Demo 3: Predictive Maintenance mit R
Demo 3: Predictive Maintenance mit R zeigt, wie eine Ausfall-Prognose im Rahmen eines Predictive Maintenance-Szenarios mit Hilfe des Entscheidungsbaum-Verfahrens in der statistischen Programmiersprache R mit der Entwicklungsumgebung RStudio durchgeführt wird. Die zu beantwortende Fragestellung aus dem Predictive Maintenance-Prozess lautet: "Bei welcher Kombination von Merkmalen tritt ein Ausfall ein?". Zur Beantwortung dieser Frage wird der Datensatz in RStudio eingelesen, mit Hilfe des Trainingsdatensatzes wird ein Entscheidungsbaum-Modell erstellt, das dann anhand von Performance-Kennzahlen validiert und zur Klassifikation bzw. der Vorhersage eines Ausfalls im Testdatensatz verwendet werden kann.
Motivation
Was steckt hinter dem Begriff der Predictive Maintenance und wie wird sie durchgeführt?
Vorausschauenden Wartung ist ein datengesteuerter Wartungsprozess, der die herkömmliche Wartung im Industrie 4.0-Umfeld
ergänzt und zunehmend ersetzt. Die Predictive Maintenance hat sich zudem als industrielle Anwendung des Machine Learning etabliert
und ist ein greifbares Beispiel des Internet of Things.
In dieser Demo werden die im Übersicht-Artikel
"Was ist Predictive Maintenance?" beschriebenen Schritte
der Predictive Maintenance in der statistischen Programmiersprache R umgesetzt,
mit Fokus auf der Datenanalyse, von der Datenvorbereitung
bis zur Anwendung des Modells zur Vorhersage für neue Beobachtungen.
Warum R?
R ist eine freie Programmiersprache für statistische Berechnungen und Grafiken, die 1992 von den Statistikern Ross Ihaka und Robert Gentleman an der Universität Auckland entwickelt wurde.
R wird als Standardsprache für statistische Probleme in Lehre, Wissenschaft und Wirtschaft verwendet. Kostenlose R-Pakete erweitern den Anwendungsbereich von R um viele Fachbereiche. Eine ausführliche Dokumentation und viele Foren, die sich der Verwendung von R widmen, ermöglichen ein einfaches Erfassen und Verwenden der Funktionalität.
Der Fokus von R liegt auf Statistik und Datenanalyse, im Unterschied zu Python, was eine Programmiersprache für den allgemeinen Einsatz ist, oder MATLAB, das allgemeiner auf numerische Verfahren und Simulation ausgerichtet ist. Während R nicht auf Performance- oder Echtzeitszenarien ausgerichtet ist, eignet es sich hervorragend für Statistiken und Datenvisualisierung.
Übersicht
Demo 3 ist in sechs Abschnitte gegliedert. Zunächst wird der Automotive-Datensatz beschrieben
und die Fragestellung erläutert, gefolgt von der Beschreibung des Ablaufs und der Entwicklungsumgebung RStudio.
Danach werden die Schritte des Datenanalyse-Prozesse im Detail beschrieben: Vorbereitung des Datensatzes,
Definition des zu verwendenden Modells, Einlesen und Anpassen der Daten, Modellbildung,
Performance-Evaluation und Vorhersage für neue Beobachtungen (vgl. Abbildung).
Die Ergebnisse werden im letzten Abschnitt mit dem Modell aus
Demo 2 verglichen.
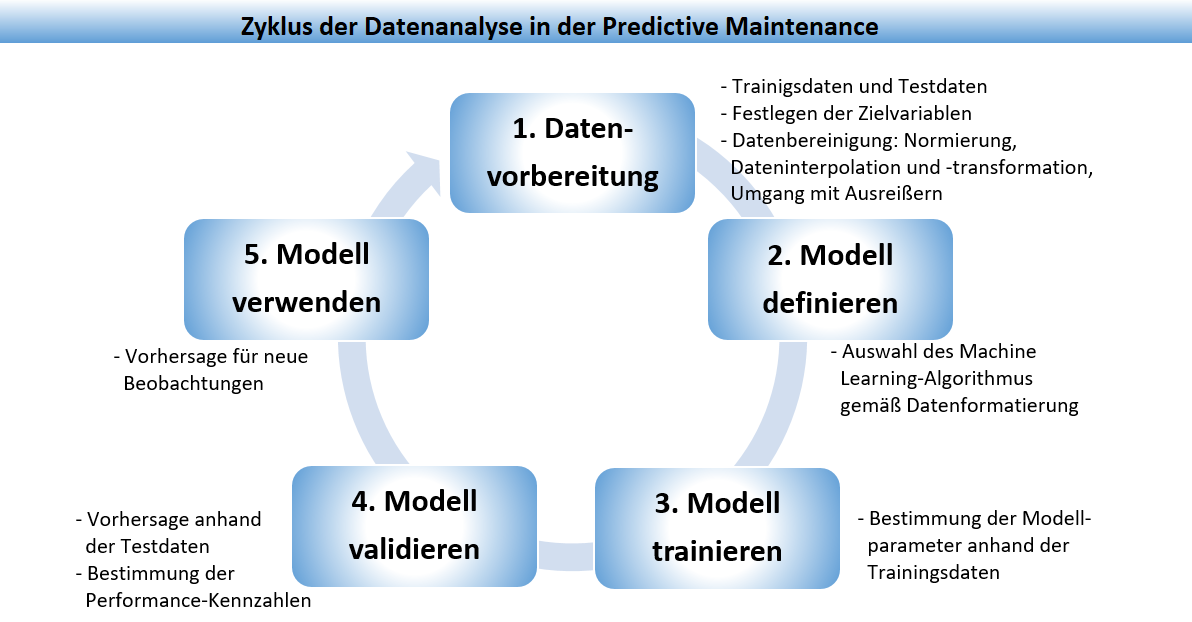
6 Der Datenanalyse-Prozess in RStudio
6-1 Datenvorbereitung
6-2 Modell erstellen
6-3 Modell validieren
6-4 Modell verwenden
Ein YouTube-Video veranschaulicht den Quellcode zur Demo und dessen Ausführung in der Entwicklungsumgebung RStudio.
1 Der Automotive-Datensatz
Der Automotive-Datensatz ist eine Excel- bzw. csv-Datei und besteht aus insgesamt 140 Beobachtungen von Motoren. Als Trennzeichen für die Spalten wird in der csv-Datei das Semikolon verwendet.
Jede Beobachtung enthält den Vorhersagewert Ausfall, mit angenommenen Werten ja/nein, die Messungsnummer und Sensorwerte zu insgesamt 22 Merkmalen. Die erhobenen Merkmalswerte stammen aus Temperatur- und Druckmessungen sowie Mengenangaben zum Kraftstoff und zu Abgasdämpfen, die an verschiedenen Stellen im Motor erfasst wurden. Weiterhin enthält der Datensatz acht Merkmale zu den Lambdasonden (LS), die an jeweils einem Zylinder im Motor Messwerte liefern und in 2 Bänke unterteilt sind (d.h. das Merkmal LS32 gibt den Sensorwert vom dritten Zylinder innerhalb der zweiten Bank an). Bis auf die Katalysatortemperatur (Merkmalsname: KatTemp, Werte: normal/hoch) liegen für alle Merkmale numerische Messungen vor.
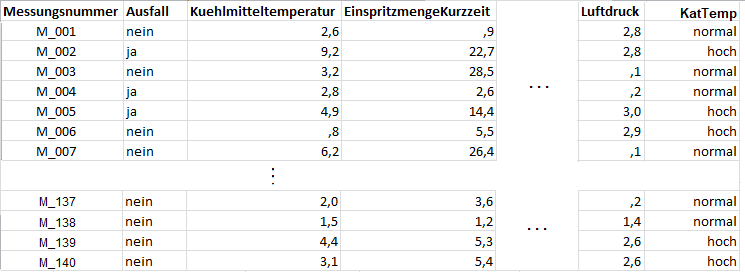
2 Die Fragestellung
Uns interessiert, welche Merkmalskombinationen, d.h. welches Zusammenspiel der Sensorwerte, zu einem Ausfall des Motors führen. Die Frage, die der Entscheidungsbaum beantworten soll, lautet also: Welche Kombination von Merkmalen wird zu einem Ausfall führen? Werden alle Merkmale einen Einfluss auf den Ausfall haben und falls nein, mit welchem Gewicht werden welche Merkmale einen Ausfall bewirken?
3 Ablauf der Datenanalyse
Die Datenanalyse für die Predictive Maintenance läuft in fünf Schritten ab:
- Schritt 1. Datenvorbereitung: Der Datensatz wird in Trainings- und Testdaten zerlegt, die Zielvariable wird festgelegt und die Daten
werden bereinigt, d.h. je nach Datenlage normiert und transformiert, bei fehlenden Werte interpoliert und durch Algorithmen werden
Ausreißer erkannt und behandelt.
- Schritt 2. Modell definieren: Gemäß den Daten wird ein passendes Modell gewählt, dies kann ein Entscheidungsbaum-Modell für
Klassifikation oder Regression sein, oder eine Nächste Nachbarn-Klassifikation, dies hängt von der Fragestellung ab.
- Schritt 3. Modell trainieren: Mit den Trainingsdaten wird das Modell erstellt, d.h die Parameter des Modells geschätzt, z.B. die Verzweigungen und Blätter eines Entscheidungsbaums oder die Parameter als Kleinste-Quadrate-Schätzer in einem Regressionsmodell.
- Schritt 4. Modell validieren: Das Modell wird auf die Testdaten angewandt um eine Vorhersage zu erhalten, der Vergleich
der Vorhersagen mit den bekannten Werten der Zielvariablen liefert die
Performance-Kennzahlen, die den Testfehler beschreiben, und angeben wie gut ein
Modell ist.
- Schritt 5. Modell verwenden: Liegt ein gutes Modell vor, dann werden durch Anwendung des Modells auf neue Beobachtungen, deren Werte der Zielvariablen unbekannt sind, Vorhersagen getätigt.
4 Die Definition des Modells
Gemäß des Schrittes 2 des Zyklus der Datenanalyse in der Predictive Maintenance wählen wir ein den Daten entsprechendes Modell, die
Formatierung der Daten und die Festlegung der Zielvariablen hängt von der Fragestellung ab. In dieser Demo wurde gemäß der Fragestellung
das Merkmal AUSFALL als Zielvariable festgelegt, d.h. das Modell soll eine Klassifikation der Daten in AUSFALL Ja oder Nein
durchführen.
Der Entscheidungsbaum ist ein intuitiv nutzbares Klassifikationsmodell, das für den Einstieg besonders geeignet ist,
da es eine Visualisierung der Klassifikation bzw. der hierarchisch aufeinanderfolgenden Entscheidungen ermöglicht.
Ein Entscheidungsbaum besteht aus einer Wurzel, Kindknoten und Blättern, wobei jeder Knoten eine Entscheidungsregel
und jedes Blatt eine Antwort auf die Fragestellung darstellt. Um eine Klassifikation eines einzelnen Datenobjektes abzulesen,
geht man vom Wurzelknoten entlang des Baumes abwärts. Bei jedem Knoten wird ein Merkmal abgefragt und eine Entscheidung über
die Auswahl des folgenden Knoten getroffen. Dies wird so lange fortgesetzt, bis man ein Blatt erreicht. Das Blatt entspricht
der Klassifikation.
Mehr Details und ein Mini-Beispiel zum Entscheidungsbaum-Modell sind unter
Predictive Maintenance: Die Datenanalyse zu finden.
5 Die RStudio-Entwicklungsumgebung
Als Datenanalyse-Tool wird RStudio eingesetzt,
eine Entwicklungsumgebung und grafische Benutzeroberfläche
für Datenanalyse mit Hilfe der statistischen Programmiersprache R, die in Open-Source- und kommerziellen Editionen erhältlich
ist und auf dem Desktop (Windows, Mac und Linux) oder in einem Browser läuft.
Die zur Datenanalyse benötigten Algorithmen sind in Pakete zusammengefasst, die nach Bedarf über die R-Konsole geladen werden können.
Die Installation und Verwendung von RStudio sowie die ersten Schritte in der Programmiersprache R werden
in Demo-R1: R-Tutorial des elab2go
beschrieben, ebenso die Erstellung von Skripten und grundlegende R-Syntax: die Verwendung von Kommentaren,
wie R-Code mit Hilfe spezieller Kommentare in Abschnitte gegliedert wird, wie externe Daten mit Hilfe der
Funktionen read_csv und read_csv2 in DataFrames importiert werden etc.
6 Der Datenanalyse-Prozess in RStudio
Im Folgenden werden die Schritte des Datenanalyse-Prozesses – Datenvorbereitung, Modellerstellung, Validierung und Vorhersage / Klassifikation – in der Programmiersprache R und mit der Entwicklungsumgebung RStudio umgesetzt.
Vorbereitung: Projekt erstellen
Zunächst wird in RStudio mit File > New Project ein neues Projekt "Demo3" angelegt, das alle Skripte und Daten zu Demo3 enthalten wird.
 Beim Anlegen des neuen Projektes erstellt RStudio den Ordner C:\R\Demo3, der als Arbeitsverzeichnis für die neue Demo genutzt wird.
Das Arbeiten mit Projekten in RStudio hat verschiedene Vorteile, z.B. können Projekt-Templates (Directory, R Package, Shiny Web Applications)
verwendet werden, auch die Versionskontrolle und damit kollaboratives Arbeiten wird über Projekte unterstützt.
Weiterhin wird durch das Anlegen eines Projektes das Arbeitsverzeichnis automatisch auf das aktive Projekt gesetzt und
der Pfad zum Arbeitsverzeichnis muss nicht explizit im Skript mit setwd gesetzt werden.
Beim Anlegen des neuen Projektes erstellt RStudio den Ordner C:\R\Demo3, der als Arbeitsverzeichnis für die neue Demo genutzt wird.
Das Arbeiten mit Projekten in RStudio hat verschiedene Vorteile, z.B. können Projekt-Templates (Directory, R Package, Shiny Web Applications)
verwendet werden, auch die Versionskontrolle und damit kollaboratives Arbeiten wird über Projekte unterstützt.
Weiterhin wird durch das Anlegen eines Projektes das Arbeitsverzeichnis automatisch auf das aktive Projekt gesetzt und
der Pfad zum Arbeitsverzeichnis muss nicht explizit im Skript mit setwd gesetzt werden.
Vorbereitung: R-Skript erstellen
Als Nächstes wird mit File > New File > R Script ein neues R-Skript demo3.R erstellt, das den R-Code enthalten wird. Wir gliedern das R-Skript demo3.R in vier Abschnitte, die den Schritten des überwachten Lernens entsprechen, dies macht den Code übersichtlicher. Zur Erinnerung: ein Abschnitt kann in RStudio mit Code > Insert Section eingefügt werden, oder auch einfach, indem man einen benannten Kommentar einfügt, der von mindestens 4 Symbolen desselben Typs gefolgt wird, und erzeugt ein einklappbares und separat ausführbares Code-Fragment. Der R-Code für die einzelnen Schritte wird in den folgenden Abschnitten beschrieben und kann an den mit TODO gekennzeichneten Stellen eingefügt werden.
# 0 Benötigte Pakete importieren ---- # TODO: laden Sie hier benötigte Pakete # Verwendete Funktionen: library # 1 Datenvorbereitung ---- # TODO: fügen Sie hier den Code zur Datenvorbereitung ein # Verwendete Funktionen: read_csv # 2 Modell erstellen ---- # TODO: fügen Sie hier den Code zur Erstellung des Modells ein # Verwendete Funktionen: rpart, rpart.plot # 3 Modell validieren ---- # TODO: fügen Sie hier den Code zur Validierung des Modells ein # Dieser Schritt wird in demo3_R_teil2.R durchgeführt # 4 Modell verwenden ---- # TODO: fügen Sie hier den Code zur Klassifikation ein # Verwendete Funktionen: predict
Die Struktur des Demo3-Projektes sieht nach Erstellen der Skripte und Ablegen der csv-Dateien mit den Datensätzen wie abgebildet aus.

Pakete importieren
Der nächste vorbereitende Schritt besteht darin, benötigte Pakete zu installieren und in das Skript zu laden. In R gibt es verschiedene Pakete, die das Training und die Visualisierung von Entscheidungsbäumen unterstützen: tree, party, rpart. Das aktuell am häufigsten verwendete Paket ist rpart, dies ermöglicht eine besonders ansprechende Visualisierung des Entscheidungsbaums und wird daher in dieser Demo verwendet. Der R-Code zum Laden der benötigten Pakete ist wie folgt, damit werden die benötigten Pakete geladen. Das "rpart"-Paket enthält Funktionen, die zur Erstellung des Klassifikationsmodells gebraucht werden, insbesondere die gleichnamige Funktion rpart, die den Entscheidungsbaum auf Basis des CART-Algorithmus mittels des Informationgehalt-Kriteriums erstellt. Das Paket "rpart.plot" enthält Funktionen zur grafischen Darstellung des Entscheidungsbaumes.
R-Code: Pakete laden
#Demo 3: Predictive Maintenance mit R# 0 Benötigte Pakete importieren ----library(rpart)library(rpart.plot)
6-1 Datenvorbereitung
Im Schritt "Datenvorbereitung" der Datenanalyse werden die Daten aus externen Quellen (csv-Dateien, Datenbanken) in RStudio eingelesen, dabei wird festgelegt, welche Spalten genau eingelesen werden, und in welchem Format dies geschehen soll. In unserem Fall liegen die Daten als csv-Datei automotive_data_140.csv vor, die erste Spalte enthält die Spaltenüberschriften, als Trennzeichen wird das Semikolon verwendet, als Dezimaltrenner der Punkt. Da wir für die Modellerstellung die erste und 25te Spalte des Datensatzes nicht benötigen, werden diese nach dem Einlesen aus dem DataFrame entfernt.
R-Code: Datenvorbereitung
# 1 Datenvorbereitung ----# Setze den Arbeitspfadsetwd("C:/R/Demo3")# CSV-Datei einlesen und speicherndemo3=read.csv2("automotive_data_140.csv",header = TRUE,sep = ";",dec = ".")# Wähle Merkmale ausdemo3training=demo3[ ,c(-1,-25)]# Überprüfe die Struktur von demo3trainingstr(demo3training)
Erläuterung des R-Codes
In Zeile 3 wird der Arbeitspfad gesetzt, falls man zuvor den Projektordner als Projekt erstellt hat, ist dieser Schritt optional.
In den Zeilen 6-7 des Codes wird die CSV-Datei mit der "read.csv2"-Funktion eingelesen und
mit der Zuweisung ("="-Zeichen) als DataFrame-Objekt demo3 gespeichert.
Aus diesem Objekt, das die Daten des Automobildatensatzes enthält,
werden nun die erste Spalte (die Messungsnummer) und 25. Spalte (Katalysatortemp, numerischer Wert) entfernt
und die gekürzten Daten unter dem Namen "demo3training" gespeichert.
Wir überprüfen noch die Struktur des DataFrame-Objektes demo3training mit Hilfe der str-Funktion,
dies zeigt uns, ob die Spalten korrekt und mit den korrekten Datentypen importiert wurden.
Die "demo3training"-Daten werden im Folgenden zur Erstellung des Entscheidungsbaums verwendet.
Verwendete Funktionen
Die library-Funktion lädt Pakete in der aktuelle R-Sitzung.
Die library-Funktion ist eine Funktion, die Pakete in die aktuelle R-Sitzung lädt und somit deren Funktionen zur Verfügung stellt. Wird hier verwendet um das rpart-Paket zu laden, dieses enthält Funktionen, die zur Erstellung und grafischen Darstellung von Klassifikationsmodellen verwendet werden.
Die setwd-Funktion setzt den Arbeitspfad für die aktuelle R-Sitzung.
Die setwd-Funktion ist eine Funktion, die den Arbeitspfad der aktuellen R-Sitzung festlegt, damit entfällt die Angabe des Pfades beim Speichern oder Laden von Workspaces und Daten.
Die read.csv2-Funktion liest Daten im csv-Format ein.
Die read.csv2-Funktion ist eine Funktion, die Daten im csv-Format anhand von Parametern einliest.
Die read.csv2-Funktion wird in unserem Prozess zweimal verwendet: einmal,
um den Trainingsdatensatz einzubinden, und einmal, um den Testdatensatz einzubinden.
Ausgabe
Der Quellcode liefert bei Ausführung folgenden Trainingsdatensatz:

Im aktuellen Arbeitsverzeichnis liegen nun die beiden Datensätze demo3 und demo3training vor:

6-2 Modell erstellen
Im Schritt "Modell erstellen" des überwachten Lernens wird ein zuvor festgelegtes Modell trainiert (hier: ein Entscheidungsbaum-Modell), indem die Modellparameter mit Hilfe eines passenden Algorithmus an die Trainingsdaten angepasst werden.
Die Erstellung eines Entscheidungsbaum-Modells in R erfolgt mit Hilfe der rpart-Funktion des gleichnamigen Pakets. Die allgemeine Syntax der Funktion ist rpart(formula, data, method, parms, control,…). Über die Parameter der Funktion wird festgelegt, wie genau der Entscheidungsbaum aufgebaut wird:
- formula: ist eine Modellformel in der Form Zielvariable ~ Merkmal1 + Merkmal2 oder Zielvariable ~ ., falls alle Merkmale verwendet werden.
- data: das DataFrame-Objekt mit den Trainingsdaten
- method: ist die Art des Modells (class bedeutet Klassifikationsmodell, anova Regressionsmodell)
- parms: Mit dem Parameter parms kann das Kriterium eingestellt werden, das für die Aufteilung der Knoten herangezogen wird, mögliche Optionen sind "information" oder "gini".
- control: Mit dem Parameter control kann eine Liste von Optionen übergeben werden, die das Wachstum des Baums steuern, z.B. minsplit, maxdepth, cp.
Wir erstellen den Baum mittels des Entropie/Informationgehalt-Kriteriums (split="information") basierend auf den Trainingsdatensatz der Motoren. Die hier übergebene Modellformel lautet "Ausfall ~ .", links vom Tilde-Zeichen steht die Variable, die vorhergesagt werden soll und rechts vom Tilde-Zeichen die Merkmale, die zur Modellbildung verwendet werden sollen, hier steht der Punkt "~." für die Verwendung aller Merkmale des Datensatzes.
R-Code: Modell erstellen
# 2 Modell erstellen ----# Erstelle Entscheidungsbaum mit dem CART-Algorithmusfit = rpart(Ausfall ~ .,data=demo3training,method="class",parms=list(split="information"),control=list(minsplit=15))# Baum in Textformprint(fit)# Baum visualisierenrpart.plot(fit, type = 1, extra = 1,uniform = TRUE, main = "Entscheidungsbaum")
Erläuterung des R-Codes
In den Zeilen 3-7 des Codes wird der Entscheidungsbaum mit den Trainingsdaten "demo3training" erstellt, indem die "rpart"-Funktion mit den entsprechenden Parametern aufgerufen wird. Das Modell wird unter dem Namen "fit" gespeichert, mit der print-Funktion in Textform und mit der rpart.plot-Funktion als Grafik ausgegeben.
Verwendete Funktionen
Die rpart-Funktion erstellt den Entscheidungsbaum.
Die rpart-Funktion ist eine Funktion aus dem rpart-Paket, mit deren Hilfe Entscheidungsbäume für Klassifikation und Regression erstellt werden können, wobei die genaue Art der Erstellung durch die Argumente der Funktion festgelegt wird. Die vollständige Syntax der Funktion lautet
fit = rpart(formula, data, weights, subset, na.action = na.rpart, method,
model = FALSE, x = FALSE, y = TRUE, parms, control, cost, …)
Bis auf die Parameter formula und data sind alle Parameter optional, d.h. fit = rpart(Ausfall ~ ., demo3training)
ist ein gültiger Funktionsaufruf und erstellt ein Entscheidungsbaum-Modell fit mit Default-Einstellungen.
Die Ausgabe-Funktionen für das Modell: print und rpart.plot
Die print-Funktion ist eine Funktion, die das Modell/den Baum in Textform im Output-Fenster ausgibt.
Die rpart.plot-Funktion ist eine Funktion aus dem rpart-Paket, die die Äste, Knoten und Blätter des Baums im Grafikfenster ausgibt.
Die Beschriftung
mit den Merkmalen, den Bedingungen und den Werten der Vorhersagevariablen erfolgt automtisch. Beiden Funktionen
können Parameter übergeben werden, die minimale Übergabe besteht aus dem Entscheidungsbaum, hier "fit".
Der Entscheidungsbaum
Der Entscheidungsbaum wählt nur einen Teil der 22 Merkmale zur Vorhersage eines Ausfalls aus. Die Merkmale werden hierarchisch als Baum oder Text dargestellt.
An jedem Knoten wird für das jeweilige Merkmal eine Bedingung abgefragt und je nach Beobachtungswert wird nach links (Bedingung erfüllt) oder rechts (Bedingung NICHT erfüllt) zum weiteren Knoten verwiesen. Dort erfolgt eine erneute Bedingung für ein Merkmal mit weiteren Verweis auf den nächsten Knoten. Dies wird solange durchgeführt bis der durchlaufene Pfad an einem Ja/Nein- Blatt des Baumes endet.
Wann kommt es zu einem Ausfall?
Wenn am Ende eines Astes "Ja" steht, dann führt der Pfad/die Merkmalskombination
zu einem Ausfall der Anlage andernfalls,
d.h. bei "Nein", kommt es bei durchlaufener Merkmalskombination zu keinem Ausfall.

Je höher des Merkmal im Baum steht, d.h. je weiter oben dessen Position ist, desto mehr Einfluss hat es auf die Vorhersage eines Ausfalls. In unserem Baum hat die Einlasslufttemperatur den höchsten Einfluss. An der Aufteilung Ja/Nein in den Blättern (z.B. 50/4 im ganzen linken Blatt) erkennt man, wie viele Beobachtungen des Trainingsdatensatzes mit beobachteten Ausfällen Ja/Nein diesem Blatt zugeordnet werden (z.B. insgesamt 54 Beobachtungen im ganzen linken Ast, bei denen 50 mal ein Ausfall vorliegt und 4 mal kein Ausfall). Daraus lassen sich die Wahrscheinlichkeiten für Ausfall Ja oder Nein je Blatt bestimmen, die auch bei der Ausgabe des Baums in Textform angeben sind.
Die oben bereits erwähnte alternative Darstellung des Entscheidungsbaum-Modells in Textform wird in der Programmiersprachen R mit dem print-Befehl standardmäßig ausgegeben.

Die Ausgabe in Textform ist auf folgende Weise zu lesen: Jeder Knoten oder jedes Blatt des Baumes erhält eine Zeilenausgabe mit folgenden Informationen:
- node) die Nummerierung des Knoten/Blattes, hierbei wird der nachfolgende Knoten des aktuellen Knotens Nr.x mit 2x und 2x+1 nummeriert. D.h. aus dem Startknoten Nr.1 enstehen die Knoten mit Nr. 2 und 3, auf Nr. 2 folgen die Knoten mit Nr. 4 und 5, auf Nr. 3 die Knoten mit Nr. 6 und 7 usw.
- split gibt die letzte Merkmalsbedingung an, die zu diesem Knoten/Blatt geführt hat.
- n gibt die Anzahl aller Beobachtungen aus den Trainingsdaten an, die die Merkmalskombinationen, die bis hierhin führen, erfüllen.
- loss gibt die falschen Zuordnungen in dem Knoten/Blatt an, dazu werden die Zuordnung gemäß des Baums/Modells in Ausfall Ja/Nein mit den tatsächlich beobachteten Zuordnung der Trainigsdaten in diesem Knoten verglichen. Wird in dem Knoten Ausfall Nein vorhergesagt, dann sind die tatsächlichen Ausfälle die losses, wird aber Ausfall Ja vorhergesagt, dann sind die nicht ausgefallenen Beobachtungen die losses.
- yval gibt den Wert der Vorhersagevariablen (hier: Ausfall Ja/Nein) gemäß des Baums/Modells in diesem Knoten an.
- (yprob) gibt die Wahrscheinlichkeiten für Ausfall Ja (linker Wert) oder Nein (rechter Wert) in diesem Knoten an, und damit ein Maß wie sicher die Zuordnung der Beobachtungen der Trainingsdaten durch das Modell erfolgt.
- * bedeutet, dass dieser Knoten ein Endknoten bzw. ein Blatt des Baumes ist und danach kein weiterer Knoten bzw. keine Merkmalsbedingung im Baum mehr erfolgt.
Optimieren des Entscheidungsbaums: Pruning
Bei der Erstellung des Entscheidungsbaums tritt die Frage nach der optimalen Tiefe des Baums auf.
Der Baum sollte mit seinen Knoten, Ästen und Blättern so viel Information wie möglich aus den Daten schöpfen,
ohne dass es zu einer Überanpassung (engl. Overfitting) kommt.
Bei einer Überanpassung, d.h. einer zu exakten Anpassung des Modells an die Trainingsdaten,
ist keine gute Vorhersage für neue Beobachtungen mehr möglich,
bei einem zu "kleinen" Baum könnten entscheidende Informationen der Trainingsdaten nicht erfasst werden.
Das Pruning (Kürzen und Optimieren) des Baums liefert eine Antwort auf diese Frage.
Man unterscheidet zwei Arten des Prunings, Pre- und Post-Pruning, wir verwenden hier nur das Post-Pruning,
welches in dem zuvor erstellten Entscheidungsbaum ganze Teilbäume abschneidet, indem es sie durch Blätter ersetzt.
Beim Pruning wird mit Hilfe der Kreuzvalidierung für alle möglichen Kürzungen des Baums eine statistische Kennzahl,
der Komplexitätsparameter oder CP-Wert, und deren Toleranzbereiche ermittelt.
Anhand dieser Kennzahl und der Fehler, die durch die Kreuzvalidierung ermittelt wurde, kann die optimale Kürzung
des Baums ermittelt werden. Der CP-Wert bestimmt, wie stark das Splitting der Knoten den relativen Fehler verbessert.
Ein kleiner CP-Wert führt zu größeren Bäumen und ggf. zu Überanpassung, ein großer CP-Wert zu kleineren Bäumen und
möglicherweise Unteranpassung.
Umsetzung des Prunings im rpart-Paket
In R stehen im Paket rpart drei Funktionen zum Pruning zur Verfügung: printcp, plotcp und prune.
Mit dem R-Code
# 4 Pruning ----printcp(fit)plotcp(fit, upper="size")tree_pruned=prune(fit,cp=0.033)rpart.plot(tree_pruned)
wird das Kürzen des trainierten Entscheidungsbaums durchgeführt.
Erläuterungen zum Code
- An die printcp-Funktion des rpart-Paketes wird das rpart-Objekt, hier: der Baum mit dem Namen fit, übergeben, und diese gibt die mittels der Kreuzvalidierung simulierte Kennzahl CP, deren Toleranzbereiche und die simulierten Fehler in einer Tabelle aus.
- Im nächsten Schritt stellt die plotcp-Funktion des rpart-Paketes die Werte der CP-Tabelle grafisch dar. Der Parameter upper steuert, was als obere zusätzliche Achsenbeschriftung angegeben wird: "size" - die Tiefe des Baums, "splits" - die Anzahl der Verzweigungen, "none" - keine zusätzliche Achsenbeschriftung. Aus der Grafik wählt man als guten CP-Wert (Empfehlung in der R-Hilfe), den Wert der ganz links die horizontale Linie als erstes übersteigt. In unserem Modell liegt der CP-Wert bei 0.033.
- Der mit plotcp ermittelte Wert wird mit dem trainierten Baum an die Funktion prune des rpart-Paketes übergeben. Die Funktion kürzt den Baum auf die dem übergebenen CP-Wert entsprechende Tiefe, hier: fünf. Mit der rpart.plot-Funktion wird der gekürzte Baum grafisch dargestellt.
Die Ausgabe der Grafik und des durch Pruning gekürzten Baumes sieht wie folgt aus:
CP-Tabelle

Grafische Darstellung

Optimierter Entscheidungsbaum

Verwendete Funktionen
Die printcp-Funktion simuliert den CP-Wert und dessen Fehler.
An die printcp-Funktion des rpart-Paketes wird das rpart-Objekt, hier: der Baum, übergeben und diese gibt die mittels der Kreuzvalidierung simulierte Kennzahl CP, deren Toleranzbereiche und die simulierten Fehler in einer Tabelle aus.
Die plotcp-Funktion stellt die Werte der CP-Tabelle grafisch dar.
Die plotcp-Funktion des rpart-Paketes stellt die Werte der CP-Tabelle, siehe auch printcp-Funktion, grafisch dar und je nach Parameter upper = c("size", "splits", "none") wird entweder die Tiefe des Baums, die Anzahl der Verzweigungen oder garnichts als obere zusätzliche Achsenbeschriftung angegeben. Aus der Grafik wählt man als "guten" CP-Wert (Empfehlung in der R-Hilfe), den Wert der ganz links (von rechts gesehen) die horizontale Linie als erstes übersteigt, hier: CP-Wert bei 0.033.
Die prune-Funktion kürzt den Baum entsprechendd des CP-Wertes.
An die prune-Funktion des rpart-Paketes wird das rpart-Objekt, hier: der trainierte Baum, und ein Wert für die Kennzahl CP übergeben. Die Funktion kürzt den Baum um die dem CP-Wert entsprechende Tiefe, siehe CP-Tabelle der printcp-Funktion.
6-3 Modell validieren
Im Schritt "Modell validieren" des überwachten Lernens werden für Testdaten (d.h. der Wert für die Zielvariable ist bekannt) mittels des zuvor trainierten Modells (hier: ein Entscheidungsbaum-Modell) Vorhersagen getätigt, die dann zur Bestimmung der Performance-Kennzahlen mit den bekannten Werten der Zielvariablen (hier: Ausfall) verglichen werden. Zur Bestimmung der Kennzahlen verwenden wir das Verfahren der Kreuzvalidierung, deren Durchführung im R-Skript demo3_R_teil2.R umgesetzt ist.
Uns interessiert dabei, wie sicher das Vorhersagemodell den Ausfall eines Motors vorhersagt. Anhand der
Kennzahlen zum Testfehler
lässt sich dies beantworten:
Liegen die Kennzahlen in einem vorher festgelegten, akzeptablen Bereich? Wenn ja, dann ist das Modell gut, d.h. wir können uns
auf die Aussagen und Vorhersagen durch das Modell verlassen.
Der R-Code für die einzelnen Schritte zur Durchführung der Kreuzvalidierung und der Bestimmung der Kennzahlen wird in den folgenden Abschnitten beschrieben und kann an den mit TODO gekennzeichneten Stellen eingefügt werden.
# 0 Benötigte Pakete und Funktionen importieren ---- # TODO: laden Sie hier benötigte Pakete # und Funktionen # Verwendete Funktionen: library, source # 1 Datenvorbereitung ---- # TODO: fügen Sie hier den Code zur # Datenvorbereitung ein # Verwendete Funktionen: read_csv # 2 Kreuzvalidierung(CV) ---- # 2.1 Vorbereitung ---- # TODO: fügen Sie hier den Code zur Erstellung # der Teildatensätze, der benötigten # Eingabe-Parameter und der Ausgabe-Objekte ein # Verwendete Funktionen: createCVFolds # 2.2 Durchführung ---- # TODO: fügen Sie hier den Code zur # Durchführung der CV ein # verwendete Funktionen: rpart, predict, colSums, # confusionMatrix, performance
Pakete und Funktionen importieren
Der vorbereitende Schritt besteht darin, benötigte Pakete zu installieren und in das Skript zu laden, auch externer R-Code, hier: eine Funktion, der sich in einer R-Datei im Arbeitspfad befindet, wird geladen. Neben dem "rpart"-Paket noch das "caret"-Paket und das "ROCR"-Paket mit der library-Funktion geladen, diese enthalten Funktionen, die die Bestimmung der Kennzahlen durchführen. Die source-Funktion fügt hier den R-Code aus einer externen R-Datei namens CreateSamples.R in den aktuellen R-Code ein.
R-Code: Pakete und Funktionen laden
#Demo 3: Performance-Kennzahlen#Lade benötigte Paketelibrary(rpart)library(caret)library(ROCR)#Lade externe Funktionsource("CreateSamples.r")
Verwendete Funktionen
Die source-Funktion fügt R-Code in die aktuelle Umgebung ein.
Die source-Funktion ist eine Funktion aus dem base-Paket, mit deren Hilfe R-Code aus einer R-Datei, einer URL, einer Verbindung oder einen direkten Ausdruck in die R-Umgebung eingefügt wird. Ein oft angewandter Aufruf der Funktion lautet
source(file, local = FALSE, echo = TRUE)Bis auf die Parameter file sind alle Parameter optional, d.h. source(file) ist ein gültiger Funktionsaufruf und fügt externen R-Code aus dem angegebenen Pfad oder der URL mit Default-Einstellungen ein. Der Parameter echo=TRUE bewirkt eine verkürzte Ausgabe des eingefügten R-Codes in der Konsole, dies kann zur Kontrolle nützlich sein.
Die library-Funktion lädt Pakete in der aktuelle R-Sitzung.
Die library-Funktion ist eine Funktion, die Pakete in die aktuelle R-Sitzung lädt und somit deren Funktionen zur Verfügung stellt. Wird hier verwendet um das rpart-Paket zu laden, dieses enthält Funktionen, die zur Erstellung und grafischen Darstellung von Klassifikationsmodellen verwendet werden.
1 Datenvorbereitung
Im Schritt "Datenvorbereitung" zur Modellvalidierung werden die Daten aus externen Quellen (csv-Dateien, Datenbanken) in RStudio eingelesen, dabei wird festgelegt, welche Spalten genau eingelesen werden, und in welchem Format dies geschehen soll. In unserem Fall liegen die Daten als csv-Datei automotive_data_140.csv vor, die erste Spalte enthält die Spaltenüberschriften, als Trennzeichen wird das Semikolon verwendet, als Dezimaltrenner der Punkt. Da wir für die Validierung die erste und 25te Spalte des Datensatzes nicht benötigen, werden diese nach dem Einlesen aus dem DataFrame entfernt.
R-Code: Datenvorbereitung
# 1 Datenvorbereitung ----# Setze den Arbeitspfadsetwd("C:/R/Demo3")# CSV-Datei einlesen und speicherndemo3=read.csv2("automotive_data_140.csv",header = TRUE,sep = ";",dec = ".")# Wähle Merkmale ausdemo3training=demo3[ ,c(-1,-25)]# Überprüfe die Struktur von demo3trainingstr(demo3training)
Erläuterung des R-Codes
In Zeile 3 wird der Arbeitspfad gesetzt, falls man zuvor den Projektordner als Projekt erstellt hat,
ist dieser Schritt optional.
In den Zeilen 6-7 des Codes wird die CSV-Datei mit der "read.csv2"-Funktion eingelesen und
mit der Zuweisung ("="-Zeichen) als DataFrame-Objekt demo3 gespeichert.
Aus diesem Objekt, das die Daten des Automobildatensatzes enthält,
werden nun die erste Spalte (die Messungsnummer) und 25. Spalte (Katalysatortemp, numerischer Wert) entfernt
und die gekürzten Daten unter dem Namen "demo3training" gespeichert.
Wir überprüfen noch die Struktur des DataFrame-Objektes demo3training mit Hilfe der str-Funktion,
dies zeigt uns, ob die Spalten korrekt und mit den korrekten Datentypen importiert wurden.
Die "demo3training"-Daten werden im Folgenden zur Bestimmung der PerformanceKennzahlen verwendet.
Verwendete Funktionen
Die setwd-Funktion setzt den Arbeitspfad für die aktuelle R-Sitzung.
Die setwd-Funktion ist eine Funktion, die den Arbeitspfad der aktuellen R-Sitzung festlegt, damit entfällt die Angabe des Pfades beim Speichern oder Laden von Workspaces und Daten.
Die read.csv2-Funktion liest Daten im csv-Format ein.
Die read.csv2-Funktion ist eine Funktion, die Daten im csv-Format anhand von Parametern einliest.
Die read.csv2-Funktion wird in unserem Prozess zweimal verwendet: einmal,
um den Trainingsdatensatz einzubinden, und einmal, um den Testdatensatz einzubinden.
Ausgabe
Der Quellcode liefert bei Ausführung folgenden Trainingsdatensatz:
Im aktuellen Arbeitsverzeichnis liegen nun die beiden Datensätze demo3 und demo3training und die mit der source-Funktion
eingelesene createCVFolds-Funktion vor:

2 Kreuzvalidierung
2.1 Vorbereitung
Um die Performance-Kennzahlen mittels der Kreuzvalidierung zu bestimmen, werden vorbereitend
Teildatensätze erstellt, benötigte Eingabe-Parameter festgelegt und ein Ausgabe-Objekte (hier: eine Matrix) erstellt.
R-Code: Vorbereitung der Kreuzvalidierung
# 2 Kreuzvalidierung(CV) ----# 2.1 Vorbereitung ----# Eingabe-Variable:# Anzahl der Teildatensätze in CVK=10# Erzeuge Teildatensätze mittels# externer Funktionfolds=createCVFolds(demo3training,K,seed=2012)# Ausgabematrix der# Performance-Kennzahlenm_perf=matrix(nrow = K, ncol = 4)# Spaltennamen festlegencolnames(m_perf)=c("recall", "precision","accuracy", "auc")
Erläuterung des R-Codes
Die Matrix "m_perf" wird erzeugt (Zeile 15), die Platz für die Speicherung der Kennzahlen "recall", "precision", "accuracy" und "auc"
bereitstellt, die Spalten dieser Matrix (colnames(m_perf)) werden den Kennzahlen entsprechend benannt (Zeile 18).
In Zeile 10 wird die Funktion "createCVFolds" aus der R-Datei "CreateSamples.r"
verwendet um den Trainingsdatensatz in K=10 in etwa gleich große Teildatensätze zu zerlegen.
Die Anzahl K der Teildatensätze kann in Zeile 6 verändert werden.
Verwendete Funktionen
R-Code: createCVFolds
#externe Funktion definierencreateCVFolds= function(data,K=10, seed=444){#LeaveOneOut-Cross-Validationn=nrow(data)groesseSample=n%/%Kset.seed(seed)i=runif(n)rang=rank(i)sample=(rang-1)%/% groesseSample + 1sample =as.factor(sample)return(sample)}# Funktion-Ende
Erläuterung des R-Codes
Die Funktion createCVFolds ordnet jeder Beobachtung des übergebenen Datensatzes eine Zahl zwischen 1 und K zu, somit
erfolgt eine Einteilung der Daten in K in etwa
gleich große Teildatensätze. Der Übergabeparameter "seed" dient der Reproduzierbarkeit der Aufteilung,
da das Ziehen der Zufallszahl i somit an einem festen, seed-abhängigen
Punkt beginnt und damit nachvollziehbar wird. In der Praxis wird der Seed system-intern erstellt und liefert
keine Reproduzierbarkeit mehr, sondern Zufälligkeit.
2.2 Durchführung
In der K-fache Kreuzvalidierung wird in jedem Schleifen-Durchlauf einen Teildatensatz ausgewählt, mit den übrigen
Teildatensätzen das Vorhersagemodell/Baum erstellt und dann für ausgewählten Teildatensatz eine Vorhersage durchgeführt.
Die vorhergesagten Werte werden
dann mit den tatsächlichen Werten für die Variable Ausfall verglichen und somit die Kennzahlen bestimmt.
Dies erfolgt K mal und nachdem die Schleife durchlaufen wurde, werden alle K Werte der Kennzahlen gemittelt.
for (i in 1:K){#Erstelle Entscheidungsbaum#mit dem CART-Algorithmus#und k-1 Trainingsdatensätzenfit = rpart(Ausfall ~ .,data=demo3training[folds!=i,],method='class',parms=list(split="information"),control=list(minsplit = 15))#Vorhersage für den#ausgelassenen Teildatensatztestdata=demo3training[folds==i,]pred=predict(fit, newdata=testdata,type="class")#Erzeuge Konfusionsmatrix mit#caret-Paketm_conf=confusionMatrix(pred,testdata$Ausfall,positive="ja")#Speichere die Perf.-Kennzahlen#des i-ten Durchlaufs der CVm_perf[i,1]=m_conf$byClass[6]m_perf[i,2]=m_conf$byClass[5]m_perf[i,3]=m_conf$overall[1]#AUC, ROC#Vorhersage für die Testdatenpred.prob=predict(fit,newdata=testdata,type="prob")#beobachteter Ausfallobs=(testdata$Ausfall=="ja")#ROCR-Paket liefert AUCprediction.obj=prediction(pred.prob[,1],obs)perf.auc=performance(prediction.obj,measure = "auc")#Speichere die AUC des i-ten#Durchlaufs der CVm_perf[i,4]=as.double(perf.auc@y.values)}#for-Schleifen-Ende#Mittelung der Kennzahlenperf=colSums(m_perf)/K#Ausgabe der Kennzahlenperf
Erläuterung des R-Codes
Der Kennzahl-Code besteht aus einer for-Schleife, die bei jedem Schleifen-Durchlauf einen Teildatensatz auswählt (i.ter Datensatz, Zeile 13),
mit den übrigen i-1 Teildatensätzen (Zeile 6) das Vorhersagemodell/Baum erstellt (Zeilen 5-10) und dann für ausgewählten Teildatensatz eine Vorhersage durchführt
(Zeile 14, 15). Die vorhergesagten Werte werden
dann mit den tatsächlichen Werten für die Variable Ausfall verglichen und somit die Kennzahlen bestimmt. Dies erfolgt K mal und nachdem die Schleife
durchlaufen wurde, werden alle K Werte der Kennzahlen gemittelt (Zeile 52) und die Performance-Matrix "perf" ausgegeben (Zeile 55).
Das "caret"-Paket stellt die Funktion "confusionMatrix" (Zeile 19-21) bereit, die alle Kennzahlen bis aus die AUC bestimmt, die AUC wird mit
der "performance"-Funktion des "ROCR"-Paketes bestimmt (Zeile 41, 42).
Die Kennzahlen werden im i-ten von K Schleifen-Durchläufen in der i-ten Zeile und der der Kennzahl entsprechenden Spalte gespeichert, z.B.
die AUC in Spalte 4 von Durchlauf i: m_perf[i,4].
Verwendete Funktionen
Die confusionMatrix-Funktion stellt eine Beobachtung-Vorhersagematrix auf.
Die confusionMatrix-Funktion ist eine Funktion, der die Vorhersagen durch das Modell und die tatsächlichen Werte der Zielvariablen Ausfall übergeben werden.
Mit dem Parameter "positive" wird festgelegt für welchen Wert der Zielvariablen die Kennzahlen ermittelt werden sollen, hier Ausfall=ja, also
positive="ja". Mittels der in Schritt 4: Datenanalyse, Performance
vorgestellten Formeln werden dann die Kennzahlen
aus der Beobachtung-Vorhersagematrix bestimmt.
Im Objekt "byClass" der Funktion sind an verschiedenen Stellen die Kennzahlen zu finden, z.B. an Stelle 6 des Objektes der Recall-Wert:
m_conf$byClass[6].
Die performance-Funktion vergleicht zwei Vektoren miteinander.
Die performance-Funktion ist eine Funktion, der ein prediction-Objekt übergeben wird, dieses wird durch Aufruf der prediction-Funktion aus dem ROCR erzeugt.
Die mit dem prediction-Objekt übergebenen Wahrscheinlichkeiten für einen Ausfall (mit predict(...,type="prob") bestimmt) und der Vektor mit TRUE/FALSE-Werten entsprechend
der tatsächlichen Werten von Ausfall JA/NEIN werden zur Bestimmung des AUC-Wertes (Parameter measure = "auc") herangezogen. Der AUC-Wert kann mit as.double(perf.auc@y.values), also
durch Umformatierung des Listenwertes y.values in eine Gleitkommazahl, zur weiteren Verwendung im Programm zur Verfügung gestellt werden.
Die rpart-Funktion erstellt den Entscheidungsbaum.
Die rpart-Funktion ist eine Funktion aus dem rpart-Paket, mit deren Hilfe Entscheidungsbäume für Klassifikation und Regression erstellt werden können, wobei die genaue Art der Erstellung durch die Argumente der Funktion festgelegt wird. Die vollständige Syntax der Funktion lautet
Bis auf die Parameter formula und data sind alle Parameter optional, d.h. fit = rpart(Ausfall ~ ., demo3training) ist ein gültiger Funktionsaufruf und erstellt ein Entscheidungsbaum-Modell fit mit Default-Einstellungen.fit = rpart(formula, data, weights, subset, na.action = na.rpart, method,model = FALSE, x = FALSE, y = TRUE, parms, control, cost, …)
Die predict-Funktion erstellt eine Vorhersage.
Die predict-Funktion ist eine Funktion aus dem rpart-Paket, mit deren Hilfe ein erstelltes rpart-Objekt (object, hier: Entscheidungsbaum) zur Klassifikation für übergebene Daten (newdata) angewandt wird. Die vollständige Syntax der Funktion lautet
Bis auf die Parameter object und data sind alle Parameter optional, d.h. pred = predict(object, newdata) ist ein gültiger Funktionsaufruf und erstellt bei einem Entscheidungsbaum-Modell als Objekt default eine Matrix mit Eintritts-Wahrscheinlichkeiten.pred = predict(object, newdata,type = c("vector", "prob", "class", "matrix"),na.action = na.pass, ...)
Die predict-Funktion gibt es in vielen Paketen, die zur Schätzung von Modellparametern genutzt werden, und die Parameter der predict-Funktionen unterscheiden sich je nach Modell des Paketes voneinander. Hier wird ein Entscheidungsbaum mit dem rpart-Paket erstellt dementsprechend sind die Rückgabetypen ("vector", "prob", "class", "matrix") definiert. Mit type="prob" (probability, deutsch: Wahrscheinlichkeit) wird die Wahrscheinlichkeit für die Einteilung in die jeweilige Klasse (Ausfall: JA/NEIN) vorhergesagt. Mit dem Parameter type="class" wird für neue Beobachtungen bzw. die Zeilen im Testdatensatz eine Klassifikation in Ausfall Ja oder Nein anhand des Entscheidungsbaums durchgeführt. Es erfolgt also in beiden Fällen eine Vorhersage für neue Messwertkombinationen.
Die colSums-Funktion summiert über Spalten.
Die colSums-Funktion ist eine Funktion, die über die Spalten eines nummerischen Arrays (hier: einer Matrix) oder eines DataFrames summiert, dabei müssen die Spalten-Werte vom Typ numerisch, logisch, komplex oder Integer sein.
Das aktuelle Arbeitsverzeichnis sieht wie folgt aus:

Beurteilung des Vorhersagemodells anhand der Kennzahlen
Der R-Quellcode liefert beim Durchlaufen die folgende Ausgabe, also die Kennzahlen zu jedem Schleifendurchlauf der Kreuzvalidierung ("m_perf"-Matrix) und die gemittelten Werte der vier Kennzahlen ("perf"-Vektor) zur Validierung des Modells:

Wie gut der Entscheidungsbaum dieser Demo zur Vorhersage eines Ausfalls geeignet ist, können wir nun anhand der vier ermittelten Kennzahlen zum Testfehler beurteilen:
- Accuracy = 72.1%
- Recall (True Positive Rate) TPR = 85.6%
- Precision = 72.5%
- AUC = 74.7
Wie in Schritt 4: Datenanalyse: Performance beschrieben, kann ein Modell als "gut" bewertet werden,
wenn die Kennzahlen nahe
an 100% liegen. Unsere Kennzahlen liegen die Kennzahlen
in einem guten Bereich und können ohne Vorbehalt zur Vorhersage eines Ausfalls für neue Merkmalskombinationen verwendet werden.
6-4 Modell verwenden
Im Schritt "Modell verwenden" des überwachten Lernens werden für neue Beobachtungen/Daten (d.h. der Wert für die Zielvariable ist nicht bekannt) mittels des zuvor trainierten Modells (hier: ein Entscheidungsbaum-Modell) Vorhersagen getätigt, dies ist im R-Skript demo3.R umgesetzt.
R-Code Vorhersage
# 4 Modell verwenden ----# Vorhersage# CSV-Datei einlesen und speicherndemo3test=read.csv2("automotive_data_test_4.csv",header = TRUE,sep = ";",dec = ".")# Erstelle Testdaten# ohne Massungsnr.testdata=demo3test[ ,c(-1)]# Vorhersagepred = predict(fit,newdata=testdata, type="class")# Füge die vorhergesagten Werte# in die Spalte Ausfall eindemo3test$Ausfall = as.vector(pred)demo3test
Erläuterung des R-Codes
Der R-Code beinhaltet das Einlesen der Testdaten mittels der "read.csv2"-Funktion
und dessen Speicherung unter dem Namen "demo3test" (Zeilen 5-7), wie schon bei den Trainingsdaten werden die Testdaten gekürzt (Löschen von 1.
Spalte/Merkmal) und dann unter dem Namen "testdata" gespeichert ("="- Symbol, Zeile 11).
Die Vorhersage für die Testdaten erfolgt durch Aufruf der "predict"-Funktion (Zeile 14, 15), an die das Modell
"fit" und die Testdaten "testdata"
übergeben werden. Die Vorhersage wird unter dem Namen "pred" gespeichert.
Der vorhergesagte Wert der Zeilvariablen wird in den Testdatensatz in der Spalte Ausfall eingefügt (Zeile 19) und der Datensatz in der
Konsole ausgegeben (Zeile 20).
Verwendete Funktionen
Die predict-Funktion erstellt eine Vorhersage.
Die predict-Funktion ist eine Funktion aus dem rpart-Paket, mit deren Hilfe ein erstelltes rpart-Objekt (object, hier: Entscheidungsbaum) zur Klassifikation für übergebene Daten (newdata) angewandt wird. Die vollständige Syntax der Funktion lautet
pred = predict(object, newdata,type = c("vector", "prob", "class", "matrix"),na.action = na.pass, ...)
Bis auf die Parameter object und data sind alle Parameter optional, d.h. pred = predict(object, newdata)
ist ein gültiger Funktionsaufruf und erstellt bei einem Entscheidungsbaum-Modell als Objekt default eine Matrix mit
Eintritts-Wahrscheinlichkeiten.
Die predict-Funktion gibt es in vielen Paketen, die zur Schätzung von Modellparametern genutzt werden, und die
Parameter der predict-Funktionen unterscheiden sich je nach Modell des Paketes voneinander. Hier wird ein
Entscheidungsbaum mit dem rpart-Paket erstellt dementsprechend sind die Rückgabetypen ("vector", "prob", "class", "matrix")
definiert. Mit type="prob" (probability, deutsch: Wahrscheinlichkeit) wird die Wahrscheinlichkeit für die Einteilung in die jeweilige Klasse
(Ausfall: JA/NEIN) vorhergesagt. Mit dem Parameter type="class" wird für neue Beobachtungen bzw. die Zeilen im
Testdatensatz eine Klassifikation in Ausfall
Ja oder Nein anhand des Entscheidungsbaums durchgeführt. Es erfolgt also in beiden Fällen eine Vorhersage für neue Messwertkombinationen.
Die Klassifikation mit dem Entscheidungsbaum
In den Testdaten ist der Wert der Variablen Ausfall nicht bekannt,

dieser wird mit Ausführung des Codes vorhergesagt:

Diese Zuordnung/Vorhersage erfolgt mittels Durchwandern des Pfades im Baum bis ein Blatt erreicht wird.
Wie in der obigen Ausgabe (gefüllte Spalte Ausfall im Testdatensatz) zu erkennen ist, führen die zweite und vierte Merkmalskombination laut Baum zu einem Ausfall (Wert/Level: "ja"), die anderen Beiden laut Modell aber nicht (Wert/Level: "nein").
Im aktuellen Arbeitsverzeichnis liegen nun alle verwendeten Datensätze, das Modell und die Vorhersage vor:

Download des Quellcodes
Hier können Sie das R-Projekt - Demo 3 herunterladen (als komprimierte zip-Datei).
YouTube-Video und weitere Predictive Maintenance-Demos
Die Abbildung der Datenanalyse mit RStudio im Rahmen des Predictive Maintenance-Prozesses wird durch ein 7-Minuten-Video
veranschaulicht.
Der Predictive Maintenance-Zyklus besteht neben dieser R-Demo noch aus den folgenden elab2go-Demos:
- Demo 2: Predictive Maintenace mit RapidMiner
- Demo 4: Interaktive PredMaintApp
- Demo-MAT4: Predictive Maintenance mit MATLAB
- Demo-PY4: Predictive Maintenance mit scikit-learn
Modell-Vergleich mit Demo 2
Die hier ermittelten Kennzahlen können auch zur Auswahl eines Vorhersagemodells aus mehreren zur Verfügung stehenden Modellen herangezogen werden.
Neben den Kennzahlen spielen bei der Entscheidung für ein Modell auch die Verständlichkeit und intuitive Interpretierbarkeit sowie die praktische Anwendbarkeit
des Modells eine Rolle.
Wir vergleichen nun die auf Basis derselben Daten erstellten Vorhersagemodelle aus dieser Demo und
Demo 2 miteinander, um uns für eines der beiden Modelle zu
entscheiden. Da es sich bei beiden Modellen um Entscheidungsbäume handelt, sind diese bezüglich Verständlichkeit und Interpretierbarkeit identisch. Der Baum aus
dieser Demo ist etwas übersichtlicher als der aus Demo 2, da der hier erstellte Baum 7 Merkmale zur Vorhersage aus den denn 22 Merkmalen auswählt statt 11 Merkmalen in Demo 2. Viele Merkmale
kommen in beiden Modellen vor (Einlasslufttemperatur, Drosselklappenstellung oder Lambdasonde42) und sind auch ähnlich von der Stellung im Baum,
dies zeigt deren hohe Relevanz bei der Vorhersage eines Ausfalls.
Da das Durchlaufen der Knoten in dieser Demo etwas kürzer als in Demo2 ist, die Pfade aber noch vergleichbar lang sind, ist die Komplexität der Modelle damit auch
ähnlich.
Tabelle der Kennzahlen zur Güte aus Demo 2 und 3 im direkten Vergleich.
| Kennzahl | Demo 3 | Demo 2 |
|---|---|---|
| Accuracy | 72.1% | 65.7% |
| Recall (True Positive Rate) | 85.6% | 69.2% |
| Precision | 72.5% | 73.8% |
| AUC | 74.7% | 69.6% |
Erläuterung der Tabelle der Kennzahlen zur Güte aus Demo 2 und 3 im direkten Vergleich:
Stellen wir die Kennzahlen der beiden Bäume gegenüber, so sind die Precision- und Accuracy-Werte der Modelle vergleichbar.
Die Accuracy, True Positive Rate und die AUC sind in Demo 3 höher als in Demo 2 und damit näher an dem Idealwert von 100%.
Betrachten wir die praktische Anwendbarkeit der Modelle, dann spielt es auch eine Rolle, welche Tools bereits im Unternehmen zur Anwendung kommen und welche Kompetenzen die Mitarbeiter im Umgang mit den zur Verfügung stehenden Tools besitzen. Damit die Bäume auch vor Ort/in der Fachabteilung zum Einsatz kommen, spielt die Auswahl des Tools (Demo 2: RapidMiner oder Demo 3: Programmiersprache R mit RStudio als Umgebung) neben den anderen Kriterien eine zusätzliche entscheidende Rolle.
Autoren, Tools und Quellen
Autoren:
M.Sc. Anke Welz
Prof. Dr. Eva Maria Kiss
Tools:
elab2go Links und weitere Demos zum Predictive Maintenance-Zyklus:
- Was ist Predictive Maintenance? (elab2go)
- Predictive Maintenance: Die Datenanalyse (elab2go)
- Predictive Maintenance: Die Performance und die Kreuzvalidierung (elab2go)
- Demo-R1: R-Tutorial (elab2go)
- Demo 2: Predictive Maintenance mit RapidMiner (elab2go)
- Demo 4: Interaktive PredMaintApp (elab2go)
- Demo-MAT4: Predictive Maintenance mit MATLAB (elab2go)
- Demo-PY4: Predictive Maintenance mit scikit-learn (elab2go)
R Links: