from sklearn.model_selection import train_test_split# Merkmale x = Alle Spalten, außer Ausfallx = df.drop('Ausfall', axis=1)# Zielvariable y = Spalte Ausfally = df[['Ausfall']]# Überprüfe die extrahierten DataFrames x, yprint("Merkmale x:")print(x.iloc[:,0:3].head())print("\nZielvariable y:")print(y.head())# Aufteilung in Trainings- und TestdatenX_train, X_test, y_train, y_test = \train_test_split(x, y, test_size=0.2, random_state=1)
Merkmale x (erste drei Spalten): Kuehlmitteltemp EinspritzmKurz EinspritzmLang 0 3.0 7.0 27.7 1 7.0 27.2 12.5 2 3.3 28.5 8.9 3 1.8 2.4 3.1 4 11.2 21.1 18.0 Zielvariable y: Ausfall 0 0 1 0 2 0 3 1 4 0
Verwendete Funktionen
Die Funktion train_test_split() erhält die Arrays x und y als Eingabeparameter und gibt vier Arrays zurück:
X_train: Trainingsdaten (nur Merkmale), X_test: Testdaten (nur Merkmale)
y_train: Trainingsdaten (Zielvariable), y_test: Testdaten (Zielvariable)
Der Parameter test_size steuert die Größe des Test-Datensatzes, hier: 30%.
Die Daten können optional auch normalisiert werden, dies kann die Performance des Entscheidungsbaums verbessern.
Python-Code: "Daten normalisieren"from sklearn.preprocessing import StandardScaler scaler = StandardScaler() X_train = scaler.fit_transform(X_train) X_test = scaler.transform(X_test)
6-3 Entscheidungsbaum-Modell erstellen
Das Vorhersagemodell für die Trainingsdaten (X_train, y_train) wird mit Hilfe der Methode fit() der Scikit-Learn-Klasse DecisionTreeClassifier erstellt. Der DecisionTreeClassifier verwendet eine optimierte Version des CART-Algorithmus. Beim Erstellen des Modells als Instanz der Klasse DecisionTreeClassifier werden verschiedene Konfigurationsparameter festgelegt, die steuern, wie genau der Entscheidungsbaum aufgebaut wird, die wichtigsten sind: criterion, splitter, max_depth, min_samples_split, min_samples_leaf, max_features.
Python-Code: "Modell trainieren"import matplotlib.pyplot as pltfrom sklearn.tree import DecisionTreeClassifierfrom sklearn import tree# Modell erstellenmodel = DecisionTreeClassifier(criterion='entropy',min_samples_split=5,min_samples_leaf=5,max_depth=10,random_state=1)# Modell trainierenmodel.fit(X_train, y_train)# Modell visualisierenfig, ax = plt.subplots(figsize=(10, 10))tree.plot_tree(model, max_depth = 5,feature_names = x.columns, class_names=["nein", "ja"], filled=True)plt.show()
Verwendete Funktionen
DecisionTreeClassifier erstellt das Entscheidungsbaum-Modell, welches über Parameter konfiguriert wird:
- -- criterion: legt fest, wie die Güte einer Aufteilung (Split) an einem Knoten gemessen wird. Mögliche Optionen: "gini" oder "entropy".
- -- splitter: beschreibt mit welcher Strategie der nächste Knoten aufgeteilt wird.
- -- splitter = 'random' bedeutet, dass ein zufälliges Merkmal ausgewählt wird um den Knoten aufzuteilen.
- -- splitter = 'best' bedeutet, dass das relevanteste Merkmal ausgewählt wird, um den Knoten aufzuteilen.
- -- max_depth: maximale Tiefe des Entscheidungsbaums. Der Default-Wert für max_depth ist "None", d.h. der Baum kann beliebig tief werden, dies kann jedoch zu Überanpassung des Modells an die Trainingsdaten führen. Wir setzen hier max_depth = 5.
- -- min_samples_split: bestimmt die minimal erforderliche Anzahl der Beobachtungen für die Aufteilung eines Knotens. Kann als absolute Zahl (kleinster Wert: 1, größter Wert: Anzahl der Beobachtungen) oder in Prozent (kleinster Wert: 0.1, größter Wert: 1.0) angegeben werden. Wir setzen min_samples_split = 0.3, d.h. ein Knoten wird nur aufgeteilt, wenn er mehr als 30% der Datensätze enthält.
- -- min_samples_leaf: bestimmt die kleinste Anzahl der Beobachtungen, die ein Blatt enthalten muss.
- -- max_features: gibt die Anzahl der Merkmale an, die bei der Suche nach der besten Aufteilung berücksichtigt werden.
model.fit() passt den Entscheidungsbaum an die Trainingsdaten an.
plot_tree() visualisiert den Entscheidungsbaum.
Die Visualisierung mit plot_tree kann über verschiedene Parameter konfiguriert werden.
Muss-Angaben sind feature_names: die Merkmals-Namen bzw. Spaltennamen und class_names: die Werte, die die Zielvariable annehmen
kann, in aufsteigender numerischer Reihenfolge, daher nein = 0 zuerst.
6-4 Optimierte Visualisierung mit Graphviz
Die Visualisierung des Entscheidungsbaums wird mit Hilfe der Bibliothek Graphviz und der scikit learn-Funktion export_graphviz() erstellt. Graphviz ist ein Open-Source-Programmpaket zur Visualisierung von Graphen. Graphviz entnimmt alle zur Erzeugung der Grafik benötigten Anweisungen einer Textdatei, die eine Beschreibung der Knoten und Kanten des Graphen enthält, und zwar in der DOT-Beschreibungssprache für die visuelle Darstellung von Graphen.
Zunächst wird in Zeile 2-5 mit Hilfe der Funktion export_graphviz() der Entscheidungsbaum in das graphviz-DOT-Format exportiert. Daraus wird dann in Zeile 7 ein Graph erzeugt und in Zeile 8 in der Jupyter Notebook Ausgabe angezeigt. Wichtig: Um Graphviz zu verwenden, reicht es nicht, das entsprechende Python-Paket zu installieren, sondern Graphviz muss als eigene Anwendung auf Ihrem Rechner installiert und über die PATH-Variable bekannt sein.
Python-Code: "Optimierte Visualisierung"Ausgabe:# Erzeuge Graphviz-Graphen aus dot-Quellcodeimport graphviz as gvimport pydotfrom sklearn.tree import export_graphvizdot=export_graphviz(model, max_depth=5, filled=True,feature_names=x.columns,class_names=['nein','ja'])pdot = pydot.graph_from_dot_data(dot)pdot[0].set_graph_defaults(size = "\"8,6\"")pdot[0].set_fontsize(18)graph = gv.Source(pdot[0].to_string())graph.render("images/decisiontree", format='svg', view=False)

7 Performance-Evaluation
Um ein Entscheidungsbaum-Vorhersagemodell zu validieren, verwendet man Performance-Kennzahlen wie Accuracy, Precision, Recall, statistische Verfahren wie die Kreuzvalidierung und Visualisierungen wie die ROC-Kurve, die angeben, wie gut der Wert der Zielvariablen mit dem entsprechenden Modell vorhergesagt wird.
7-1 Vorhersage erstellen
Die Berechnung von Performance-Kennzahlen erfordert stets die Durchführung einer Vorhersage. Die Vorhersage geschieht mit Hilfe der Scikit-Learn-Funktion predict(), es werden die beim Training abgezweigten Testdaten X_test verwendet, und man erhält ein NumPy-Array y_pred, das die Vorhersagewerte enthält. Anschließend kann man mit Hilfe der Funktionen des Moduls sklearn.metrics verschiedene Kennzahlen berechnen. Die Funktion classification_report gibt eine tabellarische Übersicht der wichtigsten Performance-Kennzahlen aus. Die Funktionen accuracy_score, precision_score und recall_score werden verwendet, um die Kennzahlen einzeln zu ermitteln.
Python-Code: "Vorhersage"Ausgabe: Classification Reportfrom sklearn.metrics import classification_reportfrom sklearn.metrics import accuracy_score, precision_score, recall_scorey_pred = model.predict(X_test)print(classification_report(y_test, y_pred))print('PERFORMANCE-KENNZAHLEN:')acc = 100 * accuracy_score(y_test, y_pred)prec = 100 * recall_score(y_test, y_pred)rec = 100 * precision_score(y_test, y_pred)print(f"f"Accuracy: {acc}\nPrecision: {prec}\nRecall: {rec}")
precision recall f1-score support
0 0.91 0.95 0.93 87
1 0.90 0.81 0.85 43
accuracy 0.91 130
macro avg 0.90 0.88 0.89 130
weighted avg 0.91 0.91 0.91 130
PERFORMANCE-KENNZAHLEN:
Accuracy: 90.76923076923077
Precision: 81.3953488372093
Recall: 89.74358974358975
Wie werden die Kennzahlen ermittelt? Ein Blick hinter die Kulissen
Nach Durchführung einer Vorhersage hat man zwei Arrays, y_test = [0, 1, 1, 1, ...] und y_pred = [0, 0, 1, 1, ...], wobei das erste Array y_test die erwartete Klassifizierung und das zweite Array y_pred die Vorhersagewerte enthält. Die Güte der Klassifizierung wird aus der Menge der Übereinstimmungen abgeleitet, dabei verwendet man als Ausgangspunkt die Kategorien TP, TN, FP, FN:
- True Positive (TP): falls erwarteter Wert und Vorhersage beide positiv sind
- True Negative (TN): falls erwarteter Wert und Vorhersage beide negativ sind
- False Positive (FP): falls erwarteter Wert negativ (0) und Vorhersage positiv (1) ist
- False Negative (FN): falls erwarteter Wert positiv (1) und Vorhersage negativ (0) ist
Die Metriken Accuracy, Precision, Recall und F1-Score werden aus diesen Kategorien berechnet, z.B. Accuracy anhand der Formel Accuracy = (TP + TN) / (TP + TN + FP + FN), wie im folgenden Beispiel-Code. Das Scikit-Learn-Modul metrics stellt die Funktionen für die Berechnung schon zur Verfügung, so dass eine ausführliche Berechnung wie im folgenden Beispiel entfällt - es sei denn, man sucht ein tieferes Verständnis der Herleitung.
Python-Code: "Wie werden Kennzahlen TP, TN, FP, FN ermittelt?"Ausgabe: Testdaten mit Vorhersage und Kategorie TP, TN, FP, FNtestdata = {'ytest' : y_test['Ausfall'].to_numpy(),'ypred' : y_pred,'K': ' ',}df_y = pd.DataFrame(testdata)df_tp = df_y[(df_y['ytest'] == 1) & (df_y['ypred'] == 1)]df_tn = df_y[(df_y['ytest'] == 0) & (df_y['ypred'] == 0)]df_fp = df_y[(df_y['ytest'] == 0) & (df_y['ypred'] == 1)]df_fn = df_y[(df_y['ytest'] == 1) & (df_y['ypred'] == 0)]df_y.loc[df_tp.index, 'K'] = 'TP'df_y.loc[df_tn.index, 'K'] = 'TN'df_y.loc[df_fp.index, 'K'] = 'FP'df_y.loc[df_fn.index, 'K'] = 'FN'print("Vorhersagen mit Kategorie TP, TN, FP, FN:\n", df_y.head())tptn = df_tp['K'].count() + df_tn['K'].count()tptnfpfn = df_tp['K'].count() + df_tn['K'].count() + \df_fp['K'].count() + df_fn['K'].count()acc = tptn / tptnfpfnprint(f"Accuracy = (TP + TN) / (TP + TN + FP + FN):\n{acc}")
Vorhersagen mit Kategorie TP, TN, FP, FN:
ytest ypred kat
0 0 0 TN
1 1 0 FN
2 1 1 TP
3 1 1 TP
4 0 0 TN
Accuracy = (TP + TN) / (TP + TN + FP + FN):
0.9076923076923077
7-2 Performance-Kennzahlen: Accuracy, Precision und Recall
Die Performance-Kennzahlen Accuracy, Precision und Recall und F1-Score werden aus den absoluten Zahlen True Positive, True Negative, False Positive und False Negative ermittelt, ähnlich wie in Abschnitt 7-1 beschrieben. Der Wertebereich der Kennzahlen ist jeweils [0, 1] bzw. [0%, 100%].
- Accuracy (Vertrauenswahrscheinlichkeit)
ACC = (TN + TP) / (TN + TP + FN + FP)
Anteil der korrekt getroffenen Vorhersagen (Ausfall oder kein Ausfall)
ACC = 1 falls FP = 0 und FN = 0. - Recall / True Positive Rate
REC = TPR = TP / (TP + FN)
Trefferquote bzw. Erkennungswahrscheinlichkeit eines Ausfalls
REC = 100%, falls es keine nicht erkannten Ausfälle gibt
REC = 0 falls TP = 0, REC = 1 falls FN = 0 - Precision (Genauigkeit)
PREC = TP / ( TP + FP)
Anteil der korrekt erkannten Ausfälle an der Gesamtmenge der Ausfälle
PREC = 100%, falls nichts als Ausfall klassifiziert wurde, was keiner war
PREC = 0 falls TP = 0, PREC = 1 falls FP = 0 - False Positive Rate
FPR = FP / ( FP + TN)
Wahrscheinlichkeit eines Fehlalarms
FPR = 0 falls FP = 0, FPR = 1 falls TN = 0 - F1-Score
F1-Score = 2 * (PREC * REC) / (PREC + REC)
Harmonisches Mittel aus Precision und Recall, berücksichtigt das Gleichgewicht der beiden Kennzahlen.
Wertebereich [0, 1], wobei 1 nur erreicht wird, wenn PREC und REC optimal sind. Ein F1-Wert > 0.7 gilt als gute Performance.
In einem Predictive Maintenance-Szenario entstehen dem Unternehmen einerseits Kosten,
falls ein Ausfall nicht als solcher erkannt wird, es entstehen andererseits auch Kosten,
wenn fälschlicherweise ein Ausfall vorhergesagt und die Produktion unterbrochen wird.
Diese beiden Fälle werden durch die Kennzahlen Recall und Precision abgebildet, die beide wichtig,
allerdings komplementär sind: sie können nicht gleichzeitig maximiert werden.
Dies bedeutet, dass man Entscheidungsbäume entweder für die Kennzahl "Precision" oder für die Kennzahl "Recall" optimieren kann,
oder für einen Kompromiss aus beiden: die Kennzahl
F1-Score = 2 * (PREC * REC) / (PREC + REC).
7-3 Performance-Evaluation mit Kreuzvalidierung
Die Kreuzvalidierung ist ein statistisches Validierungsverfahren für die optimierte Bestimmung der Performance Kennzahlen,
bei dem in mehreren Durchgängen aus den Daten jeweils eine Teilmenge ausgelassen und zum Validieren verwendet wird, das ergibt
jeweils einen Satz von Performance-Kennzahlen, die dann gemittelt werden.
Bei der 5-fachen Kreuzvalidierung werden z.B. die Daten in fünf gleich große Teilmengen (Folds) aufgeteilt.
Das Modell wird jeweils mit vier Teilmengen trainiert und mit der verbleibenden Teilmenge getestet.
Dieser Ablauf wird fünfmal wiederholt, wobei jeder Fold einmal als Testdatensatz dient, und jeder Durchgang liefert
Satz von Performance-Kennzahlen. Die Performance-Kennzahlen aus den unterschiedlichen Durchgängen werden am Ende gemittelt.
Ausgabe:from sklearn.metrics import accuracy_score, precision_score, recall_scorefrom sklearn.model_selection import cross_validate, KFoldy_pred = model.predict(X_test)# Ermittle Genauigkeit der Vorhersage mittels Kreuzvalidierung# accuracy, precision, recall, f1, roc_auck_folds = KFold(n_splits = 5, shuffle = True, random_state = 1)np.set_printoptions(precision=2)scores = cross_validate(model, X_train, y_train,scoring=['accuracy', 'precision', 'recall', 'f1'],cv = k_folds,return_estimator=True, return_indices=True)acc = round(100*scores['test_accuracy'].mean(), 2)prec = 100*scores['test_precision'].mean()rec = 100*scores['test_recall'].mean()print(f"Kreuzvalidierung:\n Accuracy: {acc}, Precision: {prec}, Recall: {rec}")
Kreuzvalidierung: Accuracy: 86.68 Precision: 88.24486519173426 Recall: 73.78848208555635
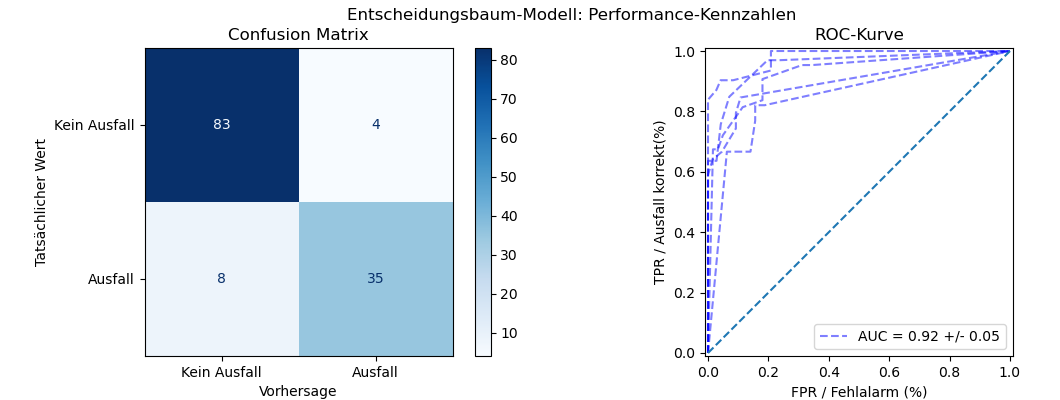
7-4 Confusion Matrix und ROC-Kurve
Die Python-Bibliothek Scikit-Learn stellt für die Visualisierung der Performance-Metriken verschiedene
optimierte Displays für Konfusionsmatrix und ROC-Kurven zur Verfügung, die es ermöglichen, die Güte eines Modells auf einen Blick zu erkennen.
Die Konfusionsmatrix visualisiert
die Kennzahlen TP, TN, FP und FN in einer Matrix, die die Werte in vier Blöcken anordnet, wobei die Treffer die Hauptdiagonale bilden,
und die falschen Vorhersagen auf der zweiten Diagonale angezeigt werden.
################### # # # Oben links: Kein Ausfall, und korrekt erkannt # TN # FP # Oben rechts: FP = Fehlalarm # # # ################### # # # Unten links: FN = Nicht erkannter Ausfall # FN # TP # Unten rechts: TP = Ausfall, korrekt erkannt # # # ###################
Falls die Konfusionsmatrix hohe Werte auf der Hauptdiagonale und kleine Werte auf der zweiten Diagonale hat, zeigt das Modell eine gute Performance.
Die ROC-Kurve stellt die TP-Rate (y-Achse) gegen die FP-Rate (x-Achse) bei verschiedenen Werten zwischen 0 und 1 dar. Ein gutes Modell hat eine ROC-Kurve, die links oben hoch gezogen ist (hoher TPR bei kleinem FPR) und somit die Fläche unter der Kurve maximiert.
Python-Code: "Konfusionsmatrix und ROC-Kurve"from sklearn.metrics import (confusion_matrix,ConfusionMatrixDisplay, RocCurveDisplay)fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(14, 4))fig.suptitle('Entscheidungsbaum-Modell: Performance-Kennzahlen')# Konfusionsmatrixcm = confusion_matrix(y_test, y_pred)disp_cm = ConfusionMatrixDisplay(cm,display_labels=["Kein Ausfall", "Ausfall"])disp_cm.plot(values_format="d", cmap=plt.cm.Blues, ax = ax1)ax1.set_title("Confusion Matrix")ax1.set_xlabel("Vorhersage"); ax1.set_ylabel("Tatsächlicher Wert")# ROC-Kurven aus Kreuzvalidierungdisp_cv = RocCurveDisplay.from_cv_results(scores, X_train, y_train, ax = ax2)ax2.plot([0, 1], [0, 1], "--", label="Zufall")ax2.set_title("ROC-Kurve")ax2.set_xlabel("FPR / Fehlalarm (%)");ax2.set_ylabel("TPR / Ausfall korrekt(%)")plt.legend(); plt.tight_layout()plt.show()
Die ROC-Kurve kann mit Scikit-Learn auf mehrere Arten erstellt werden, genauer: mit einer der drei Funktionen RocCurveDisplay.from_predictions, RocCurveDisplay.from_cv_results, oder RocCurveDisplay.from_estimator.
RocCurveDisplay.from_predictions
erhält als Parameter die tatsächlichen und vorhergesagten
Testdaten (y_test und y_pred) und erstellt daraus eine einzige ROC-Kurve.
disp_pred = RocCurveDisplay.from_predictions(y_test, y_pred) disp_pred.plot()
RocCurveDisplay.from_cv_results
erhält als Parameter die Performance-Kennzahlen (scores), die zuvor mittels Kreuzvalidierung berechnet wurden,
und erstellt insgesamt n_splits ROC-Kurven, nämlich genau so viele, wie bei der Kreuzvalidierung als Folds verwendet wurden.
In der Funktion cross_validate müssen zuvor die Parameter return_estimator=True, return_indices=True eingestellt
werden, da diese für die ROC-Kurve benötigt werden.
disp_cv = RocCurveDisplay.from_cv_results(scores, X_train, y_train) disp_cv.plot()
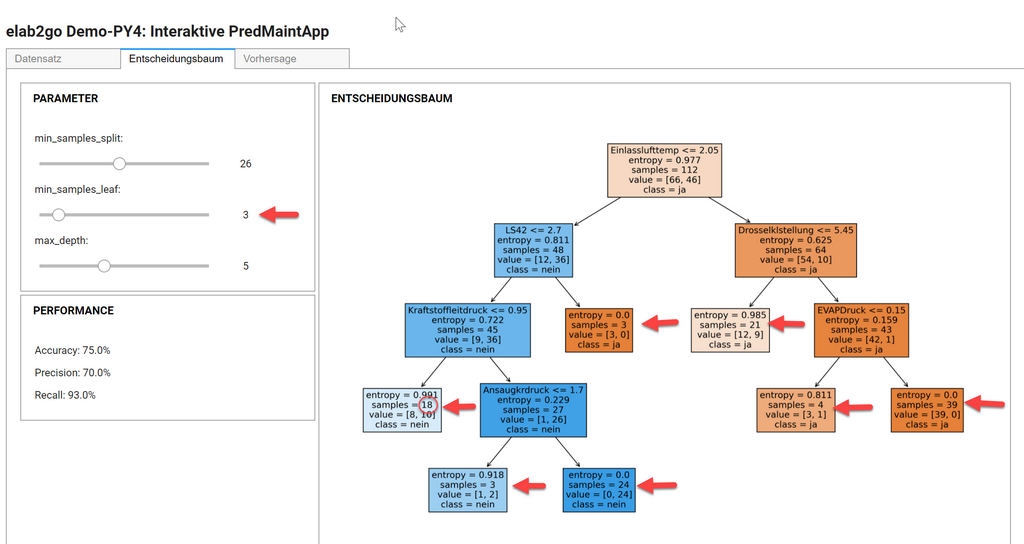
8 Interaktive Visualisierung
Nachdem die grundlegenden Funktionen der Klassifikation mit Entscheidungsbäumen getestet wurden, erstellen wir als Nächstes mit Hilfe der Jupyter Widget-Funktion interactive_output() eine interaktive Visualisierung des Entscheidungsbaums, mit dem Ziel, die Wirkung der unterschiedlichen Parameter auf die Performance des Modells zu testen.
Für die Benutzeroberfläche wurden verschiedene Design-Varianten ausprobiert: Training und Prognose auf einer Seite, Verwendung unterschiedlicher Tabs für die drei Schritte des Überwachten Lernens etc. Allen Varianten ist gemeinsam, dass die Benutzeroberfläche im oberen Bereich Steuerelemente hat, über die die wichtigsten Konfigurationsparameter eingestellt werden, und im unteren Bereich die tabellarische oder grafische Ausgabe angezeigt wird. Bei jeder Änderung eines Konfigurationsparameters wird sofort ein neues Vorhersagemodell erstellt und visualisiert. Gleichzeitig werden die Performance-Kennzahlen für den Validierungsdatensatz automatisch berechnet und angezeigt.
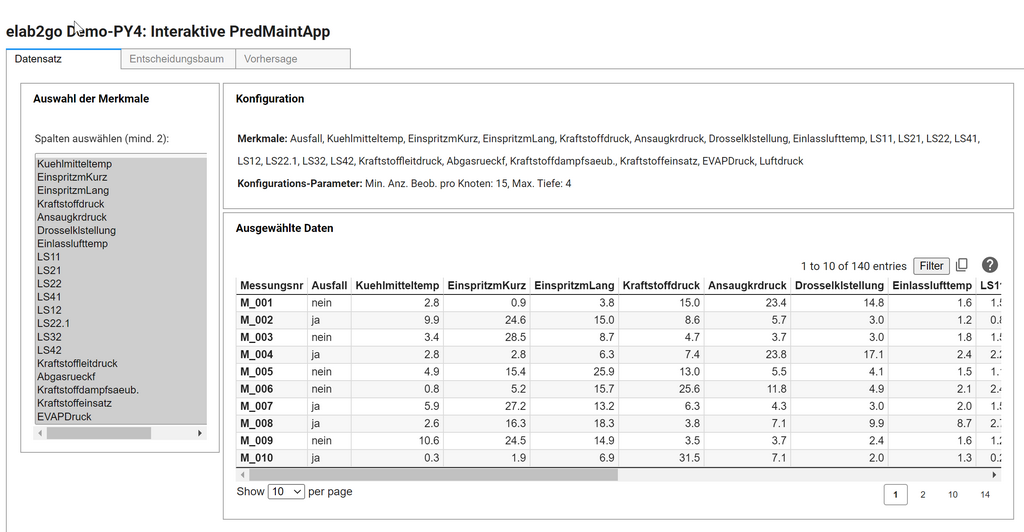
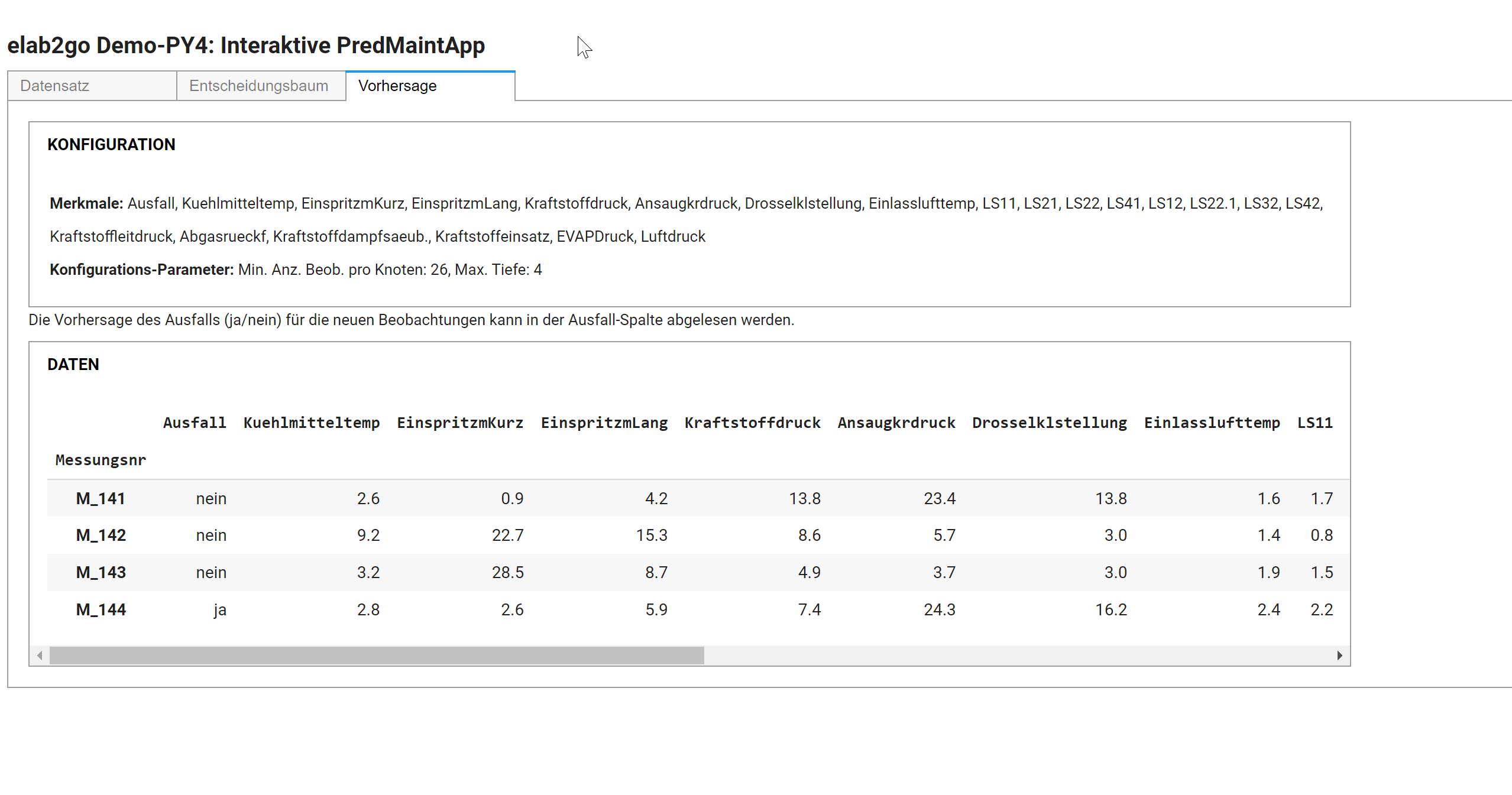
Die finale Benutzeroberfläche besteht aus drei Tabs, die den Schritten Datenvorbereitung, Modellerstellung und Vorhersage bzw. Klassifikation entsprechen. Im ersten Tab "Datensatz" können die Merkmale des Datensatzes ausgewählt werden. Im zweiten Tab "Entscheidungsbaum" können die Parameter min_samples_split, min_samples_leaf und max_depth des Entscheidungsbaums eingestellt werden, dabei wird interaktiv der daraus resultierende Entscheidungsbaum und die daraus errechneten Performance-Kennzahlen angezeigt.
Nächste Schritte
Das einmal erstellte Entscheidungsbaum-Modell kann gespeichert und für die Vorhersage von Ausfällen genutzt werden.
Die Performance-Metriken von ca. 80% können durch verschiedene Maßnahmen verbessert werden.
Datenbasis erweitern
Ein Datensatz mit vielen Beobachtungen wird bessere Klassifikationsergebnisse liefern.
Auswahl relevanter Merkmale: "Feature Selection"
Der vorliegende Datensatz enthält eine große Anzahl von Merkmalen, bei denen die erste statistische Analyse
schon eine fehlende Korrelation mit dem Ausfall gezeigt hat.
Ein Datensatz mit wenigen relevanten Merkmalen wird bessere Klassifikationsergebnisse liefern.
Datensatz balancieren
Ein balancierter Datensatz mit einem ausgewogenen Anteil an Klassen (Ausfall=nein vs. Ausfall=ja) wird bessere Klassifikationsergebnisse liefern.
Ausfälle treten in der Praxis zwar seltener auf, können jedoch durch Duplizierung statistisch ähnlicher Beobachtungen synthetisch hinzugefügt werden.
Parameter des DecisionTreeClassificators optimieren
Mit der Scikit-Learn-Funktion GridSearchCV steht ein Verfahren zur Verfügung, um aus einer Menge von Parametern die besten herauszufinden.
Optimierte Klassifikationsverfahren verwenden
RandomForest und XGBoost ((eXtreme Gradient Boosting)) sind zwei Algorithmen, die Entscheidungsbäume als Baustein verwenden und stabilere
Klassifikationsergebnisse liefern.
Autoren, Tools und Quellen
Autoren
Prof. Dr. Eva Maria Kiss
Tools:
Python,
Anaconda,
Jupyter Notebook,
Visual Studio Code
Scikit-Learn,
Pandas,
Matplotlib,
NumPy
Quellen und weiterführende Links
- [1] Python Bibliotheken: elab2go/demo-py1/python-bibliotheken.php
- [2] Erste Schritte mit Jupyter Notebook: elab2go/demo-py1/jupyter-notebooks.php
- [3] Jupyter Notebook Widgets verwenden: elab2go/demo-py1/jupyter-notebook-widgets
- [4] Jupyter Widgets Webseite: https://ipywidgets.readthedocs.io/
- [5] Python Dokumentation bei python.org: https://docs.python.org/3/tutorial/ - umfangreich, hier findet man Dokumentationen für alle Python-Versionen